
Unterschiede zwischen Data Science und Datenvisualisierung
Data Science : Eine Kunst der Interpretation der Daten und der Gewinnung von Einsichten aus den Daten. Es ist auch eine Untersuchung von Beobachtungen und Interpretationen für ein besseres Ergebnis.
Datenvisualisierung : Darstellung der Daten. Datenwissenschaftler benötigen Tools, um mit den Daten umzugehen. Was kann daraus den besten Wert ziehen? Wie kann es abgebaut werden? Wie korreliert ein Parameter mit dem anderen? All diese Fragen werden mit einer der Lösungen beantwortet - Datenvisualisierungs-Tutorials.
Das beste Beispiel für Data Science auf unserer täglichen Basis ist die Empfehlung von Amazon für einen Benutzer beim Einkaufen. Die Maschine lernt etwas über die Webaktivität eines Benutzers und interpretiert und manipuliert diese, indem sie die beste Empfehlung basierend auf Ihren Interessen und der Wahl des Einkaufs abgibt. Um diese Empfehlung zu geben, stellen die Datenwissenschaftler die Webaktivität des Benutzers dar (visualisieren sie) und analysieren sie, um dem Benutzer die beste Auswahl zu bieten. Hier kommt die Datenvisualisierung ins Spiel.
Datenwissenschaft und Datenvisualisierung sind keine zwei unterschiedlichen Einheiten. Sie sind aneinander gebunden. Die Datenvisualisierung ist eine Teilmenge der Datenwissenschaft. Data Science ist kein einzelner Prozess oder eine Methode oder ein Workflow. Es ist ein kombinierter Effekt von kleinen Miniaturen, die sich mit den Daten befassen. Sei es ein Prozess der Data-Mining-Techniken, der EDA, der Modellierung, der Repräsentation.
Anwendungsfall
Beispiel : Um jeden Vorfall / jede Geschichte auf unserer täglichen Basis darzustellen, könnte sie als Rede vermittelt werden, aber wenn sie visuell dargestellt wird, wird der wahre Wert davon festgestellt und verstanden.
Außerdem geht es nicht nur darum, das Endergebnis darzustellen, sondern auch darum, die Rohdaten zu verstehen. Es ist immer besser, die Daten darzustellen, um bessere Einsichten zu erhalten und um das Problem zu lösen oder um aussagekräftige Informationen daraus zu erhalten, die das System beeinflussen.
Um ein besseres Verständnis von Data Science und Datenvisualisierung zu erlangen,
Angenommen, wir möchten vorhersagen, wie hoch die iPhone-Verkäufe im Jahr 2018 sein werden.
Wie genau kann man den Umsatz in der Zukunft vorhersagen? Was sind die Voraussetzungen, wie sicher ist Ihre Vorhersage, wie hoch ist die Fehlerquote? All dies wird datenwissenschaftlich beantwortet und begründet.
Voraussetzungen für eine Vorhersage ,
1. Historische Daten - iPhone-Verkäufe von 2010 bis 2017
2. Kaufhistorie auf Standortebene
3. Angaben zum Benutzer wie Alter usw
3. Schlüsselfaktoren - Letzte Änderungen in der Organisation, letzter Marktwert und die Kundenrezensionen zum letzten Verkauf
Wenn die historischen Daten gut gepflügt sind, werden viele Attribute berücksichtigt, um die Maschine auf die Vorhersage vorzubereiten.
Ein wichtiger Schlüssel für jede Vorhersage, Kategorisierung oder Analyse ist immer ein besseres Bild der Eingabedaten. Je besser Sie die Daten verstehen, desto besser die Vorhersage.
Wie gut könnte man aus den historischen Daten weitere Erkenntnisse gewinnen? Der beste Weg ist, es zu visualisieren.
Die Datenvisualisierung spielt in zwei Phasen eine Schlüsselrolle
- Die Anfangsphase der Analyse (dh Darstellung der verfügbaren Daten und Schlussfolgerung, welche Attribute und Parameter verwendet werden müssen, um eine Vorhersage-Maschine zu erstellen). Dies regt den Datenwissenschaftler dazu an, die Lösung mit verschiedenen Ansätzen zu versehen. In unserem Beispiel ist es also die Darstellung historischer Daten, welches historische Jahr für die Analyse am besten ausgewählt werden kann. Dies wird anhand der Visualisierung entschieden.
- Zwei - Ergebnis. Die Vorhersageergebnisse für das Jahr 2018 müssen so dargestellt werden, dass sie die Welt erreichen. Vergleich zwischen Telefon- und Google Pixel-Verkäufen für die kommenden Jahre. Dies wird zu einer besseren Entscheidungsfindung für die Organisationen führen.
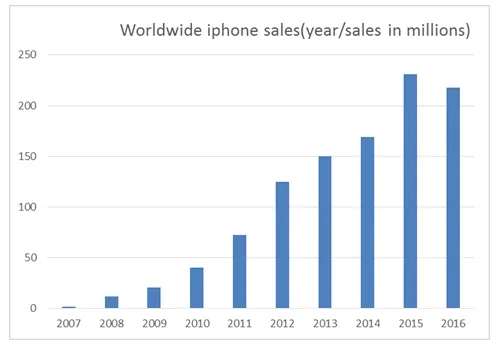
Zurück zur iPhone-Analyse müssen die historischen Daten analysiert und die besten Attribute ausgewählt werden, die einen signifikanten Einfluss auf die Prognoserate haben (z. B. Verkäufe nach Standort, Jahreszeit und Alter).
Anschließend wird das beste Modell ausgewählt (Algorithmen wie lineare Regression, logistische Regression,
und Support-Vektor-Maschine - um nur einige zu nennen). Trainieren Sie das Modell mit den historischen Daten und erhalten Sie die Vorhersage für das kommende Jahr. Dies ist ein umfassendes Bild der Prozesse in der Datenwissenschaft.
Sobald die Prognoseergebnisse für das kommende Jahr festgelegt sind, können sie dargestellt und einige Erkenntnisse gewonnen werden, die Einfluss auf die Verkaufs- und Marketingtechniken eines Produkts haben.
Head to Head Vergleich zwischen Data Science und Data Visualization (Infografik)
Unten finden Sie die Top 7 im Vergleich zwischen Data Science und Data Visualization. 
Hauptunterschiede zwischen Data Science und Datenvisualisierung
- Data Science umfasst mehrere statistische Lösungen zur Lösung eines Problems, während Visualisierung eine Technik ist, mit der Data Scientist die Daten analysieren und als Endpunkt darstellen.
- In der Datenwissenschaft geht es um Algorithmen zum Trainieren der Maschine (Automatisierung - Keine menschliche Kraft, die Maschine simuliert wie der Mensch, um viele manuelle Prozesse zu reduzieren. Es geht um Beobachtung und Interpretation der Aktivität). Bei der Datenvisualisierung geht es um Diagramme, das Plotten und die Auswahl des besten Modells basierend auf der Darstellung.
Vergleichstabelle zwischen Data Science und Data Visualization
Unten sind die Listen der Punkte, beschreiben den Vergleich zwischen Data Science und Data Visualization
| Vergleichsbasis | Datenwissenschaft | Datenvisualisierung |
| Konzept | Einblicke in die Daten. Erklärung der Daten. Vorhersage, Fakten | Darstellung der Daten (sei es eine Quelle oder die Ergebnisse) |
| Anwendungsfälle | Vorhersage des nächsten Weltcups, Automatisierte Autos | Leistungsindikatoren, Organisationsmetriken |
| Wer macht das? | Datenwissenschaftler, Datenanalytiker, Mathematiker | Datenwissenschaftler, UI / UX |
| Werkzeuge | Python, Matlab, R (um nur einige zu nennen) | Tableau, SAS, Power BI, d3 js (um nur einige zu nennen). Python und R verfügen auch über Bibliotheken, mit denen Sie Diagramme und Grafiken erstellen können. |
| Prozess | Datenerfassung, Data Mining, Datenbereinigung, Datenbereinigung, Modellierung, Messung | Stellen Sie es in irgendeiner Diagrammform oder in Diagrammen dar |
| Wie bedeutend | Viele Unternehmen verlassen sich bei der Entscheidungsfindung auf datenwissenschaftliche Ergebnisse. | Es hilft Datenwissenschaftlern dabei, die Quelle zu verstehen und das Problem zu lösen oder Empfehlungen abzugeben. |
| Kompetenzen | Statistiken, Algorithmen | Datenanalyse und Diagrammtechniken. |
Fazit - Data Science vs. Datenvisualisierung
Es gibt viele Perspektiven, wenn es um Datenwissenschaft geht. Auf einfache Art und Weise kann ein Problem in verschiedenen Fällen gelöst werden, z. B. durch Vorhersage, Kategorisierung, Empfehlungen und Stimmungsanalyse. Kurz gesagt, all dies könnte mithilfe der statistischen Methode zur Problemlösung erreicht werden. Es ist eine Kombination aus (Maschinelles Lernen, Deep Learning, Neuronale Netze, NLP, Daten-Mungling usw.)
Die Datenvisualisierung ist ein wesentlicher Bestandteil bei der Lösung der Probleme. Es ist ein Foto für Ihr Drehbuch (in der Laienbezeichnung).
Empfohlener Artikel
Dies war ein Leitfaden für Unterschiede zwischen Data Science und Data Visualization, deren Bedeutung, Kopf-an-Kopf-Vergleich, Hauptunterschiede, Vergleichstabelle und Schlussfolgerung. Sie können sich auch die folgenden Artikel ansehen, um mehr zu erfahren -
- Lernen Sie 5 nützliche Vergleiche zwischen Data Science und Statistik
- Data Science vs Künstliche Intelligenz - 9 Awesome Vergleich
- Datenvisualisierung vs. Business Intelligence - welche ist besser?
- Bester Leitfaden zur Datenvisualisierung mit Tableau