
Einführung in Modelle des maschinellen Lernens
Ein Überblick über verschiedene in der Praxis verwendete Modelle des maschinellen Lernens. Definitionsgemäß ist ein maschinelles Lernmodell eine mathematische Konfiguration, die nach Anwendung spezifischer Methoden des maschinellen Lernens erhalten wird. Das Erstellen eines maschinellen Lernmodells mithilfe der umfangreichen API-Palette ist heutzutage mit weniger Codezeilen ziemlich einfach. Die eigentliche Kompetenz eines angewandten Data-Science-Experten liegt jedoch in der Auswahl des richtigen Modells basierend auf der Problemstellung und der Kreuzvalidierung, anstatt Daten zufällig an ausgefallene Algorithmen zu übergeben. In diesem Artikel werden verschiedene Modelle des maschinellen Lernens erörtert und wie sie basierend auf der Art der Probleme, mit denen sie sich befassen, effektiv eingesetzt werden können.
Arten von Modellen für maschinelles Lernen
Basierend auf der Art der Aufgaben können wir Modelle für maschinelles Lernen in die folgenden Typen einteilen:
- Klassifizierungsmodelle
- Regressionsmodelle
- Clustering
- Dimensionsreduktion
- Deep Learning usw.
1) Klassifizierung
In Bezug auf maschinelles Lernen ist die Klassifizierung die Aufgabe, den Typ oder die Klasse eines Objekts innerhalb einer endlichen Anzahl von Optionen vorherzusagen. Die Ausgabevariable für die Klassifizierung ist immer eine kategoriale Variable. Das Vorhersagen einer E-Mail als Spam ist beispielsweise eine Standardaufgabe für die binäre Klassifizierung. Notieren wir uns nun einige wichtige Modelle für Klassifizierungsprobleme.
- K-Nearest-Neighbours-Algorithmus - einfach, aber rechenintensiv.
- Naive Bayes - Basierend auf dem Bayes-Theorem.
- Logistische Regression - Lineares Modell für die binäre Klassifikation.
- SVM - kann für Klassifizierungen von Binär- und Multiklassen verwendet werden.
- Entscheidungsbaum - Klassifizierer auf der Basis von " Wenn sonst ", robuster für Ausreißer.
- Ensembles - Kombination mehrerer Modelle für maschinelles Lernen, die zusammengelegt werden, um bessere Ergebnisse zu erzielen.
2) Regression
In der Maschine ist die Lernregression eine Reihe von Problemen, bei denen die Ausgabevariable kontinuierliche Werte annehmen kann. Beispielsweise kann die Vorhersage des Airline-Preises als Standardaufgabe für die Regression betrachtet werden. Notieren wir einige wichtige in der Praxis verwendete Regressionsmodelle.
- Lineare Regression - Das einfachste Basismodell für die Regressionsaufgabe funktioniert nur dann, wenn die Daten linear trennbar sind und nur eine sehr geringe oder keine Multikollinearität vorliegt.
- Lasso-Regression - Lineare Regression mit L2-Regularisierung.
- Ridge Regression - Lineare Regression mit L1-Regularisierung.
- SVM-Regression
- Entscheidungsbaum-Regression usw.
3) Clustering
In einfachen Worten, Clustering ist die Aufgabe, ähnliche Objekte zu gruppieren. Modelle für maschinelles Lernen helfen dabei, ähnliche Objekte ohne manuellen Eingriff automatisch zu identifizieren. Wir können keine effektiven, überwachten Modelle für maschinelles Lernen (Modelle, die mit manuell kuratierten oder gekennzeichneten Daten trainiert werden müssen) ohne homogene Daten erstellen. Clustering hilft uns dabei, dies auf intelligentere Weise zu erreichen. Im Folgenden sind einige der am häufigsten verwendeten Clustering-Modelle aufgeführt:
- K bedeutet - Einfach, leidet aber unter hoher Varianz.
- K bedeutet ++ - Modifizierte Version von K bedeutet.
- K medoids.
- Agglomeratives Clustering - Ein hierarchisches Clustering-Modell.
- DBSCAN - Dichtebasierter Clustering-Algorithmus usw.
4) Dimensionsreduktion
Dimensionalität ist die Anzahl der Prädiktorvariablen, die zur Vorhersage der unabhängigen Variablen oder des Ziels verwendet werden. In den Datensätzen der realen Welt ist die Anzahl der Variablen häufig zu hoch. Zu viele Variablen bringen auch den Fluch der Überanpassung in die Modelle. In der Praxis tragen bei dieser großen Anzahl von Variablen nicht alle Variablen gleichermaßen zum Ziel bei, und in einer großen Anzahl von Fällen können wir tatsächlich Abweichungen mit einer geringeren Anzahl von Variablen beibehalten. Lassen Sie uns einige häufig verwendete Modelle zur Dimensionsreduzierung auflisten.
- PCA - Es werden weniger neue Variablen aus einer großen Anzahl von Prädiktoren erstellt. Die neuen Variablen sind unabhängig voneinander, aber weniger interpretierbar.
- TSNE - Bietet die Einbettung höherdimensionaler Datenpunkte in niedrigere Dimensionen.
- SVD - Singular Value Decomposition wird verwendet, um die Matrix zur effizienten Berechnung in kleinere Teile zu zerlegen.
5) Tiefes Lernen
Deep Learning ist eine Teilmenge des maschinellen Lernens, die sich mit neuronalen Netzen befasst. Auf der Grundlage der Architektur neuronaler Netze listen wir wichtige Deep-Learning-Modelle auf:
- Mehrschichtiges Perzeptron
- Neuronale Faltungsnetze
- Wiederkehrende neuronale Netze
- Boltzmann-Maschine
- Autoencoder etc.
Welches Modell ist das Beste?
Oben haben wir uns Gedanken über viele Modelle des maschinellen Lernens gemacht. Nun stellt sich uns die naheliegende Frage: Welches ist das beste Modell unter ihnen? Dies hängt vom vorliegenden Problem und anderen zugehörigen Attributen wie Ausreißern, dem verfügbaren Datenvolumen, der Datenqualität, dem Feature-Engineering usw. ab. In der Praxis ist es immer vorzuziehen, mit dem einfachsten Modell zu beginnen, das auf das Problem anwendbar ist, und die Komplexität zu erhöhen schrittweise durch geeignete Parametereinstellung und Kreuzvalidierung. In der Welt der Datenwissenschaft gibt es ein Sprichwort: "Cross-Validation ist vertrauenswürdiger als Domain-Wissen".
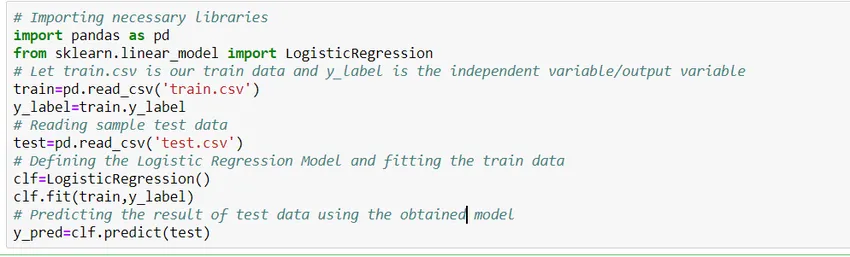
Wie baue ich ein Modell?
Schauen wir uns an, wie Sie mit der Python-Bibliothek von Scikit Learn ein einfaches logistisches Regressionsmodell erstellen. Der Einfachheit halber nehmen wir an, dass das Problem ein Standardklassifizierungsmodell ist und 'train.csv' der Zug und 'test.csv' die Zug- bzw. Testdaten sind.
Fazit
In diesem Artikel haben wir die wichtigen Modelle für maschinelles Lernen besprochen, die für praktische Zwecke verwendet werden, und wie ein einfaches Modell für maschinelles Lernen in Python erstellt wird. Die Auswahl eines geeigneten Modells für einen bestimmten Anwendungsfall ist sehr wichtig, um das richtige Ergebnis einer maschinellen Lernaufgabe zu erzielen. Um die Leistung zwischen verschiedenen Modellen zu vergleichen, werden Bewertungsmetriken oder KPIs für bestimmte Geschäftsprobleme definiert und das beste Modell für die Produktion nach Anwendung der statistischen Leistungsprüfung ausgewählt.
Empfohlene Artikel
Dies ist eine Anleitung zu Modellen für maschinelles Lernen. Hier diskutieren wir die Top 5 Arten von maschinellen Lernmodellen mit ihrer Definition. Sie können auch unsere anderen Artikelvorschläge durchgehen, um mehr zu erfahren -
- Methoden des maschinellen Lernens
- Arten des maschinellen Lernens
- Algorithmen für maschinelles Lernen
- Was ist maschinelles Lernen?
- Hyperparameter Maschinelles Lernen
- KPI in Power BI
- Hierarchischer Clustering-Algorithmus
- Hierarchisches Clustering | Agglomeratives & Divisives Clustering