

Einführung in XPath
XPath ist eine Haupt- und Kernkomponente des XSLT-Standards. Mit XPath können Elemente, Attribute, Text, Verarbeitungsanweisungen, Kommentare, Namespaces und Dokumente in einem XML-Dokument (Extensible Markup Language) durchsucht werden. Es ist eine W3C-Empfehlung, die eine Bibliothek mit über 200 integrierten Funktionen enthält. XPath ist die Syntax zum Definieren von Teilen eines XML-Dokuments. XSLT ist die Stylesheet-Sprache für XML-Dateien. Mit XSLT können Sie XML-Dokumente in andere Formate wie XHTML umwandeln. Bei XQuery geht es um das Abfragen von XML-Daten. XQuery dient zum Abfragen aller Elemente, die als XML angezeigt werden können, einschließlich Datenbanken. Das Verknüpfen in XML besteht aus zwei Teilen: XLink und XPointer. XLink und XPointer definieren eine Standardmethode zum Erstellen von Hyperlinks in XML-Dokumenten.
Ausdruck von XPath
Mit XPath können verschiedene Arten von Ausdrücken relevante Informationen aus dem XML-Dokument abrufen. XPath adressiert einen bestimmten Teil des Dokuments. Es modelliert ein XML-Dokument als einen Baum von Knoten. Ein Ausdruck von XPath ist eine Technik zum Navigieren und Auswählen von Knoten im Dokument.
XPath-Ausdrücke können in C, C ++, Python, Java, JavaScript, PHP, XML Schema und vielen anderen Sprachen verwendet werden. Ein XPath-Ausdruck bezieht sich auf ein Muster zum Auswählen einer Gruppe von Knoten. XPointer verwendet diese Muster zur Adressierung oder zur Durchführung von Transformationen durch XSLT. Der XPath-Ausdruck gibt sieben Knotentypen an, die das Ergebnis der Ausführung sein können.
1. Root
Stammelement eines XML-Dokuments. Mit den folgenden Methoden können Stammelemente gefunden werden.
- Platzhalter (/ *) verwenden: Zum Auswählen des Stammknotens
- Use Name (/ class): Zum Auswählen des Stammknotens nach Namen
- Name mit einem Platzhalter (/ class / *) verwenden: Zum Auswählen aller Elemente unter dem Stammknoten
Code:
2. Element
Elementknoten eines XML-Dokuments. Nachfolgend finden Sie die Möglichkeiten, um ein Element zu finden
- / class / *: Dient zum Auswählen aller Elemente unter dem Stammknoten.
- / class / library: Dient zum Auswählen aller Bibliothekselemente aus dem Stammknoten.
- // library: Dient zum Auswählen des gesamten Bibliothekselements aus dem Dokument.
Code:
3. Attribute
Ein Attribut eines Elementknotens im XML-Dokument, das mithilfe des @ -Attributnamens eines Elements abgerufen und überprüft wird.
Code:
4. Text
Text eines Elementknotens im XML-Dokument, der anhand des Namens eines Elements abgerufen und überprüft wird.
Code:
5. Kommentar
Beispiel für einen Kommentar
Code:
Knoten oder Liste des Knotens aus XML
Im Folgenden finden Sie eine Liste nützlicher Ausdrücke zum Auswählen eines Knotens oder einer Liste des Knotens aus einem XML-Dokument.
- '/': Mit dieser Auswahl beginnen Sie am Wurzelknoten.
- '//': Die Verwendung dieser Auswahl beginnt mit dem aktuellen Knoten, der der Auswahl entspricht
- '.': Auswahl des aktuell verwendeten Ausdrucks.
- '..': Auswahl des übergeordneten Knotens des aktuellen Knotens.
- '@': Um Attribute auszuwählen.
Beispiel für XPath
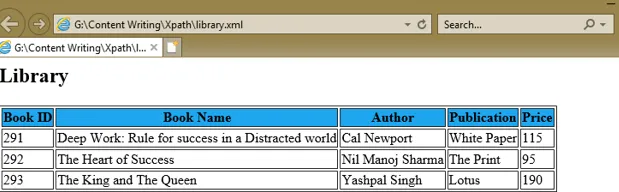
Um einen XPath-Ausdruck zu verstehen, haben wir ein XML-Dokument, library.xml, und sein Stylesheet library.xsl erstellt, das die XPath-Ausdrücke unter dem select-Attribut verschiedener XSL-Tags verwendet, um die Werte für Buch-ID, Buchname, Autor, Veröffentlichung und Preis jedes Buchknotens.
1. library.xml
Code:
Deep Work: Rule for success in a Distracted world
Cal Newport
White Paper
115
The Heart of Success
Nil Manoj Sharma
The Print
95
The King and The Queen
Yashpal Singh
Lotus
190
2. library.xsl
Code:
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
| | | | |
|---|---|---|---|---|
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
Ausgabe:
Vorteile von XPath
Nachfolgend sind die Vorteile von Xpath aufgeführt:
- XPath-Abfragen sind einfach zu schreiben und zu lesen sowie kompakt.
- Die XPath-Syntax ist für die gängigen und einfachen Fälle einfach.
- Die Abfragezeichenfolgen können problemlos in Skripts, Programme und HTML- oder XML-Attribute eingebettet werden.
- Die XPath-Abfragen lassen sich leicht analysieren.
- Jeder Knoten kann in einem XML-Dokument eindeutig erkennen.
- In einem XML-Dokument kann das Auftreten eines beliebigen Pfads oder eines beliebigen Satzes von Bedingungen für die Knoten im Pfad angegeben werden.
- Abfragen geben eine beliebige Anzahl von Ergebnissen zurück, einschließlich Null.
- In einem XML-Dokument können Abfragebedingungen auf jeder Ebene berechnet werden und dürfen nicht vom obersten Knoten eines XML-Dokuments aus durchlaufen werden.
- Die XPath-Abfragen geben eindeutige Knoten zurück, keine wiederholten Knoten.
- In vielen Kontexten wird XPath verwendet, um Links zu Knoten bereitzustellen, um Repositorys und viele andere Anwendungen zu finden.
- Für die Programmierer sind XPath-Abfragen nicht prozedural, sondern deklarativer. Sie definieren, wie Elemente durchlaufen werden sollen. Um effiziente Ergebnisse zu erzielen, müssen Indizes und andere Strukturen von einem Abfrageoptimierer kostenlos verwendet werden.
Fazit
XPath ist eine Abfragesprache, mit der Elemente, Attribute und Text in einem XML-Dokument durchsucht werden. XPath wird häufig verwendet, um bestimmte Elemente oder Attribute mit übereinstimmenden Mustern zu finden. Wenn eine Abfrage definiert ist, können diese XML-Daten als Baum dargestellt werden. Die hierarchische Darstellung von XML-Daten wird als Baum bezeichnet. Die Spitze des Baums ist ein Wurzelknoten. In einem Baum entspricht jedes Attribut, jedes Element, jeder Text, jeder Kommentar, jede Zeichenfolge und jede Verarbeitungsanweisung einem Knoten. Die Beziehungen zwischen den Knoten können durch den Baum dargestellt werden.
Empfohlene Artikel
Dies ist eine Anleitung zu Was ist XPath ?. Hier diskutieren wir Ausdruck, Liste, Beispiele und Vorteile von Xpath. Sie können auch unsere anderen verwandten Artikel durchgehen, um mehr zu erfahren.
- Was ist XPath in Selen?
- Was ist XML?
- Neuer Karriereweg
- Informationssicherheit Karriereweg
- Beispiele für integrierte Python-Funktionen