
Definition des Mean-Shift-Algorithmus
Der Mean-Shift-Algorithmus fällt unter das nicht überwachte Lernen, das als Clustering-Algorithmus kategorisiert wird. Die Ideologie des Mean-Shift-Algorithmus ist, dass er den Clustern iterativ Datenpunkte zuweist, indem er sich zu dem Punkt verschiebt, der den höchsten Dichtepunkt (Mode) aufweist. Die Logik für die mittlere Verschiebung basiert auf dem Konzept der Kernel-Dichteschätzung, das als KDE bezeichnet wird.
Clustering von Mean-Shift-Algorithmen
Eine unbeaufsichtigte Lerntechnik, die von Fukunaga und Hostetler entdeckt wurde, um Cluster zu finden:
- Die mittlere Verschiebung ist auch als Modussuchalgorithmus bekannt, der die Datenpunkte den Clustern auf eine Weise zuordnet, indem die Datenpunkte in Richtung des Bereichs hoher Dichte verschoben werden. Die höchste Dichte von Datenpunkten wird als Modell in der Region bezeichnet. Der Mean-Shift-Algorithmus findet breite Anwendung im Bereich der Bildverarbeitung und Bildsegmentierung.
- KDE ist eine Methode zur Schätzung der Verteilung der Datenpunkte. Es funktioniert durch Platzieren eines Kernels auf jedem Datenpunkt. Der Kernel in math term ist eine Gewichtungsfunktion, die Gewichtungen für einzelne Datenpunkte anwendet. Das Hinzufügen des gesamten einzelnen Kernels erzeugt die Wahrscheinlichkeit.
Die Kernelfunktion muss die folgenden Bedingungen erfüllen:
- Die erste Anforderung besteht darin, sicherzustellen, dass die Schätzung der Kerneldichte normalisiert ist.
- Die zweite Voraussetzung ist, dass KDE gut mit der Raumsymmetrie verbunden ist.
Zwei beliebte Kernelfunktionen
Nachfolgend sind die beiden darin verwendeten populären Kernel-Funktionen aufgeführt:
- Flacher Kern
- Gaußscher Kern
- Basierend auf dem verwendeten Kernel-Parameter variiert die resultierende Dichtefunktion. Wenn kein Kernelparameter angegeben ist, wird standardmäßig der Gaußsche Kernel aufgerufen. KDE verwendet das Konzept der Wahrscheinlichkeitsdichtefunktion, mit dessen Hilfe die lokalen Maxima der Datenverteilung ermittelt werden können. Der Algorithmus bewirkt, dass sich die Datenpunkte gegenseitig anziehen und die Datenpunkte in Richtung des Bereichs mit hoher Dichte weisen.
- Die Datenpunkte, die versuchen, gegen die lokalen Maxima zu konvergieren, gehören derselben Clustergruppe an. Im Gegensatz zum K-Means-Clustering-Algorithmus hängt die Ausgabe des Mean-Shift-Algorithmus nicht von Annahmen über die Form des Datenpunkts und die Anzahl der Cluster ab. Die Anzahl der Cluster wird vom Algorithmus in Bezug auf Daten bestimmt.
- Um die Implementierung des Mean Shift-Algorithmus durchzuführen, verwenden wir das Python-Paket SKlearn.
Implementierung des Mean-Shift-Algorithmus
Unten ist die Implementierung des Algorithmus:
Beispiel 1
Basiert auf dem Sklearn Tutorial für den Mean Shift Clustering Algorithmus. Das erste Snippet implementiert einen Algorithmus für die mittlere Verschiebung, um die Cluster des zweidimensionalen Datensatzes zu finden. Pakete, die zur Implementierung des Mean-Shift-Algorithmus verwendet werden.
Code:
fromcluster importMeanShift, estimate_bandwidth
from sklearn.datasets.samples_generator import make_blobs as mb
importpyplot as plt
fromitertools import cycle as cy
Ein wichtiger Punkt ist, dass wir die make_blobs-Bibliothek von sklearn verwenden, um Datenpunkte an drei Stellen zu generieren. Um den Mean-Shift-Algorithmus auf die generierten Punkte anzuwenden, müssen wir die Bandbreite festlegen, die die Wechselwirkung zwischen der Länge darstellt. Die Bibliothek von Sklearn verfügt über integrierte Funktionen zum Schätzen der Bandbreite.
Code:
#Sample data points
cen = ((1, .75), (-.75, -1), (1, -1)) x_train, _ = mb(n_samples=10000, centers= cen, cluster_std=0.6)
# Bandwidth estimation using in-built function
est_bandwidth = estimate_bandwidth(x_train, quantile=.1,
n_samples=500)
mean_shift = MeanShift(bandwidth= est_bandwidth, bin_seeding=True)
fit(x_train)
ms_labels = mean_shift.labels_
c_centers = ms_labels.cluster_centers_
n_clusters_ = ms_labels.max()+1
# Plot result
figure(1)
clf()
colors = cy('bgrcmykbgrcmykbgrcmykbgrcmyk')
fori, each inzip(range(n_clusters_), colors):
my_members = labels == i
cluster_center = c_centers(k) plot(x_train(my_members, 0), x_train(my_members, 1), each + '.')
plot(cluster_center(0), cluster_center(1),
'o', markerfacecolor=each,
markeredgecolor='k', markersize=14)
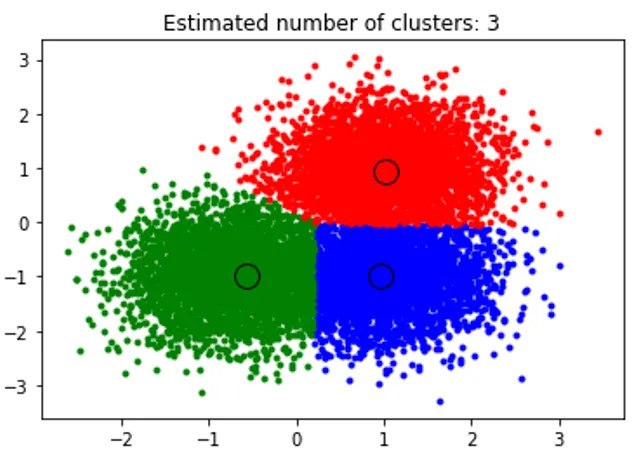
title('Estimated cluster numbers: %d'% n_clusters_)
show()
Das obige Snippet führt Clustering durch und der Algorithmus hat Cluster gefunden, die auf jedem von uns generierten Blob zentriert sind. Wir können sehen, dass aus dem Bild unten, das durch das Snippet dargestellt wird, der Mean-Shift-Algorithmus ersichtlich ist, mit dem die Anzahl der zur Laufzeit benötigten Cluster ermittelt und die geeignete Bandbreite zur Darstellung der Interaktionslänge ermittelt werden kann.
Ausgabe:
Beispiel # 2
Basierend auf der Bildsegmentierung in Computer Vision. Das zweite Snippet untersucht, wie der Mean-Shift-Algorithmus beim Deep Learning zur Segmentierung des Farbbildes verwendet wird. Wir verwenden den Mean-Shift-Algorithmus, um die räumlichen Cluster zu identifizieren. Das frühere Snippet verwendete einen 2D-Datensatz, während in diesem Beispiel der 3D-Raum untersucht wird. Pixel des Bildes werden als Datenpunkte (r, g, b) behandelt. Wir müssen das Bild in das Array-Format konvertieren, damit jedes Pixel den Datenpunkt im Bild darstellt, das wir zum Segment bringen. Das Clustering der Farbwerte im Raum gibt eine Reihe von Clustern zurück, wobei die Pixel im Cluster dem RGB-Raum ähneln. Pakete, die zur Implementierung des Mean-Shift-Algorithmus verwendet werden:
Code:
importnumpy as np
fromcluster importMeanShift, estimate_bandwidth
fromdatasets.samples_generator importmake_blobs
importpyplot as plt
fromitertools import cycle
fromPIL import Image
Unterhalb des Snippets, um das Originalbild zu segmentieren:
#Segmentation of Color Image
img = Image.open('Sample.jpg.webp')
img = np.array(img)
#Need to convert image into feature array based
flatten_img=np.reshape(img, (-1, 3))
#bandwidth estimation
est_bandwidth = estimate_bandwidth(flatten_img,
quantile=.2, n_samples=500)
mean_shift = MeanShift(est_bandwidth, bin_seeding=True)
fit(flatten_img)
labels= mean_shift.labels_
# Plot image vs segmented image
figure(2)
subplot(1, 1, 1)
imshow(img)
axis('off')
subplot(1, 1, 2)
imshow(np.reshape(labels, (854, 1224)))
axis('off')
Das erzeugte Bild besagt, dass dieser Ansatz zum Identifizieren der Formen von Bildern und zum Bestimmen der räumlichen Cluster ohne jegliche Bildverarbeitung effektiv durchgeführt werden kann.
Ausgabe:


Vorteile und Anwendungen Mean Shift-Algorithmus
Nachfolgend sind die Vorteile und die Anwendung des Mittelwertalgorithmus aufgeführt:
- Es ist weit verbreitet, um Computer Vision zu lösen, wo es zur Bildsegmentierung verwendet wird.
- Clustering von Datenpunkten in Echtzeit ohne Angabe der Anzahl der Cluster.
- Funktioniert gut bei Bildsegmentierung und Videoverfolgung.
- Robuster für Ausreißer.
Vorteile des Mean-Shift-Algorithmus
Nachfolgend finden Sie den Pro Mean Shift-Algorithmus:
- Die Ausgabe des Algorithmus ist unabhängig von Initialisierungen.
- Das Verfahren ist effektiv, da es nur einen Parameter hat - Bandbreite.
- Keine Annahmen über die Anzahl der Datencluster und die Form.
- Die Leistung ist besser als bei K-Means-Clustering.
Nachteile des Mean-Shift-Algorithmus
Nachfolgend sind die Nachteile des Mean-Shift-Algorithmus aufgeführt:
- Teuer für große Funktionen.
- Im Vergleich zum K-Means-Clustering ist es sehr langsam.
- Die Ausgabe des Algorithmus hängt von der Parameterbandbreite ab.
- Die Ausgabe hängt von der Größe des Fensters ab.
Fazit
Obwohl es sich um einen unkomplizierten Ansatz handelt, der in erster Linie zur Lösung von Problemen im Zusammenhang mit der Bildsegmentierung und der Clusterbildung eingesetzt wird. Es ist vergleichsweise langsamer als K-Means und es ist rechenintensiv.
Empfohlene Artikel
Dies ist eine Anleitung zum Mean Shift-Algorithmus. Hier diskutieren wir Probleme im Zusammenhang mit Bildsegmentierung, Clustering, Vorteilen und der Zwei-Kernel-Funktion. Sie können auch unsere anderen verwandten Artikel durchgehen, um mehr zu erfahren.
- K - bedeutet Clustering-Algorithmus
- KNN-Algorithmus in R
- Was ist ein genetischer Algorithmus?
- Kernel-Methoden
- Kernel-Methoden im maschinellen Lernen
- Detaillierte Erklärung des C ++ - Algorithmus