
Unterschiede zwischen HashMap und TreeMap
HashMap ist Teil von Javas Sammlung. Es bietet die grundlegende Implementierung des Java Map Interface. Die Daten werden paarweise (Schlüssel, Wert) gespeichert. Sie müssen den Schlüssel kennen, um auf einen Wert zugreifen zu können. HashMap wird als HashMap bezeichnet, da die Hashing-Technik verwendet wird. TreeMap wird verwendet, um das Map Interface und NavigableMap mit der Abstract-Klasse zu implementieren. Die Karte wird nach der natürlichen Reihenfolge ihrer Schlüssel oder nach dem Komparator sortiert, der zum Zeitpunkt der Erstellung der Karte bereitgestellt wurde, je nachdem, welcher Konstruktor verwendet wird.
Ähnlichkeiten zwischen HashMap und TreeMap
Abgesehen von den Unterschieden gibt es folgende Ähnlichkeiten zwischen Hashmap und Treemap:
- Sowohl die HashMap- als auch die TreeMap-Klasse implementieren serialisierbare und klonbare Schnittstellen.
- Sowohl HashMap als auch TreeMap erweitern die AbstractMap-Klasse.
- Sowohl die HashMap- als auch die TreeMap-Klasse verarbeiten Schlüssel-Wert-Paare.
- Sowohl HashMap als auch TreeMap sind nicht synchronisierte Sammlungen.
- Sowohl HashMap als auch TreeMap schlagen bei schnellen Sammlungen fehl.
Beide Implementierungen sind Teil des Erfassungsframeworks und speichern Daten in Schlüssel-Wert-Paaren.
Java-Programm mit HashMap und TreeMap
Hier ist ein Java-Programm, das demonstriert, wie Elemente aus der Hashmap abgerufen und eingefügt werden:
package com.edubca.map;
import java.util.*;
class HashMapDemo
(
// This function prints frequencies of all elements
static void printFrequency(int arr())
(
// Create an empty HashMap
HashMap hashmap =
new HashMap ();
// Iterate through the given array
for (int i = 0; i < arr.length; i++)
(
Integer value = hashmap.get(arr(i));
// If first occurrence of the element
if (hashmap.get(arr(i)) == null)
hashmap.put(arr(i), 1);
// If elements already present in hash map
else
hashmap.put(arr(i), ++value);
)
// Print result
for (Map.Entry m:hashmap.entrySet())
System.out.println("Frequency of " + m.getKey() +
" is " + m.getValue());
)
// Main method to test the above method
public static void main (String() args)
(
int arr() = (10, 40, 5, 12, 5, 7, 10);
printFrequency(arr);
)
)
Ausgabe:
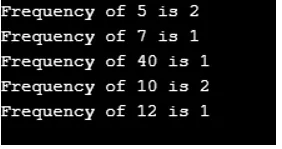
Aus der Ausgabe geht hervor, dass die Hashmap keine Reihenfolge beibehält. Hier ist ein Java-Programm, das demonstriert, wie Elemente von der Treemap abgerufen und abgelegt werden.
Code:
package com.edubca.map;
import java.util.*;
class TreeMapDemo
(
// This function prints frequencies of all elements
static void printFrequency(int arr())
(
// Create an empty HashMap
TreeMap treemap =
new TreeMap ();
// Iterate through the given array
for (int i = 0; i < arr.length; i++)
(
Integer value = treemap.get(arr(i));
// If first occurrence of element
if (treemap.get(arr(i)) == null)
treemap.put(arr(i), 1);
// If elements already present in hash map
else
treemap.put(arr(i), ++value);
)
// Print result
for (Map.Entry m: treemap.entrySet())
System.out.println("Frequency of " + m.getKey() +
" is " + m.getValue());
)
// Main method to test above method
public static void main (String() args)
(
int arr() = (10, 40, 5, 12, 5, 7, 10);
printFrequency(arr);
)
)
Ausgabe:
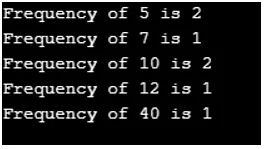
Aus der Ausgabe geht hervor, dass die Schlüssel in einer natürlichen Reihenfolge sortiert sind. Daher behält Treemap die sortierte Reihenfolge bei.
Kopf-an-Kopf-Unterschiede zwischen HashMap und TreeMap (Infografiken)
Nachstehend sind die wichtigsten Unterschiede zwischen HashMap und TreeMap aufgeführt

Der Hauptunterschied zwischen HashMap und TreeMap
Im Folgenden sind die wichtigsten Unterschiede zwischen HashMap und TreeMap aufgeführt:
1. Struktur und Implementierung
Hash Map ist eine Hash-Tabellen-basierte Implementierung. Es erweitert die Abstract Map-Klasse und implementiert die Map-Schnittstelle. Eine Hash Map funktioniert nach dem Prinzip des Hashens. Die Map-Implementierung fungiert als Hash-Tabelle mit Buckets. Wenn Buckets jedoch zu groß werden, werden sie in Tree-Knoten konvertiert, die jeweils eine ähnliche Struktur wie die Knoten von TreeMap aufweisen. TreeMap erweitert die Abstract Map-Klasse und implementiert eine navigierbare Kartenschnittstelle. Die zugrunde liegende Datenstruktur für die Baumkarte ist ein Rot-Schwarz-Baum.
2. Iterationsreihenfolge
Die Iterationsreihenfolge von Hash Map ist undefiniert, wohingegen Elemente einer TreeMap in natürlicher Reihenfolge oder in einer benutzerdefinierten Reihenfolge sortiert werden, die mithilfe eines Komparators angegeben wird.
3. Leistung
Da es sich bei Hashmap um eine hashtabellenbasierte Implementierung handelt, ist die Leistung bei konstanten Zeiten für die meisten gängigen Operationen gleich 0 (1). Die für die Suche nach einem Element in einer Hash-Map erforderliche Zeit beträgt O (1). Wenn jedoch eine fehlerhafte Implementierung in Hashmap vorliegt, kann dies zu zusätzlichem Arbeitsspeicher-Overhead und Leistungseinbußen führen. Auf der anderen Seite liefert TreeMap eine Leistung von O (log (n)). Da die Hashmap auf Hashtabellen basiert, ist ein zusammenhängender Speicherbereich erforderlich, wohingegen eine Treemap nur die Menge an Speicher benötigt, die zum Speichern von Elementen erforderlich ist. Daher ist HashMap zeiteffizienter als Treemap, aber platzsparender als HashMap.
4. Nullbehandlung
HashMap lässt fast einen Nullschlüssel und viele Nullwerte zu, wohingegen in einer Baumkarte Null nicht als Schlüssel verwendet werden kann, obwohl Nullwerte zulässig sind. Wenn null als Schlüssel in der Hashmap verwendet wird, wird eine Nullzeigerausnahme ausgelöst, da die Methode compare oder compareTo intern zum Sortieren von Elementen verwendet wird.
Vergleich der Tabelle
Hier ist eine Vergleichstabelle mit den Unterschieden zwischen Hashmap und Treemap:
| Vergleichsbasis | HashMap | TreeMap |
| Syntax | public class HashMap erweitert AbstractMap implementiert Map, Cloneable, Serializable | public class TreeMap erweitert AbstractMap implementiertNavigableMap, Cloneable, Serializable |
| Bestellung | HashMap bietet keine Reihenfolge für Elemente. | Elemente werden in einer natürlichen oder kundenspezifischen Reihenfolge bestellt. |
| Geschwindigkeit | Schnell | Schleppend |
| NULL-Schlüssel und -Werte | Ermöglicht fast einen Schlüssel als Null und mehrere Nullwerte. | Null als Schlüssel ist nicht zulässig, es sind jedoch mehrere Nullwerte zulässig. |
| Speicherverbrauch | HashMap belegt aufgrund der zugrunde liegenden Hash-Tabelle mehr Speicher. | Verbraucht weniger Speicher im Vergleich zu HashMap. |
| Funktionalität | Bietet nur grundlegende Funktionen | Es bietet umfangreichere Funktionen. |
| Verwendete Vergleichsmethode | Verwendet im Allgemeinen die Methode equals (), um Schlüssel zu vergleichen. | Verwendet die Methode compare () oder compareTo (), um Schlüssel zu vergleichen. |
| Schnittstelle implementiert | Karte, serialisierbar und klonbar | Navigierbare Karte, serialisierbar und klonbar |
| Performance | Gibt eine Leistung von O (1). | Liefert die Leistung von O (log n) |
| Datenstruktur | Verwendet die Hash-Tabelle als Datenstruktur. | Verwendet den Rot-Schwarz-Baum zur Datenspeicherung. |
| Homogene und heterogene Elemente | Es erlaubt sowohl homogene als auch heterogene Elemente, da es keine Sortierung durchführt. | Beim Sortieren sind nur homogene Elemente zulässig. |
| Anwendungsfälle | Wird verwendet, wenn wir keine Schlüssel-Wert-Paare in sortierter Reihenfolge benötigen. | Wird verwendet, wenn Schlüssel-Wert-Paare einer Karte sortiert werden müssen. |
Fazit
Aus dem Artikel wird der Schluss gezogen, dass es sich bei der Hashmap um eine Allzweckimplementierung der Map-Schnittstelle handelt. Es liefert die Leistung von O (1), während Treemap die Leistung von O (log (n)) liefert. Daher ist HashMap normalerweise schneller als TreeMap.
Empfohlene Artikel
Dies ist eine Anleitung zu HashMap vs TreeMap. Hier diskutieren wir die Einführung in HashMap vs TreeMap, Unterschiede zwischen Hashmap und Treemap und eine Vergleichstabelle. Sie können auch unsere anderen Artikelvorschläge durchgehen, um mehr zu erfahren.
- WebLogic gegen JBoss
- Liste vs Set
- Git Fetch gegen Git Pull
- Kafka vs Spark | Top Unterschiede
- Top 5 Unterschiede von Kafka zu Kinesis