

Einführung in die Deep Learning-Technik
Die Deep-Learning-Technik basiert auf künstlichen neuronalen Netzen, die sich wie ein menschliches Gehirn verhalten. Es ahmt das Denken und Handeln des menschlichen Gehirns nach. In diesem Modell lernt und klassifiziert das System aus Bildern, Text oder Ton. Deep Learning-Modelle werden mit großen, beschrifteten und mehrschichtigen Daten trainiert, um eine hohe Genauigkeit des Ergebnisses zu erzielen, die sogar über dem menschlichen Niveau liegt. Fahrerloses Auto verwendet diese Technologie, um Stoppschilder, Fußgänger usw. in der Fortbewegung zu identifizieren. Elektronische Geräte wie Handys, Lautsprecher, Fernseher, Computer usw. verfügen aufgrund von Deep Learning über eine Sprachsteuerungsfunktion. Diese Technik ist neu und effizient für Verbraucher und Organisationen.
Deep Learning arbeiten
Deep Learning-Methoden verwenden neuronale Netze. Daher werden sie häufig als Deep Neural Networks bezeichnet. Tiefe oder versteckte neuronale Netze haben mehrere versteckte Schichten tiefer Netze. Deep Learning trainiert die KI, um die Ausgabe mithilfe bestimmter Eingaben oder versteckter Netzwerkebenen vorherzusagen. Diese Netzwerke werden durch große, beschriftete Datensätze trainiert und lernen Funktionen aus den Daten selbst. Sowohl überwachtes als auch nicht überwachtes Lernen trainiert die Daten und generiert Funktionen.
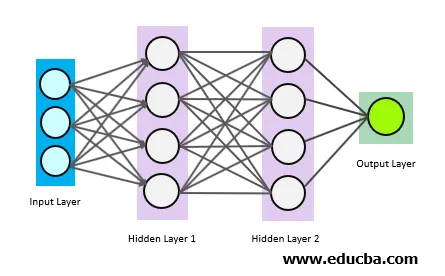
Die obigen Kreise sind Neuronen, die miteinander verbunden sind. Es gibt 3 Arten von Neuronen:
- Eingabeebene
- Versteckte Ebene (n)
- Ausgabeschicht
Die Eingabeebene erhält die Eingabedaten und leitet die Eingabe an die erste ausgeblendete Ebene weiter. Die mathematischen Berechnungen werden an den Eingabedaten durchgeführt. Schließlich gibt die Ausgabeschicht die Ergebnisse.
CNN oder konventionelle neuronale Netze, eines der beliebtesten neuronalen Netze, kombiniert Funktionen, die aus den Eingabedaten gelernt wurden, und verwendet 2D-Faltungsschichten, um es für die Verarbeitung von 2D-Daten wie Bildern geeignet zu machen. In diesem Fall reduziert CNN die Verwendung der manuellen Extraktion von Merkmalen. Es extrahiert direkt die erforderlichen Merkmale aus Bildern zur Klassifizierung. Aufgrund dieser Automatisierungsfunktion ist CNN ein größtenteils genauer und zuverlässiger Algorithmus beim maschinellen Lernen. Jeder CNN lernt Merkmale von Bildern aus der verborgenen Schicht, und diese verborgenen Schichten erhöhen die Komplexität der gelernten Bilder.
Der wichtige Teil ist das Trainieren der KI oder neuronalen Netze. Dazu geben wir Eingaben aus dem Datensatz ein und vergleichen schließlich die Ausgaben mit Hilfe der Ausgabe des Datensatzes. Wenn die KI nicht trainiert ist, ist die Ausgabe möglicherweise falsch.
Um herauszufinden, wie falsch die Ausgabe der KI von der tatsächlichen Ausgabe ist, benötigen wir eine Funktion zur Berechnung. Die Funktion heißt Kostenfunktion. Wenn die Kostenfunktion Null ist, sind sowohl die AI-Ausgabe als auch die reale Ausgabe gleich. Um den Wert der Kostenfunktion zu verringern, ändern wir die Gewichte zwischen den Neuronen. Für einen bequemen Ansatz kann eine Technik namens Gradient Descent verwendet werden. GD reduziert das Gewicht von Neuronen nach jeder Iteration auf ein Minimum. Dieser Vorgang erfolgt automatisch.
Deep Learning-Technik
Deep-Learning-Algorithmen durchlaufen mehrere Schichten der verborgenen Schicht (en) oder neuronalen Netze. Daher lernen sie die Bilder genau kennen, um sie genau vorhersagen zu können. Jede Ebene lernt und erkennt Features auf niedriger Ebene wie Kanten. Anschließend wird die neue Ebene zur besseren Darstellung mit den Features der vorherigen Ebene zusammengeführt. Beispielsweise kann eine mittlere Ebene eine beliebige Kante des Objekts erkennen, während die ausgeblendete Ebene das gesamte Objekt oder Bild erkennt.
Diese Technik ist bei großen und komplexen Daten effizient. Wenn die Daten klein oder unvollständig sind, kann DL nicht mehr mit neuen Daten arbeiten.
Es gibt einige Deep Learning-Netzwerke wie folgt:
- Unbeaufsichtigtes, vortrainiertes Netzwerk : Dies ist ein Basismodell mit drei Ebenen: Eingabe-, ausgeblendete und Ausgabeebene. Das Netzwerk wird darauf trainiert, die Eingabe zu rekonstruieren, und dann lernen ausgeblendete Ebenen aus den Eingaben, um Informationen zu sammeln, und schließlich werden Merkmale aus dem Bild extrahiert.
- Herkömmliches neuronales Netzwerk : Standardmäßig verfügt das neuronale Netzwerk über eine interne Faltung zur Kantenerkennung und genauen Erkennung von Objekten.
- Recurrent Neural Network : Bei dieser Technik wird der Ausgang der vorherigen Stufe als Eingang für die nächste oder aktuelle Stufe verwendet. RNN speichert die Informationen in Kontextknoten, um die Eingabedaten zu lernen und die Ausgabe zu erzeugen. Um beispielsweise einen Satz zu vervollständigen, benötigen wir Wörter. dh um das nächste Wort vorherzusagen, sind vorherige Wörter erforderlich, an die erinnert werden muss. RNN löst grundsätzlich diese Art von Problem.
- Rekursive neuronale Netze : Dies ist ein hierarchisches Modell, bei dem die Eingabe eine baumartige Struktur ist. Diese Art von Netzwerk wird erstellt, indem für die Zusammenstellung der Eingaben die gleichen Gewichtungen angewendet werden.
Deep Learning hat eine Vielzahl von Anwendungen in den Bereichen Finanzen, Computer Vision, Audio- und Spracherkennung, medizinische Bildanalyse, Arzneimitteldesign-Techniken usw.
Wie erstelle ich Deep Learning-Modelle?
Deep Learning-Algorithmen werden erstellt, indem Schichten zwischen ihnen verbunden werden. Der erste Schritt oben ist die Eingabeebene, gefolgt von der ausgeblendeten Ebene (n) und der Ausgabeebene. Jede Schicht besteht aus miteinander verbundenen Neuronen. Das Netzwerk verbraucht eine große Menge an Eingabedaten, um diese über mehrere Ebenen zu verarbeiten.
Um ein Deep Learning-Modell zu erstellen, sind folgende Schritte erforderlich:
- Das Problem verstehen
- Daten identifizieren
- Wählen Sie den Algorithmus
- Trainiere das Modell
- Testen Sie das Modell
Das Lernen erfolgt in zwei Phasen
- Wenden Sie eine nichtlineare Transformation der Eingabedaten an und erstellen Sie ein statistisches Modell als Ausgabe.
- Das Modell wird mit einer abgeleiteten Methode verbessert.
Diese beiden Operationsphasen werden als Iteration bezeichnet. Neuronale Netze wiederholen die beiden Schritte, bis die gewünschte Ausgabe und Genauigkeit erreicht ist.
1. Training von Netzwerken: Um ein Netzwerk von Daten zu trainieren, sammeln wir eine große Anzahl von Daten und entwerfen ein Modell, in dem die Funktionen erlernt werden. Bei sehr vielen Daten ist der Vorgang jedoch langsamer.
2. Transferlernen: Transferlernen optimiert grundsätzlich ein vorab trainiertes Modell und führt anschließend eine neue Aufgabe aus. In diesem Prozess wird die Rechenzeit geringer.
3. Merkmalsextraktion: Nachdem alle Ebenen auf die Merkmale des Objekts trainiert wurden, werden Merkmale daraus extrahiert und die Ausgabe wird genau vorhergesagt.
Fazit
Deep Learning ist eine Teilmenge von ML und ML ist eine Teilmenge von AI. Alle drei Technologien und Modelle haben einen enormen Einfluss auf das wirkliche Leben. Unternehmen und kommerzielle Giganten implementieren Deep Learning-Modelle für überlegene und vergleichbare Ergebnisse für die Automatisierung, die vom menschlichen Gehirn inspiriert sind.
Empfohlene Artikel
Dies ist eine Anleitung zur Deep Learning-Technik. Hier besprechen wir, wie Deep Learning-Modelle zusammen mit den beiden Betriebsphasen erstellt werden. Sie können sich auch die folgenden Artikel ansehen, um mehr zu erfahren -
- Was ist tiefes Lernen?
- Karrieren in Deep Learnings
- 13 Nützliche Fragen und Antworten zu Deep Learning-Vorstellungsgesprächen
- Hyperparameter Maschinelles Lernen