

Einführung in die Hadoop-Architektur
Hadoop Architecture ist ein Open-Source-Framework, das die einfache Verarbeitung großer Datenmengen erleichtert. Es hilft bei der Erstellung von Anwendungen, die große Datenmengen schneller verarbeiten. Dabei werden die Konzepte für verteiltes Rechnen verwendet, bei denen Daten auf verschiedene Knoten eines Clusters verteilt werden. Die mit Hadoop erstellten Anwendungen verwenden Standardcomputer. Diese Computer sind leicht auf dem Markt zu günstigen Preisen erhältlich. Dieses Ergebnis führt zu einer höheren Rechenleistung bei geringen Kosten. Alle in Hadoop vorhandenen Daten befinden sich in HDFS anstelle eines lokalen Dateisystems. HDFS ist ein verteiltes Hadoop-Dateisystem. Dieses Modell basiert auf der Datenlokalität, bei der die Berechnungslogik an die Knoten gesendet wird, die in einem Cluster vorhanden sind, der die Daten enthält. Diese Logik ist nichts anderes als eine Logik, die das Programm kompiliert.
Hadoop-Architektur
Die Grundidee dieser Architektur besteht darin, dass die gesamte Speicherung und Verarbeitung in zwei Schritten und auf zwei Arten erfolgt. Der erste Schritt ist die Verarbeitung, die durch Map-Reduction-Programmierung ausgeführt wird, und der zweite Schritt ist das Speichern der Daten, die in HDFS ausgeführt werden. Es verfügt über eine Master-Slave-Architektur für die Speicherung und Datenverarbeitung. Der Masterknoten für die Datenspeicherung in Hadoop ist der Namensknoten. Es gibt auch einen Hauptknoten, der die Daten überwacht und parallel zur Datenverarbeitung arbeitet, indem er Hadoop Map Reduce verwendet. Die Slaves sind andere Maschinen im Hadoop-Cluster, die beim Speichern von Daten helfen und auch komplexe Berechnungen durchführen. Jedem Slave-Knoten wurde ein Task-Tracker zugewiesen, und ein Datenknoten verfügt über einen Job-Tracker, mit dessen Hilfe die Prozesse ausgeführt und effektiv synchronisiert werden können. Diese Art von System kann entweder in der Cloud oder vor Ort eingerichtet werden. Der Name-Knoten ist eine einzelne Fehlerquelle, wenn er nicht im Hochverfügbarkeitsmodus ausgeführt wird. Die Hadoop-Architektur sieht auch die Aufrechterhaltung eines Standby-Namensknotens vor, um das System vor Ausfällen zu schützen. Zuvor gab es sekundäre Namensknoten, die als Sicherung dienten, wenn der primäre Namensknoten inaktiv war.
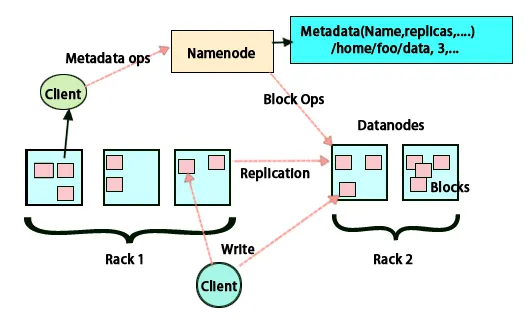
FBild und Bearbeitungsprotokoll
FSimage und Edit Log stellen die Persistenz der Dateisystem-Metadaten sicher, um mit allen Informationen Schritt zu halten, und der Name Node speichert die Metadaten in zwei Dateien. Diese Dateien sind das FSimage und das Bearbeitungsprotokoll. Die Aufgabe von FSimage ist es, zu einem bestimmten Zeitpunkt einen vollständigen Snapshot des Dateisystems zu erstellen. Die Änderungen, die ständig in einem System vorgenommen werden, müssen protokolliert werden. Diese inkrementellen Änderungen wie das Umbenennen oder Anhängen von Details an eine Datei werden im Bearbeitungsprotokoll gespeichert. Das Framework bietet eine bessere Möglichkeit, anstatt jedes Mal ein neues FSimage zu erstellen, und eine bessere Möglichkeit, die Daten während einer neuen Datei für FSimage zu speichern. FSimage erstellt bei jeder Änderung einen neuen Snapshot. Wenn der Name-Knoten ausfällt, kann er seinen vorherigen Status wiederherstellen. Der sekundäre Namensknoten kann auch seine Kopie aktualisieren, wenn Änderungen in FSimage vorgenommen und Protokolle bearbeitet werden. Auf diese Weise wird sichergestellt, dass trotz Ausfall des Namensknotens bei Vorhandensein des sekundären Namensknotens kein Datenverlust auftritt. Für den Namensknoten ist es nicht erforderlich, dass diese Images erneut auf den sekundären Namensknoten geladen werden müssen.
Datenreplikation
HDFS wurde entwickelt, um Daten schnell zu verarbeiten und zuverlässige Daten bereitzustellen. Es speichert Daten maschinenübergreifend und in großen Clustern. Alle Dateien werden in einer Reihe von Blöcken gespeichert. Diese Blöcke werden aus Gründen der Fehlertoleranz repliziert. Die Blockgröße und der Replikationsfaktor können von den Benutzern festgelegt und gemäß den Benutzeranforderungen konfiguriert werden. Standardmäßig ist der Replikationsfaktor 3. Der Replikationsfaktor kann zum Zeitpunkt der Dateierstellung angegeben und später geändert werden. Alle Entscheidungen bezüglich dieser Replikate werden vom Namensknoten getroffen. Der Namensknoten sendet weiterhin in regelmäßigen Abständen Heartbeats und Blockberichte für alle Datenknoten im Cluster. Der Empfang von Heartbeat bedeutet, dass der Datenknoten ordnungsgemäß funktioniert. Der Blockbericht gibt die Liste aller auf dem Datenknoten vorhandenen Blöcke an.
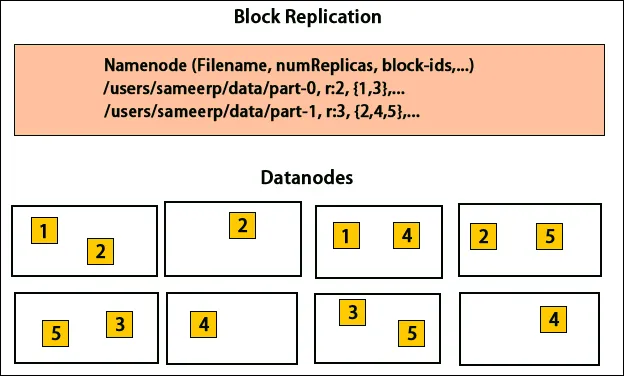
Platzierung von Repliken
Die Platzierung von Replikaten ist für Hadoop eine sehr wichtige Aufgabe für Zuverlässigkeit und Leistung. Alle verschiedenen Datenblöcke sind auf verschiedenen Racks platziert. Die Implementierung der Replikatplatzierung kann je nach Zuverlässigkeit, Verfügbarkeit und Netzwerkbandbreitennutzung erfolgen. Der Computercluster kann auf verschiedene Racks verteilt werden. Es können nicht mehr als zwei Knoten in einem Rack platziert werden. Das dritte Replikat sollte in einem anderen Rack platziert werden, um eine höhere Zuverlässigkeit der Daten zu gewährleisten. Die beiden Knoten im Rack kommunizieren über verschiedene Switches. Der Namensknoten hat die Rack-ID für jeden Datenknoten. Das Platzieren aller Knoten in verschiedenen Racks verhindert jedoch den Verlust von Daten und ermöglicht die Nutzung der Bandbreite mehrerer Racks. Es verringert auch den Datenverkehr zwischen Racks und verbessert die Leistung. Außerdem ist die Wahrscheinlichkeit eines Rackausfalls im Vergleich zu der eines Knotenausfalls sehr gering. Dies reduziert die gesamte Netzwerkbandbreite, wenn Daten von zwei anstatt von drei Racks gelesen werden.
Karte verkleinern
Map Reduce wird zur Verarbeitung von Daten verwendet, die in HDFS gespeichert sind. Es schreibt verteilte Daten über verteilte Anwendungen, wodurch eine effiziente Verarbeitung großer Datenmengen sichergestellt wird. Sie verarbeiten in großen Clustern und benötigen eine zuverlässige und fehlertolerante Ware. Das Herzstück von Map-Reduce können drei Operationen sein, wie das Mappen, das Sammeln von Paaren und das Mischen der resultierenden Daten.
Fazit - Hadoop-Architektur
Hadoop ist ein Open Source Framework, das in einem fehlertoleranten System hilft. Es kann große Datenmengen speichern und hilft bei der Speicherung zuverlässiger Daten. Die beiden Teile des Speicherns und Verarbeitens von Daten in HDFS über Map-Reduction tragen dazu bei, ordnungsgemäß und effizient zu arbeiten. Es verfügt über eine Architektur, mit der alle Datenblöcke verwaltet und die neueste Kopie abgelegt werden kann, indem sie in FSimage gespeichert und Protokolle bearbeitet werden. Der Replikationsfaktor hilft auch dabei, Kopien von Daten zu haben und diese bei einem Fehler wieder abzurufen. HDFS verschiebt entfernte Dateien auch in das Papierkorbverzeichnis, um den Speicherplatz optimal zu nutzen.
Empfohlene Artikel
Dies war ein Leitfaden für Hadoop Architecture. Hier haben wir die Architektur, Kartenverkleinerung, Platzierung von Replikaten und Datenreplikation besprochen. Sie können auch unsere anderen Artikelvorschläge durchgehen, um mehr zu erfahren -
- Werden Sie Hadoop-Entwickler
- Einführung in Android
- Was ist Tableau? | Ein Überblick
- Was ist MapReduce in Hadoop?