

Einführung in die HBase-Architektur
HBase ist ein Open-Source-System zur verteilten Speicherung von Schlüsselwerten und eine spaltenorientierte Datenbank mit einer hohen Schreibleistung und einer zufälligen Leseleistung mit geringer Latenz. Mit HBase können wir Online-Echtzeitanalysen durchführen. Die HBase-Architektur ist stark zufällig lesbar. In HBase werden Daten physisch in sogenannte Regionen aufgeteilt. Jede Region wird von einem einzelnen Regionsserver gehostet, und eine oder mehrere Regionen sind für jeden Regionsserver verantwortlich. Die HBase-Architektur besteht aus Master-Slave-Servern. Der Cluster HBase verfügt über einen Masterknoten namens HMaster und mehrere Regionsserver namens HRegion Server (HRegion Server). Es gibt mehrere Regionen - Regionen in jedem Regionalserver.
HDFS-Speichermechanismus

In HDFS werden die Daten wie oben gezeigt in der Tabelle gespeichert.
Jede Zeile hat einen Schlüssel.
Spalte: Dies ist eine Sammlung von Daten, die zu einer Spaltenfamilie gehören und in der Zeile enthalten sind.
Spaltenfamilie: Jede Spaltenfamilie besteht aus einer oder mehreren Spalten.
Jede Tabelle enthält eine Sammlung von Spaltenfamilien. Diese Spalten sind nicht Teil des Schemas.
HBase verfügt über dynamische Spalten. Unterschiedliche Zellen können unterschiedliche Spalten haben, da die Spaltennamen in den Zellen codiert sind
Spaltenqualifikator: Der Spaltenname wird als Spaltenqualifikator bezeichnet.
HBase-Architekturkomponenten
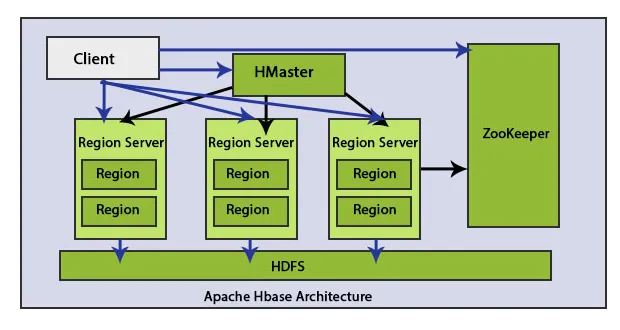
Die HBase-Architektur besteht aus folgenden Hauptelementen: HMaster und Region Server. Regionale HBase-Speicherung von Daten.
1. HMaster
Der HMaster-Knoten ist kompakt und wird zum Zuweisen der Region zur Serverregion verwendet.
Es gibt einige Hauptaufgaben von Hmaster, die sind:
- Ausführen einiger Verwaltungsaufgaben, einschließlich Laden, Ausgleichen, Erstellen von Daten, Aktualisieren, Löschen usw.
Verantwortlich für Änderungen im Schema oder Modifikationen in META-Daten gemäß der Anweisung der Client-Anwendung
- Viel DDL-Arbeit an HBase-Tabellen wird von HMaster erledigt.
Einige der Methoden, die HMaster Interface zur Verfügung stellt, sind hauptsächlich. META datenorientierte Methoden.
- Tabelle (Tabelle erstellen, entfernen, aktivieren, deaktivieren, entfernen)
- ColumnFamily (Spalte hinzufügen, Spalte ändern)
- Region (verschieben, zuweisen)
Der Client kommuniziert bidirektional mit HMaster und ZooKeeper. Es kontaktiert HRegion-Server direkt, um Lese- und Schreibvorgänge durchzuführen. HMaster weist den Servern in der Region Regionen zu und überprüft wiederum den Integritätsstatus der regionalen Server.
2. Regionsserver
Wir können uns anhand des folgenden Diagramms einen ungefähren Überblick über den Regionsserver verschaffen.

Regionsserver sind Arbeitsknoten, die Kundenanforderungen zum Lesen, Schreiben, Aktualisieren und Löschen verarbeiten. Der Region Server ist kompakt und läuft auf allen Knoten des Clusters Hadoop. Die Hauptaufgabe des Regionsservers besteht darin, die Daten in Bereichen zu speichern und Kundenanfragen auszuführen. Eine weitere wichtige Aufgabe des HBase-Regionsservers besteht darin, mithilfe der Auto-Sharding-Methode einen Lastenausgleich durchzuführen, indem die HBase-Tabelle dynamisch verteilt wird, wenn sie nach dem Einfügen von Daten zu groß wird.
Mehrere HRegion-Server können von HMaster kontaktiert werden und die folgenden Funktionen ausführen:
- Hostings und Regionen verwalten
- Regionen automatisch teilen
- Bearbeitung von Anfragen zum Lesen und Schreiben
- Direkte Kundenkommunikation
3. HDFS
HDFS steht für das Hadoop Distributed File System. Es speichert jede Datei in mehreren Blöcken und repliziert Blöcke in einem Hadoop-Cluster, um die Fehlertoleranz aufrechtzuerhalten. HDFS bietet eine hohe Fehlertoleranz und arbeitet mit kostengünstigen Materialien. Indem Sie billige Standardhardware verwenden, um dem Cluster Knoten hinzuzufügen und diese zu verarbeiten und zu speichern, erzielen Sie beim Kunden bessere Ergebnisse als mit der vorhandenen Hardware. HDFS kontaktiert die Komponenten von HBase und speichert viele Daten verteilt.
4. Tierpfleger
Zookeeper ist ein Open-Source-Projekt. HMaster und HRegionServers registrieren sich bei ZooKeeper.
Es bietet verschiedene Dienste wie die Verwaltung von Konfigurationsinformationen, die Benennung, die verteilte Synchronisation usw. Die verteilte Synchronisation ist der Prozess der Bereitstellung von Koordinationsdiensten zwischen Knoten, um auf laufende Anwendungen zuzugreifen. Es verfügt über kurzlebige Knoten, die Regionsserver darstellen. Masterserver verwenden diese Knoten, um nach verfügbaren Servern zu suchen.
Diese Knoten werden auch zum Nachverfolgen von Netzwerkpartitionen und Serverausfällen verwendet. Zookeeper ist das interaktive Medium zwischen Client Region Server. Wenn ein Client mit dem Regionsserver kommunizieren möchte, ist zookeeper das Kommunikationsmedium zwischen ihnen.
So wird die Suche in HBase Architecture initialisiert
Wie Sie wissen, wird der Speicherort der META-Tabelle von Zookeeper gespeichert. Wenn sich ein Kunde HBase-Anfragen nähert oder diese schreibt, gehen Sie wie folgt vor.
Der Kunde erfährt vom ZooKeeper, wie er den META-Tisch platzieren kann. Der Client fordert dann den entsprechenden Zeilenschlüssel von der META-Tabelle an, um auf den Speicherort des Regionsservers zuzugreifen. Mit der META-Tabellenposition speichert der Kunde diese Informationen im Cache. Der Kunde darf sich erst dann auf diese META-Tabelle beziehen, wenn der Bereich verschoben oder verschoben wurde. Dann wird der META-Server erneut angefordert und der Cache aktualisiert. Wie immer verschwenden Kunden keine Zeit damit, den Standort des Regionsservers auf META Server zu finden. Dies spart Zeit und beschleunigt den Suchvorgang.
Eigenschaften
Mit Hadoop ist es einfach, sowohl von der Quelle als auch vom Ziel aus zu integrieren.
Der verteilte Speicher wie HDFS wird unterstützt.
Es verfügt über eine Direktzugriffsfunktion, indem eine interne Hash-Tabelle zum Speichern von Daten für eine schnellere Suche in HDFS-Dateien verwendet wird.
Vorteile der HBase-Architektur
- Diese können große Datenmengen speichern
- Wir können die Datenbank teilen
- Gigabyte bis Petabyte kostengünstig
- Hohe Verfügbarkeit durch Replikation und Ausfall
Nachteile der HBase-Architektur
- SQL-Struktur unterstützt nicht
- Unterstützt keine Transaktion
- Nur mit Schlüssel sortiert
- Cluster-Speicherprobleme
Fazit
HBase ist eine spaltenorientierte verteilte NonSql-Datenbank in Apache. Beim Vergleich mit Hadoop oder Hive erzielt HBase eine bessere Leistung beim Abrufen weniger Datensätze. In diesem Artikel haben wir uns mit der HBase-Architektur und ihren wichtigen Komponenten befasst.
Empfohlene Artikel
Dies war ein Leitfaden für HBase Architecture. Hier haben wir das Konzept, die Komponenten, die Funktionen, die Vor- und Nachteile besprochen. Sie können auch unsere anderen Artikelvorschläge durchgehen, um mehr zu erfahren -
- Was ist Big Data-Technologie?
- HDFS vs HBase Welches ist besser
- Was ist Assemblersprache?
- Einführung in HTML