

Was ist Kafka?
Um Kafka zu verstehen, ist es besser zu verstehen, was Stream-Processing-Technologie ist. Die Stream-Verarbeitung ist eine Technologie, mit der ein Benutzer einen kontinuierlichen Datenstrom in einem Mikro-Zeitrahmen abfragen kann, um die zugrunde liegenden Zustände besser zu verstehen.
Ein Echtzeitszenario - Stellen Sie sich vor, Ihr Temperatursensor sendet Daten, die Sie abfragen und eine Warnung erhalten können, nachdem ein Gefrierpunkt erreicht wurde. Diese Datenabfrage kann in Mikrosekunden erfolgen.
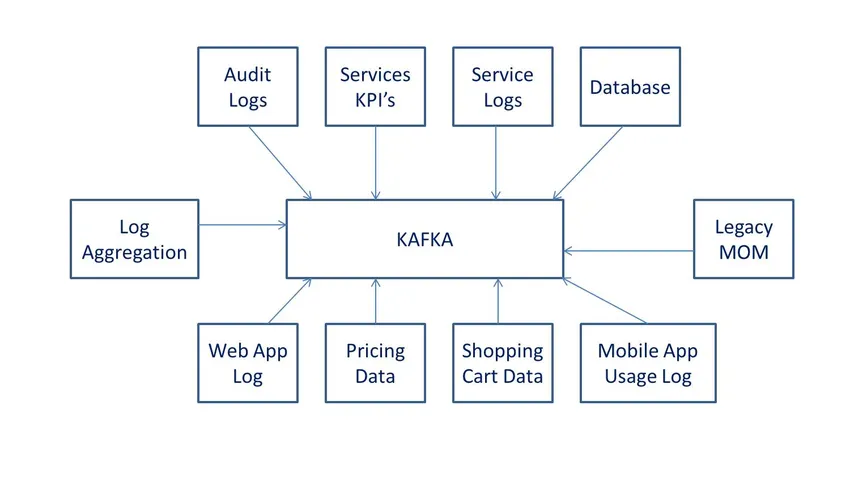
Definitionen
laut wiki handelt es sich um quelloffene datenverarbeitungssoftware. Es wurde von LinkedIn entwickelt und später an Apache-Software gespendet.
Kafka verstehen
Sein Wachstum explodiert exponentiell. Sehen wir uns einige Fakten und Statistiken an, um unsere Überlegungen besser zu unterstreichen. Mehr als ein Drittel der Fortune-500-Unternehmen auf der ganzen Welt bevorzugen ihn. Diese Verteilung wird von Reiseveranstaltern, Telekommunikationsriesen, Banken und mehreren anderen Unternehmen geteilt. LinkedIn, Microsoft und Netflix verarbeiten täglich vier Komma-Nachrichten mit Kafka (fast 1.000.000.000.000).
Es wird für Datenströme in Echtzeit verwendet, um große Datenmengen zu erfassen oder um Echtzeitanalysen (oder beides) durchzuführen. Kafka wird zusammen mit In-Memory-Mikrodiensten verwendet, um eine lange Lebensdauer zu gewährleisten, und kann verwendet werden, um Ereignisse an CEP- (komplexe Ereignis-Streaming-Systeme) und IoT / IFTTT-ähnliche Automatisierungssysteme weiterzuleiten.
Wie funktioniert Kafka so einfach?
Einfachheit wäre der richtige Weg, um die Leistung zu definieren. Es ist leicht herauszufinden, wie Kafka bei seiner Einrichtung und Verwendung so einfach funktioniert. Diese gesteigerte Verhaltensleistung ist auf die Stabilität, die zuverlässige Haltbarkeit und die flexible integrierte Funktion zum Veröffentlichen, Abonnieren oder Verwalten von Warteschlangen zurückzuführen. Dies ist sehr wichtig, wenn Sie sich mit N-Nummern von Kundengruppen befassen müssen, wenn Sie eine stabile Replikation auf dem Markt aufweisen müssen, um Ihren Kunden einen konsistenten Ansatz zu bieten (z. B. Kafka-Themenpartition). Ein entscheidendes Verhalten von Kafka, das es von seinen Mitbewerbern abhebt, ist die Kompatibilität mit Systemen mit Datenströmen - sein Prozess und die Möglichkeit, mit diesen Systemen andere Geschäfte zu aggregieren, zu transformieren und zu laden, um die Arbeit zu vereinfachen. "Alle oben genannten Tatsachen wären nicht möglich, wenn Kafka langsam wäre." Seine außergewöhnliche Leistung macht dies möglich.
Zusätzlich zur Erleichterung der Arbeit mit Kafka müssen wir zur „OS-Ebene“ wechseln. Lassen Sie uns herausfinden, wie die Dinge für Kafka auf Betriebssystemebene funktionieren -
- Es stützt sich auf Betriebssystem-Kernel, um die Daten schneller zu verschieben, und funktioniert nach dem Prinzip der Nullkopie.
- Auf diese Weise können Datensätze zu Blöcken zusammengefasst werden, die vom Dateisystem (auch als Kafka-Themenprotokoll bezeichnet) für die Verbraucher sichtbar sind.
- Die Möglichkeit, Daten zu stapeln, bietet eine effiziente Datenkomprimierung mit Reduzierung der E / A-Latenz.
- Es hat die Fähigkeit, durch Splittern horizontal zu skalieren. Es kann ein Titelprotokoll in Hunderte von Partitionen zu Tausenden teilen. Dies ermöglicht es, die enorme Arbeitsbelastung problemlos zu bewältigen.
Was kannst du mit Kafka machen?
Wenn Ihr Unternehmen regelmäßig mit großen Datenmengen arbeitet, benötigen Sie Kafka. Es gibt eine lange Liste von Unternehmen, die es verwenden.
- LinkedIn verwendet, um Daten und Betriebsmetriken zu verfolgen.
- Twitter, um Infrastrukturen für die Stream-Verarbeitung bereitzustellen.
Es gibt eine lange Liste von Unternehmen von Uber bis Spotify und von Goldman Sachs bis Cisco.
Vorteile
- Hoher Durchsatz: Es kann problemlos eine große Datenmenge verarbeiten, wenn mit hoher Geschwindigkeit generiert wird. Dies ist ein außergewöhnlicher Vorteil für Kafka. Dieser Anwendung fehlt riesige Hardware. Mit der Kapazität, den Nachrichtendurchsatz mit einer Häufigkeit von Tausenden von Nachrichten pro Sekunde zu unterstützen.
- Geringe Latenz: Geringe Latenz bei der Verarbeitung dieser Nachrichtengenerierung mit hohem Datenvolumen.
- Fehlertoleranz: Diese Funktion ist sehr nützlich. Sie kann inhärent durch einen in einem Cluster integrierten Knoten eingeschränkt werden.
- Langlebig: Es ist sehr langlebig und deshalb bevorzugen viele MNCs die Verwendung von Kafka. Apropos Langlebigkeit im Betrieb, die Nachrichten können langfristig nicht verloren gehen.
Benötigte Fähigkeiten
Es gibt keine besonderen Voraussetzungen, um ein Kafka-Profi zu sein. Aber wir haben einige Streams und Profis unterstrichen -
- Entwickler, die bereitwillig Karriere im Big Data-Stream machen und dort Karriere machen wollen.
- Testprofis haben in Kafka einen guten Anwendungsbereich in Bezug auf Warteschlangen- und Messagingsysteme
- Architekten - da alles ein Framework benötigt und dieses Framework von Zeit zu Zeit aktualisiert werden kann. Big Data-Architekten würden Kafka als eine gute Investition in ihre Karriere sehen.
- Der Projektmanager wird benötigt, wenn der oben genannte Fachmann für eine bessere Verwaltung der Ressourcen zur Verfügung steht. So stehen auch den Management-Profis im Bereich Kafka höhere Positionen zur Verfügung.
Warum Kafka benutzen?
Kafka wird weltweit bevorzugt, um Daten nachverfolgen und entsprechend den geschäftlichen Anforderungen bearbeiten zu können. Es bietet die Möglichkeit, Daten in Echtzeit mit Echtzeitanalysen zu streamen. Es ist schnell, skalierbar und langlebig und als Fehlertoleranz ausgelegt. Im Internet gibt es mehrere Anwendungsfälle, in denen Sie nachvollziehen können, warum JMS, RabbitMQ und AMQP nicht einmal als funktionsfähig gelten, da eine enorme Lautstärke und Reaktionsfähigkeit erforderlich sind.
Es verfügt über einen hohen Durchsatz und eine zuverlässige Einrichtung mit Replikationseigenschaften, was es zu einer bevorzugten Wahl für die Arbeit mit IoT-Sensoren macht.
Die Kompatibilität ist ein weiterer Grund für die weltweite Akzeptanz. Es kann einfach für die Verwendung mit der unten aufgeführten Anwendung konfiguriert werden. Diese Kombination ist für viele Unternehmen von entscheidender Bedeutung, um zu wachsen und zu überleben (da sie Zeit und Geld spart).
- Gerinne
- Spark-Streaming
- HBase
- Funken für die Echtzeitaufnahme, -verarbeitung und -analyse von Daten.
- Es wird verwendet, um Hadoop BigData zu füttern
Umfang
Es geht großartig auf der ganzen Welt. Nun, wir sagen das nicht eher als Statistik. Werfen wir einen Blick -
Gehaltsstatistiken für Kafka Professionals - PayScale
- Software Engineer - 109.825 US-Dollar
- Dateningenieur - 109.580 US-Dollar
- Entwickler - 81.182 US-Dollar
- Senior Data Engineer - 127 USD, 836 USD
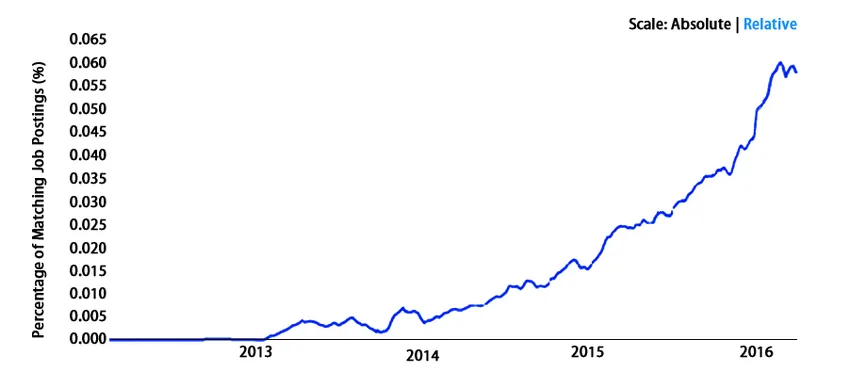
Fazit
Gegenwärtig ist Kafka zum De-facto-Standard geworden, wenn es um Echtzeit-Datenanalysen mit höchster Präzision in Mikrosekunden geht. Wir haben unsere Erkenntnisse in Bezug auf Daten und Details zur Unterstützung der Kafka-Technologien präsentiert. Es gibt mehrere große Unternehmen, die täglich Daten nutzen. Dazu benötigen sie Fachleute, die diese riesigen Datenmengen nutzen. Bei Kafka kann man sicher sein, dass sie ihre Karriere in einer BigData-Analyse führen
Empfohlene Artikel
Dies war ein Leitfaden für What is Kafka. Hier diskutierten wir die Arbeitsweise, den Umfang, das Karrierewachstum und die Vorteile von Kafka. Sie können auch unsere anderen Artikelvorschläge durchgehen, um mehr zu erfahren -
- Was ist Apache?
- Was ist Big Data und Hadoop?
- Was ist Azure?
- Was ist Big Data-Technologie?
- Kafka vs Spark | Top 5 Unterschiede
- Übersicht und Top-Anwendungen von Kafka
- Kafka vs Kinesis | 5 Unterschiede zu Infografiken