
Einführung in Bagging und Boosting
Bagging und Boosting sind die beiden beliebten Ensemble-Methoden. Bevor wir also Bagging und Boosting verstehen, wollen wir uns ein Bild davon machen, was Ensemble Learning ist. Es ist die Technik, mehrere Lernalgorithmen zu verwenden, um Modelle mit demselben Datensatz zu trainieren, um eine Vorhersage beim maschinellen Lernen zu erhalten. Nachdem wir die Vorhersage von jedem Modell erhalten haben, werden wir Modellmittelungstechniken wie gewichteter Durchschnitt, Varianz oder maximales Voting verwenden, um die endgültige Vorhersage zu erhalten. Diese Methode zielt darauf ab, bessere Vorhersagen als das einzelne Modell zu erhalten. Dies führt zu einer besseren Genauigkeit, die eine Überanpassung vermeidet, und verringert die Vorspannung und die Kovarianz. Zwei beliebte Ensemblemethoden sind:
- Absacken (Bootstrap-Aggregation)
- Erhöhen
Absacken:
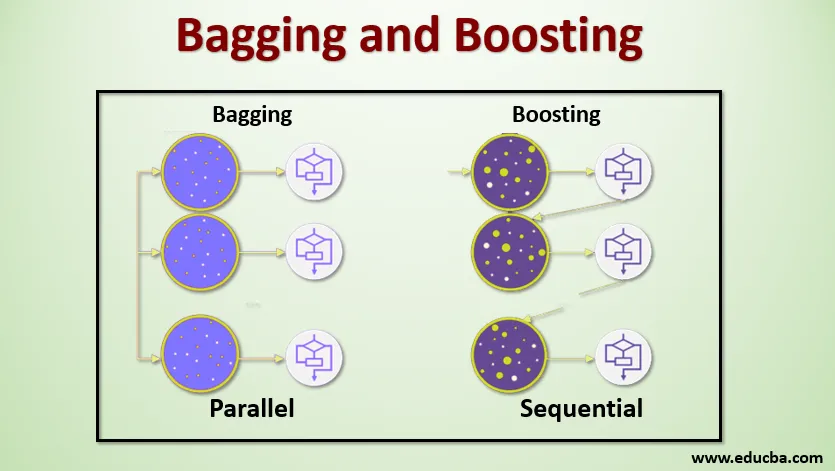
Bagging, auch als Bootstrap-Aggregation bezeichnet, dient zur Verbesserung der Genauigkeit und zur Verallgemeinerung des Modells, indem die Varianz verringert, dh eine Überanpassung vermieden wird. In diesem Beispiel nehmen wir mehrere Teilmengen des Trainingsdatensatzes. Für jede Teilmenge verwenden wir ein Modell mit denselben Lernalgorithmen wie Entscheidungsbaum, logistische Regression usw., um die Ausgabe für denselben Testdatensatz vorherzusagen. Sobald wir eine Vorhersage von jedem Modell haben, verwenden wir eine Modellmittelungstechnik, um die endgültige Vorhersage-Ausgabe zu erhalten. Eine der bekanntesten Techniken beim Absacken ist Random Forest . Im Random-Forest verwenden wir mehrere Entscheidungsbäume.
Boosting :
Boosting wird hauptsächlich verwendet, um die Tendenz und Varianz in einer überwachten Lerntechnik zu reduzieren. Es bezieht sich auf die Familie eines Algorithmus, der schwache Lernende (Grundschüler) in starke Lernende umwandelt. Der schwache Lernende sind die Klassifikatoren, die nur zu einem geringen Teil mit der tatsächlichen Klassifikation übereinstimmen, während die starken Lernenden die Klassifikatoren sind, die gut mit der tatsächlichen Klassifikation korrelieren. Einige bekannte Boosting-Techniken sind AdaBoost, GRADIENT BOOSTING und XgBOOST (Extreme Gradient Boosting). Jetzt wissen wir also, was Bagging und Boosten sind und welche Rolle sie beim maschinellen Lernen spielen.
Arbeiten von Bagging und Boosting
Nun wollen wir verstehen, wie das Absacken und Boosten funktioniert:
Absacken
Um die Funktionsweise des Absackens zu verstehen, nehmen wir an, dass wir eine Anzahl von N Modellen und einen Datensatz D haben. Dabei ist m die Anzahl der Daten und n die Anzahl der Merkmale in den einzelnen Daten. Und wir sollen binäre Klassifikation machen. Zuerst teilen wir den Datensatz auf. Im Moment werden wir diesen Datensatz nur in Trainings- und Test-Sets aufteilen. Nennen wir den Trainingsdatensatz als Wo ist die Gesamtzahl der Trainingsbeispiele?
Nehmen Sie eine Probe der Aufzeichnungen aus dem Trainingsset und trainieren Sie damit das erste Modell, sagen wir m1. Für das nächste Modell nimmt m2 erneut eine Stichprobe des Trainingssatzes und entnimmt eine weitere Stichprobe aus dem Trainingssatz. Wir werden dasselbe für die Anzahl N von Modellen tun. Da wir den Trainingsdatensatz erneut abtasten und die Proben daraus entnehmen, ohne etwas aus dem Datensatz zu entfernen, ist es möglich, dass zwei oder mehr Trainingsdatensätze in mehreren Proben vorhanden sind. Diese Technik zum erneuten Abtasten des Trainingsdatensatzes und zum Bereitstellen der Stichprobe für das Modell wird als Reihenabtastung mit Ersetzung bezeichnet. Angenommen, wir haben jedes Modell trainiert und möchten nun die Vorhersage für Testdaten sehen. Da wir an der binären Klassifizierung arbeiten, kann die Ausgabe entweder 0 oder 1 sein. Der Testdatensatz wird an jedes Modell übergeben, und wir erhalten eine Vorhersage von jedem Modell. Sagen wir aus N Modellen heraus, dass mehr als N / 2 Modelle 1 vorhergesagt haben. Daher können wir unter Verwendung der Modellmittelungstechnik wie der maximalen Abstimmung sagen, dass die vorhergesagte Ausgabe für die Testdaten 1 ist.
Erhöhen
Beim Boosten nehmen wir Datensätze aus dem Datensatz und übergeben sie der Reihe nach an Basislerner. Hierbei können Basislerner jedes Modell sein. Angenommen, der Datensatz enthält m Datensätze. Dann übergeben wir dem Grundschüler BL1 einige Aufzeichnungen und trainieren sie. Sobald der BL1 trainiert ist, übergeben wir alle Datensätze aus dem Datensatz und sehen, wie der Basislerner funktioniert. Für alle Datensätze, die vom Basis-Lernenden falsch klassifiziert wurden, nehmen wir sie nur und geben sie an einen anderen Basis-Lernenden weiter, z. Dies wird so lange fortgesetzt, bis wir eine bestimmte Anzahl von Basismodellen für Lernende angeben, die wir benötigen. Schließlich kombinieren wir die Ergebnisse dieser Basis-Lernenden und erstellen einen starken Lernenden. Dadurch wird die Vorhersagekraft des Modells verbessert. In Ordnung. Jetzt wissen wir also, wie das Absacken und Boosten funktioniert.
Vor- und Nachteile des Absackens und Auffrischens
Nachfolgend sind die wichtigsten Vor- und Nachteile aufgeführt.
Vorteile des Absackens
- Der größte Vorteil des Einsackens ist, dass mehrere schwache Lernende besser arbeiten können als ein einzelner starker Lernender.
- Es bietet Stabilität und erhöht die Genauigkeit des Algorithmus für maschinelles Lernen, der bei der statistischen Klassifizierung und Regression verwendet wird.
- Es hilft bei der Verringerung der Varianz, dh es vermeidet eine Überanpassung.
Nachteile des Absackens
- Wenn es nicht richtig modelliert wird, kann dies zu einer hohen Vorspannung und damit zu einer Unteranpassung führen.
- Da wir mehrere Modelle verwenden müssen, wird es rechenintensiv und ist möglicherweise in verschiedenen Anwendungsfällen nicht geeignet.
Vorteile von Boosting
- Es ist eine der erfolgreichsten Techniken zur Lösung der Zwei-Klassen-Klassifizierungsprobleme.
- Es ist gut im Umgang mit den fehlenden Daten.
Nachteile von Boosting
- Boosting ist aufgrund der höheren Komplexität des Algorithmus nur schwer in Echtzeit zu implementieren.
- Eine hohe Flexibilität dieser Techniken führt zu einer Vielzahl von Parametern, die sich direkt auf das Verhalten des Modells auswirken.
Fazit
Die wichtigste Erkenntnis ist, dass Bagging und Boosting ein Paradigma des maschinellen Lernens sind, bei dem wir mehrere Modelle verwenden, um dasselbe Problem zu lösen und eine bessere Leistung zu erzielen. Wenn wir schwache Lernende richtig kombinieren, können wir ein stabiles, genaues und robustes Modell erhalten. In diesem Artikel habe ich einen grundlegenden Überblick über das Absacken und Boosten gegeben. In den kommenden Artikeln lernen Sie die verschiedenen Techniken kennen, die in beiden verwendet werden. Abschließend möchte ich Sie daran erinnern, dass Bagging und Boosting zu den am häufigsten verwendeten Techniken des Ensemble-Lernens gehören. Die wahre Kunst, die Leistung zu verbessern, besteht darin, zu verstehen, wann Sie welches Modell verwenden und wie Sie die Hyperparameter optimieren.
Empfohlene Artikel
Dies ist eine Anleitung zum Absacken und Boosten. Hier besprechen wir die Einführung in das Absacken und Boosten und das Arbeiten mit Vor- und Nachteilen. Sie können auch unsere anderen Artikelvorschläge durchgehen, um mehr zu erfahren -
- Einführung in die Ensemble-Techniken
- Kategorien maschineller Lernalgorithmen
- Gradient Boosting Algorithmus mit Beispielcode
- Was ist der Boosting-Algorithmus?
- Wie erstelle ich einen Entscheidungsbaum?