

Einführung in die Hive-Installation
Bei der Hive-Installation sollten vor der Installation einige Voraussetzungen erfüllt sein.
Hadoop-Komponenten wie Hive, Hbase, Pig usw. unterstützen alle die Linux-Umgebung. Aus diesem Grund wird empfohlen, ein Linux-Betriebssystem auf Ihrem Gerät zu installieren. Wenn dies nicht der Fall ist und Sie mit Hive üben möchten, während Windows auf Ihrem System ausgeführt wird. Sie können die CDH-Maschine auf Ihrem System installieren und sie als Plattform für die Erkundung von Hadoop verwenden. Dies erfordert mindestens 4 GB RAM auf Ihrem System oder Sie können eine CDH-Maschine in Ihrem USB-Stick haben und diese verwenden.
Auf jeden Fall können Sie immer eine Lösung für Ihre Frage haben, vielleicht früher als später.
Voraussetzungen für die Installation von Hive
Es gibt einige Voraussetzungen, um Hive auf jedem Computer zu installieren:
- Java-Installation
- Hadoop-Installation
Schritt 1
- Stellen Sie sicher, dass Java installiert ist.
- Öffnen Sie das Terminal und geben Sie den Befehl ein.
Java-Version
- Wenn Java auf dem System installiert ist, erhalten Sie die Version oder einen Fehler. In meinem Fall ist Java bereits installiert und unten ist die Ausgabe des Befehls.

- Falls Java nicht auf Ihrem System installiert ist. Sie können den folgenden Link besuchen und Java herunterladen und installieren.
- http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads- 1880260.html.
Java-Installation
- Extrahieren Sie die heruntergeladenen.
- Verschieben Sie es nach "/ usr / local /".
- Richten Sie die Variablen PATH und JAVA_HOME ein.
Schritt 2
- Stellen Sie sicher, dass Hadoop installiert ist.
- Öffnen Sie das Terminal und geben Sie den Befehl ein.
Hadoop-Version
- Wenn Hadoop bereits installiert ist, erhalten Sie mit diesem Befehl die Version oder einen Fehler.
- In meinem Fall hat Hadoop bereits die folgende Ausgabe installiert.
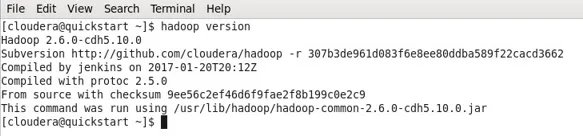
- Sie können jetzt beobachten, dass ich mit einer CDH5-Maschine arbeite.
- Wenn Hadoop nicht installiert ist, laden Sie Hadoop von der Apache-Softwarestiftung herunter.
Hadoop-Installation
1. Richten Sie Hadoop ein
2. Konfigurieren Sie Hadoop
Folgende Dateien müssen bearbeitet werden, um Hadoop zu konfigurieren:
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
3. Richten Sie Namenode mit dem folgenden Befehl ein:
Hdfs namenode -format
4. Starten Sie dfs mit dem folgenden Befehl:
start -dfs.sh
5. Starten Sie den Faden mit dem Befehl:
Start -yarn.sh
Wie installiere ich Hive?
Unterhalb der Punkte hilft die Installation von Hive:
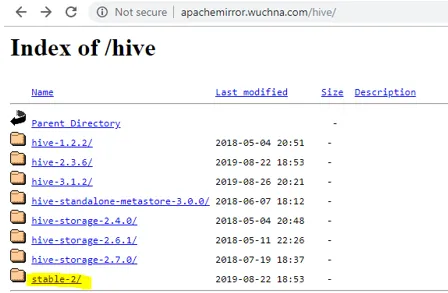
- Als Erstes müssen wir die Hive-Version herunterladen, die durch Klicken auf den folgenden Link ausgeführt werden kann: http://apachemirror.wuchna.com/hive/
- Über dem Link wird der Link angezeigt, aus dem Sie "stable-2" auswählen müssen, der unten in Gelb hervorgehoben ist:
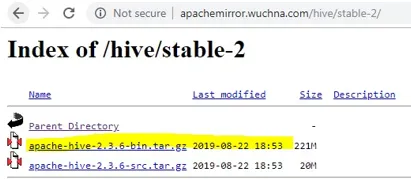
- Wählen Sie nach dem Öffnen von Stable-2 die Bin-Datei (im Screenshot gelb hervorgehoben) und klicken Sie mit der rechten Maustaste und klicken Sie auf "Link-Adresse kopieren".
Schritte zum Installieren von Hive
Im Folgenden sind die Schritte zum Installieren von Hive aufgeführt:
Schritt 1: Laden Sie die tar-Datei herunter.
http://apachemirror.wuchna.com/hive/stable-2/apache-hive-2.3.6-bin.tar.gz0
Schritt 2: Extrahieren Sie die Datei.
sudo tar zxvf /Downloads/apache-hive-* -C /usr/local
Schritt 3: Verschieben Sie Apache-Dateien in das Verzeichnis / usr / local / hive.
sudo mv /usr/local/apache-hive-* /usr/local/hive
Schritt 4: Richten Sie die Hive-Umgebung ein, indem Sie die folgenden Zeilen an die Datei ~ / .bashrc anhängen
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
export CLASSPATH=$CLASSPATH:/usr/local/Hadoop/lib/*:.
export CLASSPATH=$CLASSPATH:/usr/local/hive/lib/*:.
Schritt 5: Führen Sie die bashrc-Datei aus.
$ source ~/.bashrc
Schritt 6: Hive-Konfiguration - Bearbeiten Sie die Datei hive-env.sh, um diese anzufügen:
export HADOOP_HOME=/usr/local/Hadoop
Schritt 7: Bearbeiten Sie mit den folgenden Befehlen:
$ cd $HIVE_HOME/conf
$ cp hive-env.sh.template hive-env.sh
- Verwenden Sie nun den Befehl hive-version, um zu überprüfen, ob die Struktur installiert ist oder nicht.
- Hier betritt die Hive-Version die Hive-Shell, was bedeutet, dass der Hive installiert ist. In meinem Fall ist es jedoch die ältere Version, die die Warnung gibt.

Fazit - Hive-Installation
Hive eröffnet vielen Menschen die Möglichkeit, Big Data zu nutzen, da es sich um einfache und SQL-ähnliche Abfragesprachen und -oberflächen handelt. Hive basiert auf dem Hadoop-Kern, da Mapreduce für die Ausführung verwendet wird. Sehr einfach, die Daten abzurufen und Big Data zu verarbeiten.
Empfohlene Artikel
Dies ist eine Anleitung zur Hive-Installation. Hier werden einige Voraussetzungen für die Installation von Hive auf einem beliebigen Computer und die schrittweise Installation von Hive zum besseren Verständnis erläutert. Sie können auch unsere anderen verwandten Artikel durchgehen, um mehr zu erfahren.
- Was ist ein Bienenstock?
- Hive-Befehle
- So installieren Sie Hive
- Was ist schwein