

Unterschied zwischen Big Data und Apache Hadoop
Alles ist im Internet. Das Internet hat viele Daten. Daher ist alles Big Data. Wissen Sie, dass täglich 2, 5 Billionen Bytes Daten erstellt werden und sich als Big Data häufen? Unsere täglichen Aktivitäten wie Kommentieren, Likes, Posts usw. in sozialen Medien wie Facebook, LinkedIn, Twitter und Instagram werden zu Big Data. Es wird davon ausgegangen, dass bis zum Jahr 2020 pro Sekunde fast 1, 7 Megabyte Daten für jeden Menschen auf der Erde erstellt werden. Sie können sich vorstellen und überlegen, wie viele Daten von jedem einzelnen Menschen auf der Erde erzeugt werden. Heute sind wir verbunden und teilen unser Leben online. Die meisten von uns sind online verbunden. Wir leben in einem intelligenten Zuhause und nutzen intelligente Fahrzeuge. Alle sind mit unseren Smartphones verbunden. Stellen Sie sich jemals vor, wie diese Geräte intelligent werden? Ich möchte Ihnen eine sehr einfache Antwort geben, die auf die Analyse der sehr großen Datenmenge, dh Big Data, zurückzuführen ist. Innerhalb von fünf Jahren wird es weltweit über 50 Milliarden Smart Connected Devices geben, die alle entwickelt wurden, um Daten zu sammeln, zu analysieren und auszutauschen, um unser Leben angenehmer zu gestalten.
Das Folgende sind die Einführungen von Big Data gegen Apache Hadoop
Einführung in den Begriff Big Data
Was ist Big Data? Welche Datenmenge gilt als groß und wird als Big Data bezeichnet? Wir haben viele relative Annahmen für den Begriff Big Data. Es ist möglich, dass die Datenmenge von 50 Terabyte als Big Data für Start-ups angesehen werden kann, für Unternehmen wie Google und Facebook jedoch möglicherweise nicht als Big Data. Dies liegt daran, dass sie über die Infrastruktur verfügen, um diese Datenmenge zu speichern und zu verarbeiten. Ich möchte den Begriff Big Data wie folgt definieren:
- Big Data ist die Datenmenge, die über die Fähigkeit der Technologie hinausgeht, effizient zu speichern, zu verwalten und zu verarbeiten.
- Big Data sind Daten, deren Umfang, Vielfalt und Komplexität neue Architekturen, Techniken, Algorithmen und Analysen erfordern, um sie zu verwalten und daraus Werte und verborgenes Wissen zu gewinnen.
- Bei Big Data handelt es sich um hochvolumige, schnelle und vielfältige Informationsressourcen, die kostengünstige, innovative Formen der Informationsverarbeitung erfordern, die eine verbesserte Einsicht, Entscheidungsfindung und Prozessautomatisierung ermöglichen.
- Big Data bezieht sich auf Technologien und Initiativen, bei denen es sich um Daten handelt, die zu vielfältig sind, sich schnell ändern oder zu umfangreich sind, als dass herkömmliche Technologien, Fähigkeiten und Infrastrukturen sie effizient angehen könnten. Anders gesagt, das Volumen, die Geschwindigkeit oder die Vielfalt der Daten ist zu groß.
3 V's von Big Data
- Volumen: Volumen bezieht sich auf die Menge / Menge, mit der Daten wie jede Stunde erstellt werden. Die Transaktionen von Wal-Mart-Kunden stellen dem Unternehmen etwa 2, 5 Petabyte an Daten zur Verfügung.
- Geschwindigkeit: Unter Geschwindigkeit versteht man die Geschwindigkeit, mit der sich Daten bewegen, wie Facebook-Nutzer durchschnittlich 31, 25 Millionen Nachrichten senden und 2, 77 Millionen Videos pro Minute an jedem einzelnen Tag über das Internet ansehen.
- Vielfalt: Vielfalt bezieht sich auf verschiedene Datenformate, die wie strukturierte, halbstrukturierte und unstrukturierte Daten erstellt werden. Ebenso wie das Senden von E-Mails mit dem Anhang über Google Mail sind unstrukturierte Daten, während das Posten von Kommentaren mit einigen externen Links auch als unstrukturierte Daten bezeichnet wird. Das Weitergeben von Bildern, Audioclips und Videoclips ist eine unstrukturierte Form von Daten.
Das Speichern und Verarbeiten dieses riesigen Volumens, der Geschwindigkeit und der Vielzahl von Daten ist ein großes Problem. Wir müssen an andere Technologien als RDBMS für Big Data denken. Dies liegt daran, dass RDBMS nur strukturierte Daten speichern und verarbeiten kann. Hier kommt Apache Hadoop als Rettung.
Einführung in den Begriff Apache Hadoop
Apache Hadoop ist ein Open-Source-Software-Framework zum Speichern von Daten und Ausführen von Anwendungen auf Clustern von Standardhardware. Apache Hadoop ist ein Software-Framework, das die verteilte Verarbeitung großer Datenmengen über Cluster von Computern mit einfachen Programmiermodellen ermöglicht. Es wurde für die Skalierung von einzelnen Servern auf Tausende von Computern entwickelt, die jeweils lokale Berechnungen und Speicher bieten. Apache Hadoop ist ein Framework zum Speichern und Verarbeiten von Big Data. Apache Hadoop ist in der Lage, alle Datenformate wie strukturierte, halbstrukturierte und unstrukturierte Daten zu speichern und zu verarbeiten. Apache Hadoop ist Open Source und Commodity-Hardware, die der IT-Branche eine Revolution beschert hat. Es ist für alle Unternehmensebenen leicht zugänglich. Sie müssen nicht mehr investieren, um einen Hadoop-Cluster und eine andere Infrastruktur einzurichten. Lassen Sie uns in diesem Beitrag den nützlichen Unterschied zwischen Big Data und Apache Hadoop im Detail sehen.
Apache Hadoop-Framework
Das Apache Hadoop-Framework besteht aus zwei Teilen:
- Hadoop Distributed File System (HDFS): Diese Ebene ist für die Speicherung der Daten verantwortlich.
- MapReduce: Dieser Layer ist für die Verarbeitung von Daten in Hadoop Cluster verantwortlich.
Hadoop Framework ist in Master- und Slave-Architektur unterteilt. Der Name des Hadoop-HDFS-Layers (Distributed File System) ist die Masterkomponente, während der Datenknoten die Slave-Komponente ist, während der Job Tracker in der MapReduce-Ebene die Masterkomponente und der Task Tracker die Slave-Komponente ist. Unten sehen Sie das Diagramm für das Apache Hadoop-Framework.
Warum ist Apache Hadoop wichtig?
- Schnelle Speicherung und Verarbeitung großer Datenmengen
- Rechenleistung: Das verteilte Rechenmodell von Hadoop verarbeitet Big Data schnell. Je mehr Rechenknoten Sie verwenden, desto mehr Rechenleistung steht Ihnen zur Verfügung.
- Fehlertoleranz: Daten- und Anwendungsverarbeitung sind gegen Hardwareausfall geschützt. Wenn ein Knoten ausfällt, werden Jobs automatisch an andere Knoten umgeleitet, um sicherzustellen, dass die verteilte Datenverarbeitung nicht fehlschlägt. Mehrere Kopien aller Daten werden automatisch gespeichert.
- Flexibilität: Sie können so viele Daten speichern, wie Sie möchten, und später entscheiden, wie Sie sie verwenden möchten. Dazu gehören unstrukturierte Daten wie Texte, Bilder und Videos.
- Geringe Kosten: Das Open-Source-Framework ist kostenlos und verwendet Standardhardware zum Speichern großer Datenmengen.
- Skalierbarkeit: Sie können Ihr System problemlos erweitern, um mehr Daten zu verarbeiten, indem Sie einfach Knoten hinzufügen. Es ist nur wenig Verwaltung erforderlich
Head to Head Vergleich zwischen Big Data und Apache Hadoop (Infografik)
Unten ist der Top 4 Vergleich zwischen Big Data und Apache Hadoop
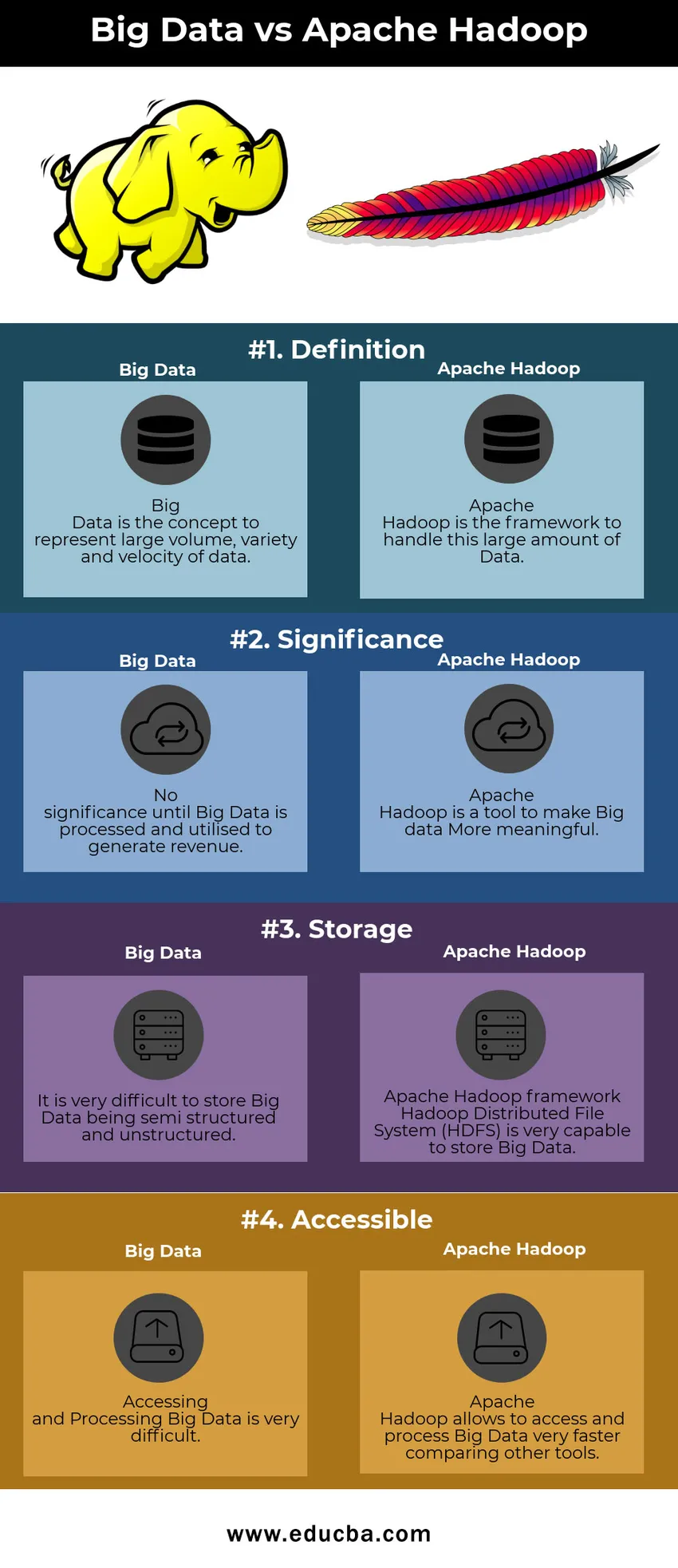
Big Data vs Apache Hadoop Vergleichstabelle
Ich diskutiere wichtige Artefakte und unterscheide zwischen Big Data und Apache Hadoop
| Große Daten | Apache Hadoop | |
| Definition | Big Data ist das Konzept zur Darstellung großer Datenmengen, -vielfalt und -geschwindigkeit | Apache Hadoop ist das Framework, um diese große Datenmenge zu verarbeiten |
| Bedeutung | Keine Bedeutung, bis Big Data verarbeitet und zur Erzielung von Einnahmen genutzt wird | Apache Hadoop ist ein Tool, um Big Data aussagekräftiger zu machen |
| Lager | Es ist sehr schwierig, Big Data halbstrukturiert und unstrukturiert zu speichern | Apache Hadoop Framework Das Hadoop Distributed File System (HDFS) ist sehr gut in der Lage, Big Data zu speichern |
| Zugänglich | Der Zugriff auf und die Verarbeitung von Big Data ist sehr schwierig | Mit Apache Hadoop können Sie im Vergleich zu anderen Tools schneller auf Big Data zugreifen und diese verarbeiten |
Fazit - Big Data gegen Apache Hadoop
Sie können Big Data und Apache Hadoop nicht vergleichen. Dies liegt daran, dass Big Data ein Problem darstellt, während Apache Hadoop Solution ist. Da die Datenmenge in allen Sektoren exponentiell zunimmt, ist es sehr schwierig, Daten von einem einzigen System zu speichern und zu verarbeiten. Um diese große Datenmenge verarbeiten zu können, müssen Daten verteilt verarbeitet und gespeichert werden. Deshalb hat Apache Hadoop die Lösung gefunden, eine sehr große Datenmenge zu speichern und zu verarbeiten. Abschließend möchte ich feststellen, dass Big Data eine große Menge komplexer Daten ist, während Apache Hadoop ein Mechanismus ist, mit dem Big Data sehr effizient und reibungslos gespeichert und verarbeitet werden kann.
Empfohlener Artikel
Dies war eine Anleitung zu Big Data und Apache Hadoop, deren Bedeutung, Kopf-an-Kopf-Vergleich, Hauptunterschiede, Vergleichstabelle und Schlussfolgerung. Dieser Artikel enthält alle nützlichen Unterschiede zwischen Big Data und Apache Hadoop. Sie können sich auch die folgenden Artikel ansehen, um mehr zu erfahren -
- Big Data vs Data Science - Wie unterscheiden sie sich?
- Top 5 Big Data-Trends, die Unternehmen meistern müssen
- Hadoop vs Apache Spark - Interessante Dinge, die Sie wissen müssen
- Apache Hadoop gegen Apache Spark | Top 10 Vergleiche, die Sie kennen müssen!