
Einführung in die AWS Data Pipeline
Die Daten wachsen von Tag zu Tag exponentiell und sind im Vergleich zur Vergangenheit immer schwieriger zu verwalten. Wir benötigen Tools und Services, um unsere Daten effizient und kostengünstig zu verwalten. Hier kommt die AWS Data Pipeline ins Spiel. Es geht nicht nur um das Speichern von Daten, sondern Sie müssen die Daten an derselben Stelle analysieren, verarbeiten und in die gewünschte Form umwandeln. All dies kann mit AWS Data Pipeline erreicht werden.
Bedarf an Datenpipeline
Versuchen wir, die Notwendigkeit einer Datenpipeline anhand des folgenden Beispiels zu verstehen:
Beispiel 1
Wir haben eine Website, die Bilder und Gifs auf der Grundlage von Benutzersuchen oder Filtern anzeigt. Unser Hauptaugenmerk liegt auf der Bereitstellung von Inhalten. Folgende Ziele sind zu erreichen:
- Verbesserte Bereitstellung von Inhalten: Das, was Benutzer möchten, wird effizient und schnell genug bereitgestellt.
- Effizientes Verwalten der Anwendung: Speichern der Benutzerdaten sowie der Website-Protokolle für spätere Analysezwecke.
- Verbessern Sie das Geschäft: Durch die Verwendung der gespeicherten Daten und Analysen wird die Entscheidung getroffen, das Geschäft zu günstigeren Kosten zu verbessern .
Beispiel # 2
Es gibt bestimmte Engpässe, die behoben werden müssen, um die Ziele zu erreichen:
- Die enorme Datenmenge in verschiedenen Formaten und an verschiedenen Orten, die das Verarbeiten, Speichern und Migrieren von Daten zu einer komplexen Aufgabe macht.
Verschiedene Datenspeicherkomponenten für verschiedene Datentypen:
- Mögliche Echtzeitdaten für die registrierten Benutzer: Dynamo DB .
- Webserver-Protokolle für potenzielle Benutzer: Amazon S3 .
- Demografiedaten und Anmeldeinformationen: Amazon RDS.
- Sensordaten und Datensatz von Drittanbietern: Amazon S3.
Lösungen
- Machbare Lösung: Wir müssen uns mit verschiedenen Arten von Tools auseinandersetzen, um Daten für die Analyse von unstrukturiert in strukturiert umzuwandeln. Hier müssen wir verschiedene Werkzeuge verwenden, um Daten zu speichern und wieder verarbeitete Daten zu konvertieren, zu analysieren und zu speichern. Keine kostengünstige Lösung.
- Optimale Lösung: Verwenden Sie eine Datenpipeline, die die Verarbeitung, Visualisierung und Migration übernimmt. Die Datenpipeline kann bei der Migration von Daten von verschiedenen Orten hilfreich sein. Sie analysiert auch Daten und verarbeitet sie in Ihrem Auftrag am selben Ort.
Was ist die AWS-Datenpipeline?
AWS Data Pipeline ist im Grunde ein von Amazon angebotener Webservice, mit dem Sie Ihre Daten auf skalierbare und zuverlässige Weise transformieren, verarbeiten und analysieren sowie verarbeitete Daten in S3, DynamoDb oder Ihrer lokalen Datenbank speichern können.
- Mit der AWS Data Pipeline können Sie einfach auf Daten aus verschiedenen Quellen zugreifen.
- Transformieren und verarbeiten Sie diese Daten in großem Maßstab.
- Effiziente Übertragung von Ergebnissen an andere Dienste wie S3, DynamoDb-Tabelle oder lokalen Datenspeicher.
Grundsätzliches Verwendungsbeispiel der Daten-Pipeline
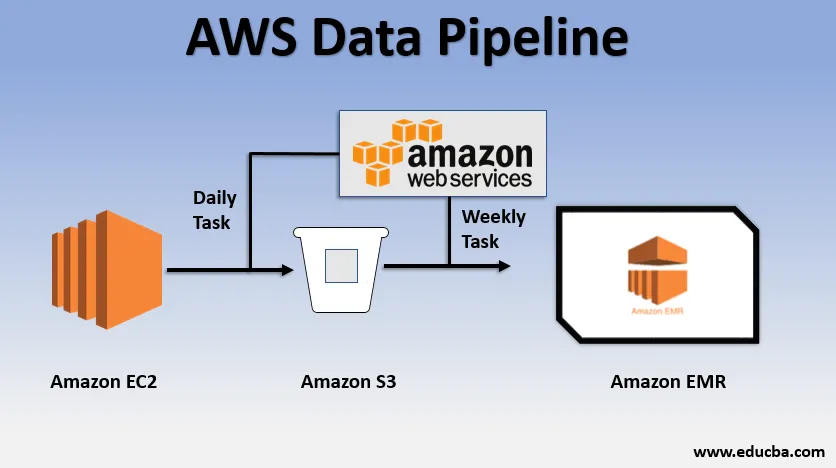
- Wir könnten eine Website über EC2 bereitstellen, die jeden Tag Protokolle erstellt.
- Eine einfache tägliche Aufgabe könnte darin bestehen, Protokolldateien von E2 zu kopieren und sie in den S3-Bucket zu übertragen.
- Eine wöchentliche Aufgabe könnte darin bestehen, die Daten zu verarbeiten und die Datenanalyse über Amazon EMR zu starten, um wöchentliche Berichte auf der Grundlage aller gesammelten Daten zu generieren.
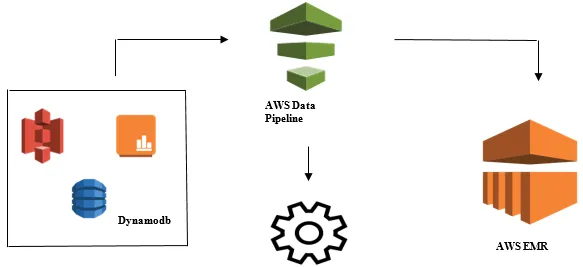
Starten der Datenanalyse mit AWS Data Pipeline
- Sammeln der Daten aus verschiedenen Datenquellen wie S3, Dynamodb, On-Premises, Sensordaten usw.
- Durchführen von Transformationen, Verarbeitungen und Analysen in AWS EMR, um wöchentliche Berichte zu generieren.
- Wöchentlicher Bericht in Redshift-, S3- oder On-Premise-Datenbank gespeichert.
Vorteile der AWS Data Pipeline
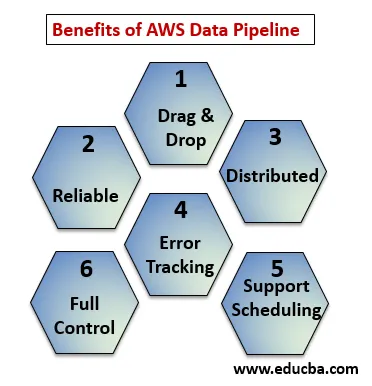
Im Folgenden werden die Vorteile der AWS Data Pipeline erläutert:
- Drag & Drop-Konsole, die einfach zu verstehen und zu verwenden ist.
- Verteilte und zuverlässige Infrastruktur: Daten-Pipelines werden auf skalierbaren Diensten ausgeführt und sind zuverlässig. Wenn ein Fehler oder eine Aufgabe fehlschlägt, kann die Wiederholung eingestellt werden.
- Unterstützt Zeitplanung und Fehlerverfolgung: Sie können Ihre Aufgaben planen und nachverfolgen, was fehlgeschlagen und erfolgreich war.
- Verteilt: Kann parallel auf mehreren Maschinen oder linear ausgeführt werden.
- Volle Kontrolle über Rechenressourcen wie EC2, EMR-Cluster.
AWS Data Pipeline-Komponenten
Nachfolgend sind die Komponenten der AWS Data Pipeline aufgeführt:
1. Pipeline-Definition
Konvertieren Sie Ihre Geschäftslogik in die AWS Data Pipeline.
- Datenknoten : Enthält den Namen, den Speicherort und das Format der Datenquelle (S3, Dynamodb, lokal)
- Aktivitäten : Verschieben, Transformieren oder Ausführen von Abfragen zu Ihren Daten.
- Zeitplan : Planen Sie Ihre täglichen oder wöchentlichen Aktivitäten.
- Voraussetzung : Bedingungen, unter denen der Scheduler die Datenverfügbarkeit an der Quelle prüfen möchte.
- Ressourcen : Berechnen Sie die Ressourcen EC2, EMR.
- Aktionen : Aktualisierung der Datenpipeline, Senden von Benachrichtigungen, Alarm auslösen.
2. Pipelines
Hier planen Sie die Aufgaben und führen sie aus, um definierte Aktivitäten auszuführen.
- Pipeline- Komponenten: Pipeline-Komponenten sind dieselben wie die Komponenten der Pipeline-Definition.
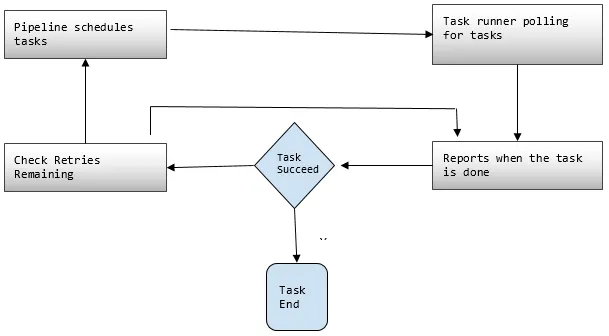
- Instanzen: Während der Ausführung von Aufgaben kompiliert AWS alle Komponenten, um bestimmte umsetzbare Instanzen zu erstellen. Solche Instanzen enthalten alle Informationen zu bestimmten Aufgaben.
- Versuche: Wir haben bereits diskutiert, wie zuverlässig die Datenpipeline mit ihren Wiederholungsmechanismen ist. Hier legen Sie fest, wie oft Sie die Aufgabe wiederholen möchten, falls sie fehlschlägt.
3. Task Runner
Fragt oder fragt nach Aufgaben aus der AWS Data Pipeline und führt diese Aufgaben dann aus.
AWS Data Pipeline-Preise
Unter den Punkten wird die Preisgestaltung für die AWS Data-Pipeline erläutert:
1. Kostenlose Stufe
Sie können im Rahmen der kostenlosen Nutzungsstufe von AWS kostenlos mit AWS Data Pipeline beginnen. Neukunden erhalten jeden Monat ein Jahr lang kostenlose Vorteile:
- 3 Voraussetzungen für die Ausführung von Niederfrequenzen auf AWS ohne Aufladung.
- 5 Aktivitäten mit niedriger Frequenz, die auf AWS kostenlos ausgeführt werden.
2. Niederfrequenz
Low Frequency soll einmal pro Tag oder weniger ausgeführt werden. Data Pipeline folgt der gleichen Abrechnungsstrategie wie andere AWS-Webservices, dh es wird Ihre Nutzung in Rechnung gestellt. Es wird abgerechnet, wie oft Ihre Aufgaben, Aktivitäten und Voraussetzungen täglich ausgeführt werden und wo sie ausgeführt werden (AWS oder lokal). Hochfrequente Aktivitäten sollen mehr als einmal am Tag ausgeführt werden.
Beispiel: Wir können eine Aktivität so planen, dass sie stündlich ausgeführt und die Website-Protokolle verarbeitet werden, oder sie kann alle 12 Stunden ausgeführt werden. Niedrigfrequente Aktivitäten sind Aktivitäten, die höchstens einmal am Tag ausgeführt werden, wenn die Voraussetzungen nicht erfüllt sind. Inaktive Pipelines haben entweder den Status INACTIVE, PENDING und FINISHED.
3. Die Preise für die AWS-Datenpipeline werden in Bezug auf die Region angezeigt
Region # 1: Ost-USA (N. Virginia), West-USA (Oregon), Asien-Pazifik (Sydney), EU (Irland)
| Hochfrequenz | Niederfrequenz | |
| Aktivitäten oder Voraussetzungen, die über AWS ausgeführt werden | $ 1.00 pro Monat | 0, 06 US-Dollar pro Monat |
| Aktivitäten oder Voraussetzungen, die vor Ort ausgeführt werden | 2, 50 USD pro Monat | 1, 50 USD pro Monat |
| Inaktive Pipelines: 1 US-Dollar pro Monat |
Region 2: Asien-Pazifik (Tokio)
| Hochfrequenz | Niederfrequenz | |
| Aktivitäten oder Voraussetzungen, die über AWS ausgeführt werden | 0, 9524 US-Dollar pro Monat | 0, 5715 US-Dollar pro Monat |
| Aktivitäten oder Voraussetzungen, die vor Ort ausgeführt werden | 2, 381 USD pro Monat | 1, 4286 US-Dollar pro Monat |
| Inaktive Pipelines: 0, 9524 USD pro Monat |
Die Pipeline, mit der ein täglicher Job, dh eine Aktivität mit niedriger Frequenz in AWS, zum Verschieben von Daten aus der DynamoDB-Tabelle nach Amazon S3 ausgeführt wird, kostet 0, 60 USD pro Monat. Wenn wir EC2 hinzufügen, um einen Bericht basierend auf Amazon S3-Daten zu erstellen, würden die Gesamtkosten für die Pipeline 1, 20 USD pro Monat betragen. Wenn wir diese Aktivität alle 6 Stunden durchführen, würde dies 2 US-Dollar pro Monat kosten, da es sich dann um eine hochfrequente Aktivität handelt.
Fazit
AWS Data Pipeline ist eine sehr praktische Lösung für die Verwaltung der exponentiell wachsenden Daten zu günstigeren Kosten. Es ist sehr zuverlässig und kann je nach Verwendung skaliert werden. AWS Data Pipeline ist eine sehr gute Wahl, um all unsere Geschäftsziele zu erreichen, wenn es um Geschäftsanforderungen mit einer hohen Datenmenge geht.
Empfohlene Artikel
Dies ist eine Anleitung zur AWS Data Pipeline. Hier werden die Anforderungen der Datenpipeline, die AWS-Datenpipeline, deren Komponenten und Preisdetails erörtert. Sie können auch unsere anderen verwandten Artikel durchgehen, um mehr zu erfahren -
- AWS EBS
- AWS-Datenbanken
- Was ist AWS EC2?
- Vorteile der Datenvisualisierung
- Top 7 Wettbewerber von AWS mit Features
- Erfahren Sie mehr über die Liste der Amazon Web Services-Funktionen