

Übersicht der Clustering-Typen
Lassen Sie uns vor dem Erlernen von Clustering-Typen verstehen, was Clustering ist und warum es in der Branche des maschinellen Lernens derzeit so wichtig ist.
Was ist Clustering? Clustering ist ein Prozess, bei dem der Algorithmus die Datenpunkte in eine festgelegte Anzahl von Gruppen aufteilt, basierend auf dem Prinzip, dass ähnliche Datenpunkte nahe beieinander bleiben und in dieselbe Gruppe fallen.
Warum ist es jetzt so wichtig? Lassen Sie uns verstehen, dass es zum Beispiel einen Online-Bekleidungsladen gibt, in dem die Kunden besser verstanden werden sollen, damit sie ihre Werbestrategie effektiver gestalten können. Es ist nicht möglich, dass sie für jeden Kunden eine eigene Strategie haben. Stattdessen können sie die Kunden in eine bestimmte Anzahl von Gruppen aufteilen (basierend auf ihren vorherigen Einkäufen) und eine separate Strategie für separate Gruppen festlegen. Dies macht das Geschäft effektiver. Dies ist der Grund, warum Clustering in der Branche jetzt wichtig ist.
Arten von Clustering
Allgemein werden Methoden der Clustering-Techniken in zwei Typen eingeteilt: Harte Methoden und weiche Methoden. Bei der harten Clustermethode gehört jeder Datenpunkt oder jede Beobachtung nur zu einem Cluster. Bei der Softcluster-Methode gehört jeder Datenpunkt nicht vollständig zu einem Cluster. Stattdessen kann er Mitglied mehrerer Cluster sein und eine Reihe von Zugehörigkeitskoeffizienten aufweisen, die der Wahrscheinlichkeit entsprechen, in einem bestimmten Cluster zu sein.
Derzeit werden verschiedene Arten von Clustering-Methoden verwendet. In diesem Artikel werden einige der wichtigsten Methoden beschrieben, z. B. hierarchisches Clustering, Partitionierungsclustering, Fuzzy-Clustering, dichtebasiertes Clustering und auf Verteilungsmodellen basierendes Clustering. Lassen Sie uns nun jedes dieser Beispiele anhand eines Beispiels diskutieren:
1. Clustering partitionieren
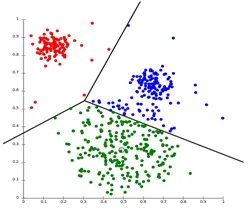
Partitionierung Clustering ist eine Art von Clustering-Technik, bei der der Datensatz in eine festgelegte Anzahl von Gruppen unterteilt wird. (Zum Beispiel, der Wert von K in KNN und es wird entschieden, bevor wir das Modell trainieren). Es kann auch als Centroid-basierte Methode bezeichnet werden. Bei diesem Ansatz wird das Clusterzentrum (Schwerpunkt) so gebildet, dass der Abstand der Datenpunkte in diesem Cluster minimal ist, wenn er mit anderen Clusterschwerpunkten berechnet wird. Ein bekanntestes Beispiel für diesen Algorithmus ist der KNN-Algorithmus. So sieht ein Partitionierungs-Clustering-Algorithmus aus
2. Hierarchisches Clustering
Hierarchisches Clustering ist eine Art von Clustering-Technik, die diesen Datensatz in eine Reihe von Clustern aufteilt, wobei der Benutzer die Anzahl der vor dem Trainieren des Modells zu generierenden Cluster nicht angibt. Diese Art der Clustering-Technik wird auch als konnektivitätsbasierte Methode bezeichnet. Bei dieser Methode wird keine einfache Partitionierung des Datensatzes vorgenommen, während die Hierarchie der Cluster angegeben wird, die nach einer bestimmten Entfernung miteinander verschmelzen. Nachdem das hierarchische Clustering für den Datensatz durchgeführt wurde, wird eine baumbasierte Darstellung der Datenpunkte (Dendogramm) angezeigt, die in Cluster unterteilt sind. So sieht ein hierarchisches Clustering nach dem Training aus
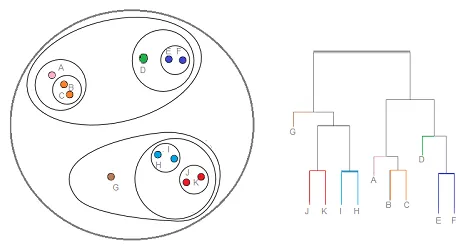
Quelllink: Hierarchisches Clustering
Beim Partitionieren von Clustern und hierarchischen Clustern können wir einen Hauptunterschied feststellen: Beim Partitionieren von Clustern geben wir im Voraus an, in wie viele Cluster der Datensatz unterteilt werden soll. Bei hierarchischen Clustern geben wir diesen Wert nicht im Voraus an .
3. Dichte-basiertes Clustering
In diesem Cluster werden Technikcluster durch Trennung verschiedener Dichtebereiche auf der Grundlage unterschiedlicher Dichten in der Datenaufzeichnung gebildet. Dichtebasierte räumliche Clusterbildung und Anwendung mit Rauschen (DBSCAN) ist der am häufigsten verwendete Algorithmus bei dieser Art von Technik. Die Hauptidee hinter diesem Algorithmus ist, dass es für jeden Punkt im Cluster eine Mindestanzahl von Punkten geben sollte, die sich in der Nachbarschaft eines bestimmten Radius befinden. Bisher können wir bei den oben diskutierten Clustering-Techniken, wenn Sie dies genau beobachten, feststellen, dass alle Techniken, bei denen es sich um die Form von Clustern handelt, entweder kugelförmig oder oval oder konkav geformt sind. DBSCAN kann Cluster in verschiedenen Formen bilden. Diese Art von Algorithmus ist am besten geeignet, wenn der Datensatz Rauschen oder Ausreißer enthält. So sieht ein dichtebasierter räumlicher Clustering-Algorithmus nach dem Training aus.
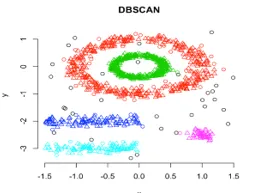
Quelllink: Dichte-basiertes Clustering
4. Verteilungsmodellbasiertes Clustering
Bei dieser Art von Clustering werden Technikcluster gebildet, indem durch die Wahrscheinlichkeit identifiziert wird, dass alle Datenpunkte im Cluster aus derselben Verteilung stammen (Normal, Gauß). Der beliebteste Algorithmus in dieser Art von Technik ist das Expectation-Maximization (EM) -Clustering unter Verwendung von Gaussian Mixture Models (GMM).
Normale Clustering-Techniken wie Hierarchical Clustering und Partitioning Clustering basieren nicht auf formalen Modellen. KNN beim Partitioning Clustering liefert unterschiedliche Ergebnisse mit unterschiedlichen K-Werten. Da KNN und KMN Mittelwerte für das Cluster-Zentrum berücksichtigen, ist dies in einigen Fällen bei Gaußschen Mischungsmodellen nicht am besten geeignet. Wir gehen davon aus, dass die Datenpunkte Gauß-verteilt sind. Auf diese Weise haben wir zwei Parameter, um die Form der Cluster-Mittelwerte und die Standardabweichung zu beschreiben. Auf diese Weise wird für jeden Cluster eine Gauß-Verteilung zugewiesen, um die optimalen Werte dieser Parameter (Mittelwert und Standardabweichung) zu erhalten. Dazu wird ein Optimierungsalgorithmus namens Expectation Maximization verwendet. So sieht EM-GMM nach dem Training aus.
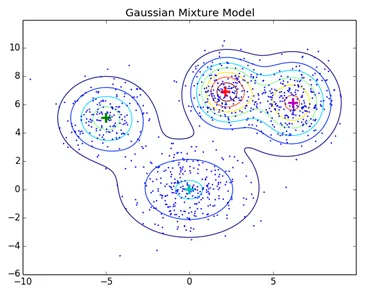
Quelllink: Verteilungsmodellbasiertes Clustering
5. Fuzzy Clustering
Gehört zu einem Zweig von Soft-Method-Clustering-Techniken, während alle oben genannten Clustering-Techniken zu Hard-Method-Clustering-Techniken gehören. Bei dieser Art der Clustering-Technik sind Punkte in der Nähe des Zentrums, möglicherweise ein Teil des anderen Clusters, in höherem Maße als Punkte am Rand desselben Clusters. Die Wahrscheinlichkeit, dass ein Punkt zu einem bestimmten Cluster gehört, liegt zwischen 0 und 1. Der beliebteste Algorithmus bei dieser Technik ist FCM (Fuzzy C-means Algorithm). Hier wird der Schwerpunkt eines Clusters als Mittelwert berechnet aller Punkte, gewichtet mit ihrer Wahrscheinlichkeit, zum Cluster zu gehören.
Schlussfolgerung - Arten der Clusterbildung
Dies sind einige der verschiedenen Clustering-Techniken, die derzeit verwendet werden. In diesem Artikel wird für jede Clustering-Technik ein beliebter Algorithmus behandelt. Wir müssen die Art der Technologie auswählen, die wir verwenden, basierend auf unserem Datensatz und den Anforderungen, die wir erfüllen müssen.
Empfohlene Artikel
Dies war ein Leitfaden für Clustering-Typen. Hier diskutieren wir verschiedene Arten von Clustering mit ihren Beispielen. Sie können sich auch die folgenden Artikel ansehen, um mehr zu erfahren -
- Hierarchischer Clustering-Algorithmus
- Clustering im maschinellen Lernen
- Arten von Algorithmen für maschinelles Lernen
- Arten von Datenanalysetechniken
- Verwenden und Entfernen von Hierarchien in Tableau
- Vollständiger Leitfaden für Arten der Datenanalyse