

Einführung in Join in Spark SQL
Wie wir wissen, werden die Joins in SQL verwendet, um Daten oder Zeilen aus zwei oder mehr Tabellen basierend auf einem gemeinsamen Feld zu kombinieren. In diesem Thema erfahren Sie mehr über das Join in Spark SQL Join in Spark SQL.
In Spark SQL sind Dataframe oder Dataset eine speicherinterne Tabellenstruktur mit Zeilen und Spalten, die auf mehrere Knoten verteilt sind. Wie bei normalen SQL-Tabellen können wir auch Join-Operationen für in Spark SQL vorhandene Dataframes oder Datasets ausführen, die auf einem gemeinsamen Feld basieren.
In SQL stehen verschiedene Arten von Join-Operationen zur Verfügung. Abhängig vom Geschäftsanwendungsfall entscheiden wir uns für den Join-Vorgang. Im folgenden Abschnitt wird jeder Join-Typ anhand eines Beispiels veranschaulicht.
Join-Typen in Spark SQL
Im Folgenden sind die verschiedenen Arten von Joins aufgeführt, die in Spark SQL verfügbar sind:
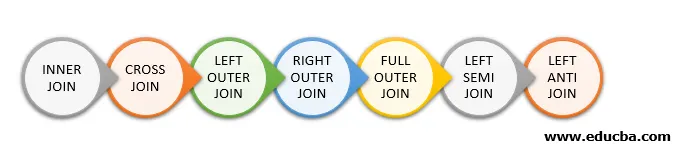
- INNER JOIN
- CROSS JOIN
- LINKE ÄUSSERE VERBINDUNG
- RICHTIG AUSSEN VERBINDEN
- KOMPLETTE AUSSENVERBINDUNG
- LINKE HALBVERBINDUNG
- LINKS ANTI JOIN
Beispiel für die Datenerstellung
Wir werden die folgenden Daten verwenden, um die verschiedenen Arten von Joins zu demonstrieren:
Buchdatensatz:
case class Book(book_name: String, cost: Int, writer_id:Int)
val bookDS = Seq(
Book("Scala", 400, 1),
Book("Spark", 500, 2),
Book("Kafka", 300, 3),
Book("Java", 350, 5)
).toDS()
bookDS.show()

Writer-Datensatz:
case class Writer(writer_name: String, writer_id:Int)
val writerDS = Seq(
Writer("Martin", 1),
Writer("Zaharia " 2),
Writer("Neha", 3),
Writer("James", 4)
).toDS()
writerDS.show()

Arten von Joins
Nachfolgend sind 7 verschiedene Arten von Joins aufgeführt:
1. INNER JOIN
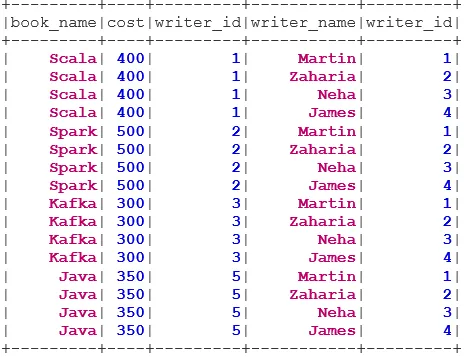
Der INNER JOIN gibt den Datensatz mit den Zeilen zurück, deren Werte in beiden Datensätzen übereinstimmen, dh der Wert des gemeinsamen Felds ist gleich.
val BookWriterInner = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "inner")
BookWriterInner.show()

2. CROSS JOIN
Der CROSS JOIN gibt den Datensatz zurück, der die Anzahl der Zeilen im ersten Datensatz multipliziert mit der Anzahl der Zeilen im zweiten Datensatz ist. Ein solches Ergebnis wird als kartesisches Produkt bezeichnet.
Voraussetzung: Für die Verwendung eines Cross-Joins muss spark.sql.crossJoin.enabled auf true gesetzt sein. Andernfalls wird die Ausnahme ausgelöst.
spark.conf.set("spark.sql.crossJoin.enabled", true)
val BookWriterCross = bookDS.join(writerDS)
BookWriterCross.show()
3. LEFT OUTER JOIN
Der Befehl LEFT OUTER JOIN gibt das Dataset mit allen Zeilen aus dem linken Dataset und den übereinstimmenden Zeilen aus dem rechten Dataset zurück.
val BookWriterLeft = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftouter")
BookWriterLeft.show()

4. RECHTS AUSSEN VERBINDEN
Der Befehl RIGHT OUTER JOIN gibt das Dataset mit allen Zeilen aus dem rechten Dataset und den übereinstimmenden Zeilen aus dem linken Dataset zurück.
val BookWriterRight = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "rightouter")
BookWriterRight.show()

5. VOLLSTÄNDIGE AUSSENVERBINDUNG
Der FULL OUTER JOIN gibt das Dataset zurück, das alle Zeilen enthält, wenn eine Übereinstimmung im linken oder rechten Dataset vorliegt.
val BookWriterFull = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "fullouter")
BookWriterFull.show()

6. LINKE HALBVERBINDUNG
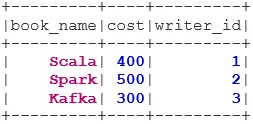
Der LEFT SEMI JOIN gibt den Datensatz zurück, der alle Zeilen des linken Datensatzes enthält, deren Entsprechung im rechten Datensatz enthalten ist. Im Gegensatz zum LEFT OUTER JOIN enthält der zurückgegebene Datensatz im LEFT SEMI JOIN nur die Spalten aus dem linken Datensatz.
val BookWriterLeftSemi = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftsemi")
BookWriterLeftSemi.show()
7. LEFT ANTI JOIN
Der ANTI SEMI JOIN gibt den Datensatz zurück, der alle Zeilen des linken Datensatzes enthält, deren Übereinstimmung nicht im rechten Datensatz enthalten ist. Es enthält auch nur die Spalten aus dem linken Datensatz.
val BookWriterLeftAnti = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftanti")
BookWriterLeftAnti.show()

Fazit - Join in Spark SQL
Das Zusammenführen von Daten ist eine der häufigsten und wichtigsten Operationen zur Erfüllung unseres Geschäftsanwendungsfalls. Spark SQL unterstützt alle grundlegenden Arten von Joins. Beim Beitritt müssen wir auch die Leistung berücksichtigen, da diese möglicherweise große Netzwerkübertragungen erfordert oder sogar Datensätze erstellt, die über unsere Fähigkeiten hinausgehen. Zur Leistungsverbesserung verwendet Spark das SQL-Optimierungsprogramm, um Filter neu anzuordnen oder nach unten zu verschieben. Funken beschränken auch die gefährliche Verbindung i. e CROSS JOIN. Für die Verwendung eines Cross-Joins muss spark.sql.crossJoin.enabled explizit auf true gesetzt werden.
Empfohlene Artikel
Dies ist eine Anleitung zum Beitreten zu Spark SQL. Hier diskutieren wir die verschiedenen Arten von Joins, die in Spark SQL verfügbar sind, anhand des Beispiels. Sie können sich auch den folgenden Artikel ansehen.
- Arten von Joins in SQL
- Tabelle in SQL
- SQL-Einfügeabfrage
- Transaktionen in SQL
- PHP Filter | Wie validiere ich Benutzereingaben mit verschiedenen Filtern?