
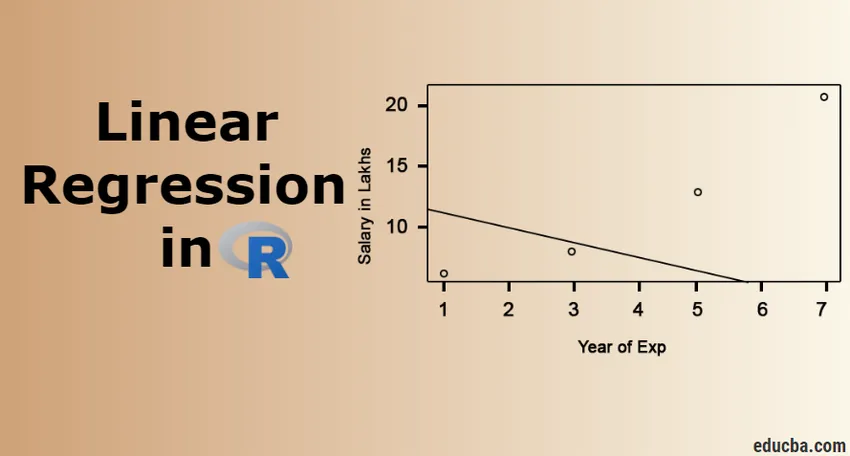
Was ist lineare Regression in R?
Die lineare Regression ist der beliebteste und am weitesten verbreitete Algorithmus im Bereich Statistik und maschinelles Lernen. Die lineare Regression ist eine Modellierungstechnik, um die Beziehung zwischen Eingabe- und Ausgabevariablen zu verstehen. Hier müssen Variablen numerisch sein. Die lineare Regression ergibt sich aus der Tatsache, dass die Ausgabevariable eine lineare Kombination von Eingabevariablen ist. Die Ausgabe wird normalerweise durch "y" dargestellt, während die Eingabe durch "x" dargestellt wird.
Die lineare Regression in R kann auf zwei Arten kategorisiert werden
-
Einfache lineare Regression
Dies ist die Regression, bei der die Ausgabevariable eine Funktion einer einzelnen Eingabevariable ist. Darstellung der einfachen linearen Regression:
y = c0 + c1 * x1
-
Multiple lineare Regression
Dies ist die Regression, bei der die Ausgabevariable eine Funktion einer Variablen mit mehreren Eingängen ist.
y = c0 + c1 * x1 + c2 * x2
In beiden obigen Fällen sind c0, c1, c2 die Koeffizienten, die die Regressionsgewichte darstellen.
Lineare Regression in R
R ist ein sehr leistungsfähiges statistisches Werkzeug. Schauen wir uns also an, wie eine lineare Regression in R durchgeführt werden kann und wie ihre Ausgabewerte interpretiert werden können.
Lassen Sie uns einen Datensatz vorbereiten, um die lineare Regression jetzt gründlich durchzuführen und zu verstehen.
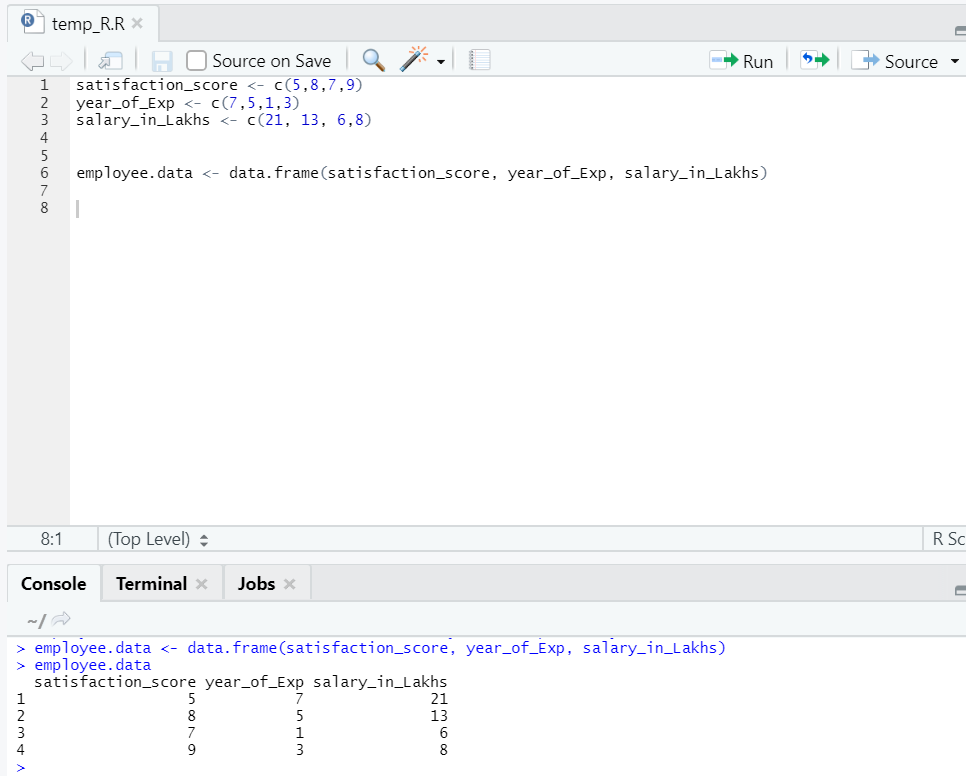
Jetzt haben wir einen Datensatz, in dem "satisfaction_score" und "year_of_Exp" die unabhängige Variable sind. "Salary_in_lakhs" ist die Ausgabevariable.
In Bezug auf den obigen Datensatz ist das Problem, das wir hier durch lineare Regression angehen möchten:
Schätzung des Gehalts eines Mitarbeiters anhand seines Erfahrungsjahres und der Zufriedenheit in seinem Unternehmen.
R Code der linearen Regression:
model <- lm(salary_in_Lakhs ~ satisfaction_score + year_of_Exp, data = employee.data)
summary(model)
Die Ausgabe des obigen Codes lautet:
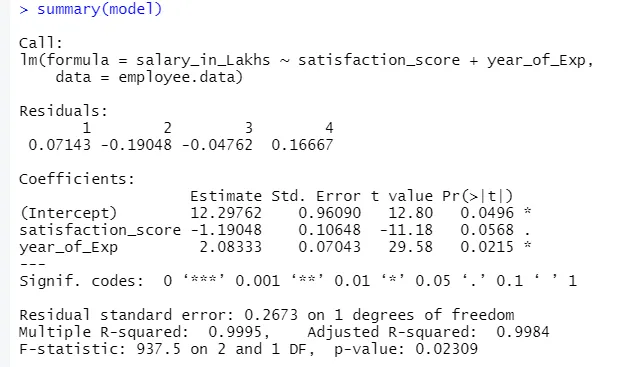
Die Formel der Regression wird
Y = 12, 29-1, 19 * Zufriedenheitswert + 2, 08 × 2 * Jahr_des_Exp
Für den Fall, man hat mehrere Eingaben in das Modell.
Dann kann R-Code sein:
model <- lm (salary_in_Lakhs ~., data = employee.data)
Wenn jedoch jemand eine Variable aus mehreren Eingabevariablen auswählen möchte, stehen mehrere Techniken zur Verfügung, wie z. B. "Rückwärtseliminierung", "Vorwärtsauswahl" usw., um dies ebenfalls zu tun.
Interpretation der linearen Regression in R
Im Folgenden sind einige Interpretationen der linearen Regression in r aufgeführt:
1.Rückstände
Dies bezieht sich auf den Unterschied zwischen der tatsächlichen Antwort und der vorhergesagten Antwort des Modells. Für jeden Punkt gibt es also eine tatsächliche und eine vorhergesagte Antwort. Daher werden Residuen genauso viele sein wie Beobachtungen. In unserem Fall haben wir vier Beobachtungen, also vier Residuen.

2.Koeffizienten
Im weiteren Verlauf finden wir den Abschnitt mit den Koeffizienten, in dem der Achsenabschnitt und die Steigung dargestellt sind. Wenn man das Gehalt eines Mitarbeiters basierend auf seiner Erfahrung und Zufriedenheit vorhersagen möchte, muss man eine Modellformel entwickeln, die auf Steigung und Schnittpunkt basiert. Diese Formel hilft Ihnen bei der Vorhersage des Gehalts. Der Schnittpunkt und die Steigung helfen dem Analysten dabei, das beste Modell zu finden, das zu Datenpunkten passt.
Steigung: Zeigt die Steilheit der Linie an.
Schnittpunkt: Die Stelle, an der die Linie die Achse schneidet.
Lassen Sie uns verstehen, wie die Formelbildung basierend auf Steigung und Achsenabschnitt erfolgt.
Angenommen, der Achsenabschnitt ist 3 und die Steigung ist 5.
Die Formel lautet also y = 3 + 5x . Dies bedeutet, wenn x um eine Einheit erhöht wird, wird y um 5 erhöht.
a.Koeffizient - Schätzung
In diesem Fall bezeichnet der Abschnitt den Durchschnittswert der Ausgangsvariablen, wenn alle Eingaben Null werden. In unserem Fall beträgt das Gehalt in Lakhs also durchschnittlich 12, 29 Lakhs, wenn man bedenkt, dass Zufriedenheit und Erfahrung gleich Null sind. Hier repräsentiert die Steigung die Änderung der Ausgangsgröße mit einer Einheitsänderung der Eingangsgröße.
b.Koeffizient - Standardfehler
Der Standardfehler ist die Fehlerabschätzung, die wir bei der Berechnung der Differenz zwischen dem tatsächlichen und dem vorhergesagten Wert unserer Antwortvariablen erhalten können. Dies gibt wiederum Auskunft über die Zuverlässigkeit der Zuordnung von Eingabe- und Ausgabevariablen.
c.Koeffizient - t Wert
Dieser Wert gibt die Sicherheit, die Nullhypothese abzulehnen. Je größer der Wert von Null entfernt ist, desto größer ist das Vertrauen, die Nullhypothese abzulehnen und die Beziehung zwischen Ausgabe- und Eingabevariable herzustellen. In unserem Fall ist der Wert auch nicht gleich Null.
d.Koeffizient - Pr (> t)
Dieses Akronym beschreibt im Wesentlichen den p-Wert. Je näher es an der Null ist, desto leichter können wir die Nullhypothese verwerfen. Die Linie, die wir in unserem Fall sehen, ist nahe Null, wir können sagen, dass es eine Beziehung zwischen Gehaltspaket, Zufriedenheitswert und Jahr der Erfahrungen gibt.

Reststandardfehler
Dies zeigt den Fehler in der Vorhersage der Antwortvariablen. Je niedriger es ist, desto höher ist die Genauigkeit des Modells.
Mehrfaches R-Quadrat, angepasstes R-Quadrat
Das R-Quadrat ist ein sehr wichtiges statistisches Maß, um zu verstehen, wie genau die Daten in das Modell eingepasst haben. In unserem Fall also, wie gut unser lineares Regressionsmodell den Datensatz repräsentiert.
Der R-Quadrat-Wert liegt immer zwischen 0 und 1. Die Formel lautet:

Je näher der Wert an 1 liegt, desto besser beschreibt das Modell die Datensätze und deren Varianz.
Wenn jedoch mehr als eine Eingangsvariable in das Bild kommt, wird der angepasste R-Quadrat-Wert bevorzugt.
F-Statistik
Es ist ein starkes Maß, um die Beziehung zwischen Eingabe- und Antwortvariable zu bestimmen. Je größer der Wert als 1 ist, desto höher ist das Vertrauen in die Beziehung zwischen Eingangs- und Ausgangsvariable.
In unserem Fall ist es „937.5“, was in Anbetracht der Datenmenge relativ größer ist. Daher wird die Ablehnung der Nullhypothese einfacher.
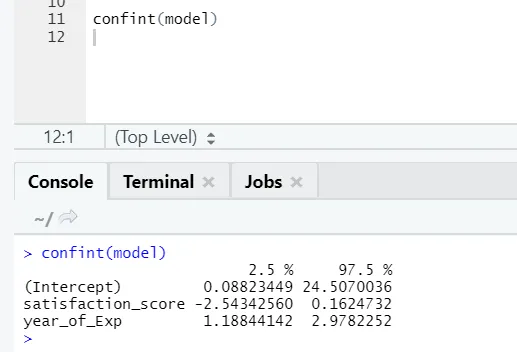
Wenn jemand das Konfidenzintervall für die Modellkoeffizienten sehen möchte, gehen Sie folgendermaßen vor:
Visualisierung der Regression
R-Code:
Plot (Gehalt_in_Lakhs ~ Zufriedenheit_Score + Jahr_des_Exp, Daten = Mitarbeiterdaten)
abline (model)
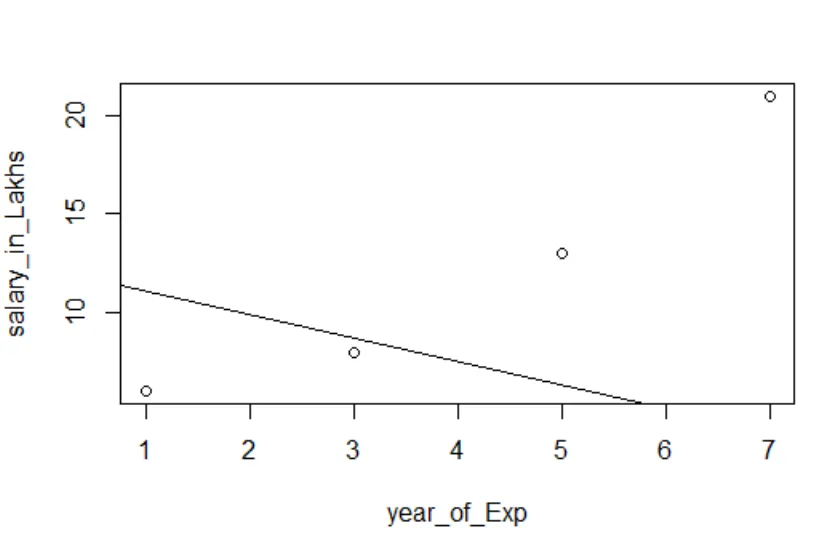
Es ist immer besser, immer mehr Punkte zu sammeln, bevor man ein Modell anpasst.
Schlussfolgerung - Lineare Regression in R
Die lineare Regression ist einfach, leicht anzupassen, leicht zu verstehen und dennoch ein sehr leistungsfähiges Modell. Wir haben gesehen, wie eine lineare Regression für R durchgeführt werden kann. Wir haben auch versucht, die Ergebnisse zu interpretieren, was Ihnen bei der Optimierung des Modells helfen kann. Sobald man sich mit der einfachen linearen Regression vertraut gemacht hat, sollte man die multiple lineare Regression ausprobieren. Da die lineare Regression empfindlich gegenüber Ausreißern ist, muss sie untersucht werden, bevor direkt in die Anpassung an die lineare Regression gesprungen wird.
Empfohlene Artikel
Dies ist eine Anleitung zur linearen Regression in R. Hier haben wir diskutiert, was lineare Regression in R ist. Kategorisierung, Visualisierung und Interpretation von R. Sie können auch unsere anderen vorgeschlagenen Artikel durchgehen, um mehr zu erfahren -
- Vorausschauende Modellierung
- Logistische Regression in R
- Entscheidungsbaum in R
- R Interviewfragen
- Die wichtigsten Unterschiede zwischen Regression und Klassifikation
- Leitfaden zum Entscheidungsbaum im maschinellen Lernen
- Lineare Regression vs Logistische Regression | Top Unterschiede