

Einführung in das Hashing in DBMS
Wenn wir über die riesige Datenbankstruktur und ihre Komplexität sprechen, wird es sehr ineffizient, nach allen Indizes zu suchen, und das Erreichen gewünschter Daten wird sehr vage und eine komplexe Möglichkeit. Unter Verwendung der Hash-Technik können diese Zustände erreicht werden, und es kann ein direkter Zeiger zugewiesen werden, um die genaue und direkte Position auf der Platte für den bestimmten Datensatz zu kennen, ohne die komplexe Indexstruktur zu verwenden. Die Daten im Falle der Hash-Technik werden in Form von Datenblöcken gespeichert, deren Adresse unter Verwendung der Funktion erzeugt wird, die typischerweise als Hash-Funktion bekannt ist. Der Ort im Speicher, an dem sich diese befinden und Aufzeichnungen gespeichert sind, wird als Datenblock oder Datenbucket bezeichnet.
Arten von Hashing in DBMS
In DBMS gibt es normalerweise zwei Arten von Hashing-Techniken:
1. Statisches Hashing
2. Dynamisches Hashing
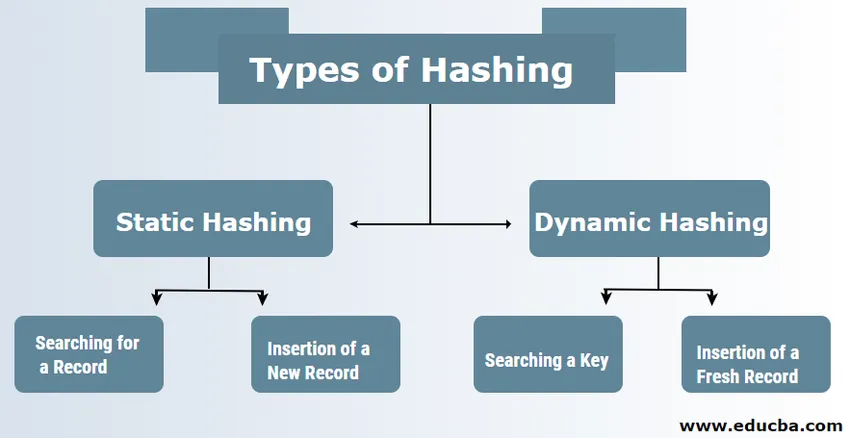
1) Statisches Hashing
Bei statischem Hashing sind der gebildete Datensatz und die Bucket-Adresse identisch. Das bedeutet, wenn wir versuchen, die Adresse für USER_ID = 113 unter Verwendung des Hash-Funktionsmoduls 5 zu generieren, erhalten wir immer das Ergebnis 3 mit der gleichen Bucket-Adresse. In diesem Fall ändert sich die Adresse des angegebenen Eimers nicht. Daher bleibt die Anzahl der Schaufeln während des gesamten Vorgangs konstant.
Operation von statisch typisiertem Hashing
ein. Nach einem Datensatz suchen: Wenn der Datensatz gefunden werden muss, wird dieselbe Hash-Funktion verwendet, um die Adresse und den Pfad des Datenkorbs mit den gespeicherten Daten abzurufen.
b. Einfügen eines neuen Datensatzes: Wenn ein neuer und neuer Datensatz in eine Tabelle eingefügt wird, wird basierend auf dem Hashing-Schlüssel eine Adresse für einen neuen Datensatz generiert, wodurch der Datensatz an diesem Speicherort gespeichert wird.
- Löschen des Datensatzes: Damit der Datensatz gelöscht werden kann, muss zunächst der Datensatz abgerufen werden, der gelöscht werden kann. Sobald diese Aufgabe erledigt ist, müssen die Datensätze für diese Speicheradresse gelöscht werden.
- Aktualisierung eines Datensatzes: Um den Datensatz zu aktualisieren, durchsuchen wir zunächst den Datensatz mithilfe der Hash-basierten Funktion. Ist dies geschehen, befindet sich unser Datensatz in einem aktualisierten Zustand. Damit wir einen neuen Datensatz in die Datei einfügen können und die Adresse, die aus der Hash-basierten Funktion und dem Daten-Bucket generiert wird, nicht leer ist oder wenn die Daten bereits in der angegebenen Adresse vorhanden sind. Diese Situation, die insbesondere bei statischem Hashing auftritt, kann besser als Bucket-Überlauf bezeichnet werden. Daher gibt es einige Möglichkeiten, um dieses Problem zu lösen:
(i) Open Hashing: Wenn eine Hashing-Funktion die Adresse generiert, für die die Daten bereits im gespeicherten Zustand angezeigt werden, wird in diesem Fall automatisch die nächste Ebene des Buckets zugewiesen. Dieser Mechanismus kann als lineare Sondiertechnik bezeichnet werden.
Wenn beispielsweise R3 die neue Adresse ist, die eingegeben werden muss, generiert die Hash-basierte Funktion die Adresse als Nummer 102 für die R3-Adresse. Die erzeugte Adresse ist im vollen Zustand, und daher soll das System nach dem neuen Datenbehälter suchen, der 113 ist, und diesem Datenbehälter R3 zuweisen.
(ii) Closed Hashing: Wenn die Buckets vollständig gefüllt sind, wird ein neuer Bucket für ein bestimmtes Hash-Ergebnis zugewiesen, das direkt nach dem zuvor abgeschlossenen verknüpft wird. Daher wird diese Methode als Overflow-Verkettungstechnik bezeichnet.
Beispielsweise ist R3 die neue Adresse, die in die neue Tabelle eingefügt werden muss. Die Hashing-Funktion wird verwendet, um die Adresse als Nummer 110 für diese zu generieren. Dieser Bucket ist wiederum voll und kann daher keine neuen Daten empfangen. Daher wird ein neuer Bucket nach 100 am Ende abgelegt.
2) Dynamisches Hashing
Diese Art von Hash-basierter Methode kann verwendet werden, um die grundlegenden Probleme von statischem Hashing zu lösen, wie z. B. den Bucket-Überlauf, da die Daten-Buckets mit der Größe wachsen und schrumpfen können. Dies ist eine platzoptimierte Technik und wird daher als erweiterbar bezeichnet Hash-basierte Methode. Bei dieser Methode wird das Hashing dynamisch gemacht, was bedeutet, dass die Einfüge- oder Löschaktivität zulässig ist, ohne dass die Leistung beeinträchtigt wird.
ein. Suche nach einem Schlüssel: Berechnen Sie die Hash-basierte Adresse des erforderlichen Schlüssels und überprüfen Sie die Anzahl der Bits, die im Fall eines Verzeichnisses mit der Bezeichnung i verwendet werden. Dann werden die niedrigstwertigen der I-Bits aus dem Verzeichnis entnommen, das eine Vorstellung über den Index aus dem Verzeichnis gibt. Suchen Sie unter Verwendung dieses Indexwerts im Verzeichnis die Bucket-Adresse, um nach den aktuellen Datensätzen zu suchen.
b. Einfügen eines neuen Datensatzes: Zuerst müssen Sie genau dasselbe Abrufverfahren ausführen, das irgendwo im Bucket enden muss. Suchen Sie nach dem Platz in diesem Eimer und legen Sie die Aufzeichnungen hinein. Wenn der erstellte Bucket vollständig und voll ist, wird der Bucket aufgeteilt und die Datensätze werden neu verteilt.
Zum Beispiel sind die letzten beiden Bits der Ziffern 2 und 4 00. Sie werden also in den Bucket B0 verschoben und so weiter entsprechend der Modulfunktion. Der Schlüssel 9 hat die Adresse 10001, die im ersten Bucket vorhanden sein muss, aber aufgeteilt wird und in den neuen Bucket B1 verschoben wird. Dies wird fortgesetzt, bis alle Buckets und Schlüssel dynamisch gehasht wurden. Die Hash-Funktion wird so verwendet, dass mit der Hash-Funktion die Spalte und ihr Wert zum Generieren der Adresse ausgewählt werden. Maximale Zeiten, in denen die Hash-Funktion den Primärschlüssel verwendet, der wiederum zum Generieren der Adressen des Datenblocks verwendet wird. Es ist eine einfache mathematische Funktion, bei der der Primärschlüssel auch als Datenblockadresse betrachtet werden kann. Das bedeutet, dass jede Zeile mit der gleichen Adresse wie die des Primärschlüssels im Datenblock gespeichert wird.
Empfohlene Artikel
Dies ist eine Anleitung zum Hashing in DBMS. Hier diskutieren wir die Einführung und die verschiedenen Arten von Hashing in DBMS, einschließlich eines statischen Hashings und eines dynamischen Hashings, zusammen mit Beispielen. Sie können sich auch die folgenden Artikel ansehen, um mehr zu erfahren -
- Datenmodelle im DBMS
- Vorteile von DBMS
- Datenintegrations-Tool
- Was ist RDBMS?