

Einführung in Data Mining
Dies ist eine Data Mining-Methode, mit der Datenelemente in ähnlichen Gruppen platziert werden. Cluster ist die Prozedur zum Teilen von Datenobjekten in Unterklassen. Die Qualität der Cluster hängt von der verwendeten Methode ab. Clustering wird auch als Datensegmentierung bezeichnet, da große Datengruppen durch ihre Ähnlichkeit unterteilt werden.
Was ist Clustering beim Data Mining?
Clustering ist die Gruppierung bestimmter Objekte anhand ihrer Eigenschaften und ihrer Ähnlichkeiten. Beim Data Mining werden mit dieser Methode die Daten, die für die gewünschte Analyse am besten geeignet sind, mithilfe eines speziellen Verknüpfungsalgorithmus unterteilt. Diese Analyse ermöglicht es einem Objekt, nicht Teil oder ausschließlich Teil eines Clusters zu sein, was als harte Partitionierung dieses Typs bezeichnet wird. Glatte Partitionen deuten jedoch darauf hin, dass jedes Objekt in gleichem Maße zu einem Cluster gehört. Es können spezifischere Unterteilungen wie Objekte mehrerer Cluster erstellt, ein einzelner Cluster zur Teilnahme gezwungen oder sogar hierarchische Bäume in Gruppenbeziehungen erstellt werden. Dieses Dateisystem kann auf verschiedene Arten basierend auf verschiedenen Modellen eingerichtet werden. Diese eindeutigen Algorithmen gelten für jedes Modell und unterscheiden sowohl deren Eigenschaften als auch deren Ergebnisse. Ein guter Clustering-Algorithmus kann den Cluster unabhängig von der Clusterform identifizieren. Es gibt 3 grundlegende Stufen des Clustering-Algorithmus, die nachfolgend dargestellt sind
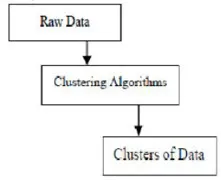
Clustering-Algorithmen im Data Mining
Abhängig von den kürzlich beschriebenen Cluster-Modellen können viele Cluster verwendet werden, um Informationen in einen Datensatz zu unterteilen. Es sollte gesagt werden, dass jede Methode ihre eigenen Vor- und Nachteile hat. Die Auswahl eines Algorithmus hängt von den Eigenschaften und der Art des Datensatzes ab.
Clustering-Methoden für Data Mining können wie folgt dargestellt werden
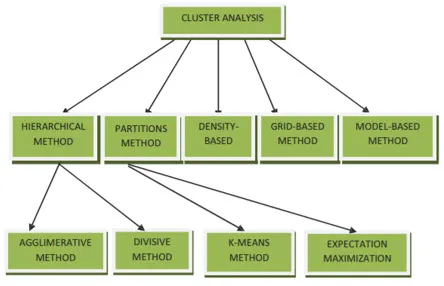
- Partitionierungsbasierte Methode
- Dichtebasierte Methode
- Centroid-basierte Methode
- Hierarchische Methode
- Gitterbasierte Methode
- Modellbasierte Methode
1. Partitionierungsbasierte Methode
Der Partitionsalgorithmus unterteilt Daten in viele Untergruppen.
Angenommen, der Partitionierungsalgorithmus erstellt eine Partition von Daten, da k und n Objekte in der Datenbank vorhanden sind. Daher wird jede Partition als k ≤ n dargestellt.
Dies gibt eine Vorstellung davon, dass die Klassifizierung der Daten in k Gruppen erfolgt, die nachfolgend gezeigt werden können
Abbildung 1 zeigt die ursprünglichen Punkte beim Clustering

Abbildung 2 zeigt das Clustering von Partitionen nach Anwendung eines Algorithmus
Dies bedeutet, dass jede Gruppe mindestens ein Objekt hat und jedes Objekt genau zu einer Gruppe gehören muss.
2. Dichtebasierte Methode
Diese Algorithmen erzeugen Cluster an einem bestimmten Ort basierend auf der hohen Dichte von Datensatzteilnehmern. Es aggregiert einige Bereichsbegriffe für Gruppenmitglieder in Clustern auf ein Dichtestandardniveau. Solche Prozesse können bei der Erkennung der Gruppenoberflächen weniger effektiv sein.
3. Centroid-basierte Methode
Nahezu jeder Cluster wird bei dieser Art der OS-Gruppierung durch einen Vektor von Werten referenziert. Im Vergleich zu anderen Clustern ist jedes Objekt Teil des Clusters mit einer minimalen Wertdifferenz. Die Anzahl der Cluster sollte vordefiniert sein, und dies ist das größte Algorithmusproblem dieses Typs. Diese Methodik ist dem Identifizierungsgegenstand am nächsten und wird häufig für Optimierungsprobleme verwendet.
4. Hierarchische Methode
Die Methode erstellt eine hierarchische Zerlegung eines bestimmten Satzes von Datenobjekten. Basierend auf der Bildung der hierarchischen Zerlegung können hierarchische Methoden klassifiziert werden. Diese Methode wird wie folgt angegeben
- Agglomerativer Ansatz
- Divisiver Ansatz
Der agglomerative Ansatz wird auch als Button-up-Ansatz bezeichnet. Hier beginnen wir mit jedem Objekt, das eine separate Gruppe bildet. Es werden weiterhin Objekte oder Gruppen nahe beieinander verschmolzen
Der divisive Ansatz wird auch als Top-Down-Ansatz bezeichnet. Wir beginnen mit allen Objekten im selben Cluster. Diese Methode ist starr, dh sie kann niemals rückgängig gemacht werden, wenn eine Fusion oder Teilung abgeschlossen ist
5. Gitterbasierte Methode
Gitterbasierte Methoden arbeiten im Objektbereich, anstatt die Daten in ein Gitter zu unterteilen. Das Raster wird basierend auf den Eigenschaften der Daten unterteilt. Mit dieser Methode können nicht numerische Daten einfach verwaltet werden. Die Datenreihenfolge wirkt sich nicht auf die Aufteilung des Rasters aus. Ein wichtiger Vorteil eines gitterbasierten Modells ist die schnellere Ausführung.
Die Vorteile des hierarchischen Clustering sind wie folgt
- Es ist auf jeden Attributtyp anwendbar.
- Es bietet Flexibilität in Bezug auf die Granularität.
6. Modellbasierte Methode
Diese Methode verwendet ein hypothetisches Modell, das auf der Wahrscheinlichkeitsverteilung basiert. Durch Clustering der Dichtefunktion lokalisiert diese Methode die Cluster. Es spiegelt die räumliche Verteilung der Datenpunkte wider.
Anwendung von Clustering in Data Mining
Clustering kann in vielen Bereichen hilfreich sein, z. B. in der Biologie, bei Pflanzen und Tieren, die nach ihren Eigenschaften klassifiziert sind, sowie im Marketing. Mithilfe von Clustering können Kunden eines bestimmten Kundendatensatzes mit ähnlichem Verhalten identifiziert werden. In vielen Anwendungen wie Marktforschung, Mustererkennung, Daten- und Bildverarbeitung wird die Clusteranalyse in großer Zahl eingesetzt. Clustering kann Werbetreibenden in ihrem Kundenstamm auch dabei helfen, verschiedene Gruppen zu finden. Und ihre Kundengruppen können durch Kaufmuster definiert werden. In der Biologie wird es zur Bestimmung von Pflanzen- und Tier-Taxonomien, zur Kategorisierung von Genen mit ähnlicher Funktionalität und zur Einsicht in populationsspezifische Strukturen verwendet. In einer Erdbeobachtungsdatenbank erleichtert das Clustering auch das Auffinden von Gebieten mit ähnlicher Nutzung im Land. Es hilft, Gruppen von Häusern und Wohnungen nach Typ, Wert und Bestimmungsort von Häusern zu identifizieren. Das Clustering von Dokumenten im Web ist auch hilfreich für die Entdeckung von Informationen. Die Clusteranalyse ist ein Tool, mit dem Sie einen Einblick in die Verteilung von Daten erhalten, um die Merkmale jedes Clusters als Data Mining-Funktion zu beobachten.
Fazit
Clustering ist wichtig für das Data Mining und dessen Analyse. In diesem Artikel haben wir gesehen, wie Clustering durch Anwenden verschiedener Clustering-Algorithmen sowie deren Anwendung im realen Leben durchgeführt werden kann.
Empfohlener Artikel
Dies war ein Leitfaden zu Clustering in Data Mining. Hier haben wir die Konzepte, Definitionen, Funktionen und die Anwendung von Clustering in Data Mining besprochen. Sie können auch unsere anderen Artikelvorschläge durchgehen, um mehr zu erfahren -
- Was ist Datenverarbeitung?
- Wie werde ich Datenanalyst?
- Was ist SQL Injection?
- Definition von SQL Server
- Überblick über die Data Mining-Architektur
- Clustering im maschinellen Lernen
- Hierarchischer Clustering-Algorithmus
- Hierarchisches Clustering | Agglomeratives & Divisives Clustering