

Einführung in den AdaBoost-Algorithmus
Der AdaBoost-Algorithmus kann verwendet werden, um die Leistung jedes maschinellen Lernalgorithmus zu steigern. Maschinelles Lernen hat sich zu einem leistungsstarken Tool entwickelt, mit dem anhand einer großen Datenmenge Vorhersagen getroffen werden können. Es ist in letzter Zeit so populär geworden, dass die Anwendung von maschinellem Lernen in unseren täglichen Aktivitäten zu finden ist. Ein häufiges Beispiel dafür ist das Abrufen von Produktvorschlägen beim Online-Einkauf auf der Grundlage der vom Kunden in der Vergangenheit gekauften Artikel. Maschinelles Lernen, oft als prädiktive Analyse oder prädiktive Modellierung bezeichnet, kann als die Fähigkeit von Computern definiert werden, ohne explizite Programmierung zu lernen. Es verwendet programmierte Algorithmen zur Analyse der Eingabedaten, um die Ausgabe innerhalb eines akzeptablen Bereichs vorherzusagen.
Was ist der AdaBoost-Algorithmus?
Beim maschinellen Lernen ergab sich das Boosten aus der Frage, ob ein Satz schwacher Klassifikatoren in einen starken Klassifikator umgewandelt werden könnte. Schwacher Lernender oder Klassifikator ist ein Lernender, der besser ist als zufälliges Erraten, und dies ist robust bei Überanpassung wie bei einer großen Menge schwacher Klassifikatoren, wobei jeder schwache Klassifikator besser als zufällig ist. Als schwacher Klassifikator wird im Allgemeinen ein einfacher Schwellenwert für ein einzelnes Merkmal verwendet. Wenn das Merkmal über dem vorhergesagten Schwellenwert liegt, gehört es zum Positiven, ansonsten zum Negativen.
AdaBoost steht für 'Adaptive Boosting', das schwache Lernende oder Prädiktoren in starke Prädiktoren umwandelt, um Probleme der Klassifikation zu lösen.
Zur Klassifizierung kann die endgültige Gleichung wie folgt ausgedrückt werden: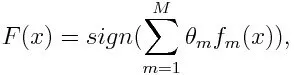
Hier bezeichnet f m den m- ten schwachen Klassifikator und m repräsentiert sein entsprechendes Gewicht.
Wie funktioniert der AdaBoost-Algorithmus?
Mit AdaBoost kann die Leistung von Algorithmen für maschinelles Lernen verbessert werden. Es wird am besten bei schwachen Lernenden verwendet, und diese Modelle erreichen eine hohe Genauigkeit bei einem Klassifizierungsproblem, die über der Zufallsrate liegt. Die gebräuchlichsten Algorithmen mit AdaBoost sind Entscheidungsbäume der ersten Ebene. Ein schwacher Lernender ist ein Klassifikator oder Prädiktor, der in Bezug auf die Genauigkeit relativ schlecht abschneidet. Es kann auch impliziert werden, dass die schwachen Lernenden einfach zu berechnen sind und viele Instanzen von Algorithmen kombiniert werden, um durch Boosten einen starken Klassifikator zu erzeugen.
Wenn wir einen Datensatz mit n Punkten nehmen, betrachten wir das Folgende
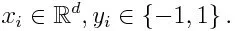
-1 steht für eine negative Klasse und 1 für eine positive. Es wird wie folgt das Gewicht für jeden Datenpunkt initialisiert:
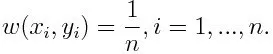
Wenn wir die Iteration von 1 nach M für m betrachten, erhalten wir den folgenden Ausdruck:
Zuerst müssen wir den schwachen Klassifikator mit dem niedrigsten gewichteten Klassifikationsfehler auswählen, indem wir die schwachen Klassifikatoren an den Datensatz anpassen.
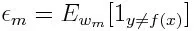
Berechnen Sie dann das Gewicht für den m- ten schwachen Klassifikator wie folgt:
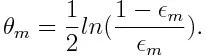
Das Gewicht ist für jeden Klassifikator mit einer Genauigkeit von mehr als 50% positiv. Das Gewicht wird größer, wenn der Klassifikator genauer ist, und es wird negativ, wenn der Klassifikator eine Genauigkeit von weniger als 50% aufweist. Die Vorhersage kann durch Invertieren des Vorzeichens kombiniert werden. Durch Invertieren des Vorzeichens der Vorhersage kann ein Klassifikator mit einer Genauigkeit von 40% in eine Genauigkeit von 60% umgewandelt werden. Somit trägt der Klassifikator zur endgültigen Vorhersage bei, obwohl er schlechter abschneidet als das zufällige Erraten. Die endgültige Vorhersage wird jedoch keinen Beitrag liefern oder Informationen vom Klassifikator mit einer Genauigkeit von genau 50% erhalten. Der exponentielle Term im Zähler ist für einen falsch klassifizierten Fall aus dem positiv gewichteten Klassifikator immer größer als 1. Nach der Iteration werden die falsch klassifizierten Fälle mit größeren Gewichten aktualisiert. Die negativ gewichteten Klassifikatoren verhalten sich genauso. Aber es gibt einen Unterschied, dass nach dem Umkehren des Vorzeichens; Die korrekte Klassifizierung würde ursprünglich zu einer Fehlklassifizierung führen. Die endgültige Vorhersage kann berechnet werden, indem jeder Klassifizierer berücksichtigt und dann die Summe seiner gewichteten Vorhersage durchgeführt wird.
Aktualisieren des Gewichts für jeden Datenpunkt wie folgt:
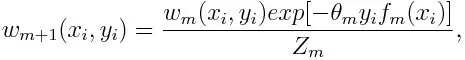
Z m ist hier der Normalisierungsfaktor. Es stellt sicher, dass die Gesamtsumme aller Instanzgewichtungen gleich 1 wird.
Wofür wird der AdaBoost-Algorithmus verwendet?
AdaBoost kann für die Gesichtserkennung verwendet werden, da es der Standardalgorithmus für die Gesichtserkennung in Bildern zu sein scheint. Es wird eine Rückweisungskaskade verwendet, die aus vielen Schichten von Klassifikatoren besteht. Wenn das Erkennungsfenster in keiner Ebene als Gesicht erkannt wird, wird es verworfen. Der erste Klassifizierer in dem Fenster verwirft das negative Fenster, wobei der Rechenaufwand auf einem Minimum gehalten wird. Obwohl AdaBoost die schwachen Klassifikatoren kombiniert, werden die Prinzipien von AdaBoost auch verwendet, um die besten Funktionen für jede Schicht der Kaskade zu finden.
Vor- und Nachteile des AdaBoost-Algorithmus
Einer der vielen Vorteile des AdaBoost-Algorithmus ist, dass er schnell, einfach und leicht zu programmieren ist. Außerdem kann es flexibel mit jedem Algorithmus für maschinelles Lernen kombiniert werden, und es besteht keine Notwendigkeit, die Parameter mit Ausnahme von T abzustimmen. Es wurde auf Lernprobleme über die binäre Klassifizierung hinaus ausgedehnt und ist vielseitig, da es mit Text oder Zahlen verwendet werden kann Daten.
AdaBoost hat auch einige Nachteile, da es empirisch belegt und besonders anfällig für gleichmäßiges Rauschen ist. Zu schwache Klassifikatoren können zu geringen Margen und Überanpassungen führen.
Beispiel für den AdaBoost-Algorithmus
Wir können ein Beispiel für die Zulassung von Studenten an einer Universität betrachten, an der sie entweder zugelassen oder abgelehnt werden. Hier finden sich die quantitativen und qualitativen Daten aus verschiedenen Gesichtspunkten. Zum Beispiel kann das Ergebnis der Zulassung, das ja / nein sein kann, quantitativ sein, wohingegen jeder andere Bereich, wie Fähigkeiten oder Hobbys von Studenten, qualitativ sein kann. Wir können leicht die richtige Klassifizierung der Trainingsdaten finden, und zwar zu einem besseren Zeitpunkt als zu einem Zeitpunkt, zu dem die Bedingungen gegeben sind, wenn der Student in einem bestimmten Fach gut ist, wird er / sie zugelassen. Aber es ist schwierig, hochgenaue Vorhersagen zu finden, und dann kommen schwache Lernende ins Spiel.
Fazit
AdaBoost hilft bei der Auswahl des Trainingssatzes für jeden neuen Klassifikator, der basierend auf den Ergebnissen des vorherigen Klassifikators trainiert wird. Auch beim Kombinieren der Ergebnisse; es bestimmt, wie viel Gewicht jeder vorgeschlagenen Antwort des Klassifikators beigemessen werden soll. Es kombiniert die schwachen Lernenden zu einem starken, um Klassifizierungsfehler zu korrigieren. Dies ist auch der erste erfolgreiche Boosting-Algorithmus für binäre Klassifizierungsprobleme.
Empfohlene Artikel
Dies war eine Anleitung zum AdaBoost-Algorithmus. Hier haben wir das Konzept, die Verwendung, die Arbeitsweise, die Vor- und Nachteile anhand eines Beispiels besprochen. Sie können auch unsere anderen Artikelvorschläge durchgehen, um mehr zu erfahren -
- Naiver Bayes-Algorithmus
- Fragen im Vorstellungsgespräch für Social Media Marketing
- Link Building-Strategien
- Social Media Marketing Plattform