
Unterschied zwischen Hive und HBase
Apache Hive und HBase sind Hadoop-basierte Big-Data-Technologien. Beide verwendeten, um Daten abzufragen. Hive und HBase laufen auf Hadoop und unterscheiden sich in ihrer Funktionalität. Hive ist ein kartenreduzierter SQL-Dialekt, während HBase nur MapReduce unterstützt. HBase speichert Daten in Form von Schlüssel- / Wert- oder Spaltenfamilienpaaren, während Hive keine Daten speichert.
Head to Head Unterschiede zwischen Hive und HBase (Infografik)
Unten ist der Top 8 Unterschied zwischen Hive vs HBase
Hauptunterschiede zwischen Hive und HBase
- Hbase ist ACID-konform, Hive jedoch nicht.
- Hive unterstützt Partitionierungs- und Filterkriterien basierend auf dem Datumsformat, während HBase die automatische Partitionierung unterstützt.
- Hive unterstützt keine Update-Anweisungen, während HBase diese unterstützt.
- Hbase ist beim Abrufen von Daten schneller als Hive.
- Hive wird zur Verarbeitung strukturierter Daten verwendet, während HBase, da es schemafrei ist, jede Art von Daten verarbeiten kann.
- Hbase ist im Vergleich zu Hive hochgradig (horizontal) skalierbar.
- Hive analysiert die Daten auf dem HDFS mithilfe von SQL-Abfragen und konvertiert diese dann in eine Karte und reduziert Jobs. Da es sich um ein Echtzeit-Streaming handelt, werden die Vorgänge in der Datenbank direkt ausgeführt, indem in Tabellen und Spaltenfamilien partitioniert wird.
- Wenn Sie zum Abfragen von Daten kommen, verwendet Hive eine als Hive-Shell bekannte Shell, um die Befehle auszugeben, während HBase, da es sich um eine Datenbank handelt, einen Befehl zum Verarbeiten der Daten in HBase verwendet.
- Um zur Hive-Shell zu gelangen, verwenden wir den Befehl hive. Nachdem Sie dies angegeben haben, erscheint es wie hive>. In HBase geben wir einfach Use HBase an.
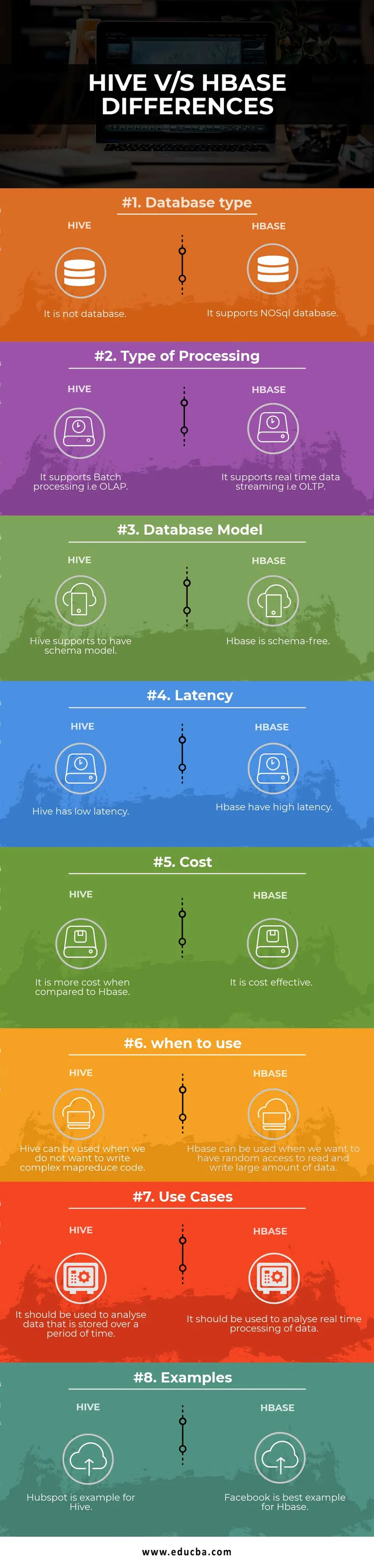
Hive vs HBase Vergleichstabelle
| Vergleichsbasis | Bienenstock | Hbase |
| Datenbanktyp | Es ist keine Datenbank | Es unterstützt NoSQL-Datenbank |
| Art der Verarbeitung | Es unterstützt die Stapelverarbeitung, dh OLAP | Es unterstützt Echtzeit-Daten-Streaming, dh OLTP |
| Datenbankmodell | Hive unterstützt ein Schemamodell | Hbase ist schemafrei |
| Latenz | Hive hat eine geringe Latenz | Hbase hat eine hohe Latenz |
| Kosten | Es ist teurer im Vergleich zu HBase | Es ist kostengünstig |
| wann zu verwenden | Hive kann verwendet werden, wenn kein komplexer MapReduce-Code geschrieben werden soll | HBase kann verwendet werden, wenn wir zufälligen Zugriff zum Lesen und Schreiben einer großen Datenmenge haben möchten |
| Anwendungsfälle | Es sollte zur Analyse von Daten verwendet werden, die über einen bestimmten Zeitraum hinweg gespeichert werden | Es sollte verwendet werden, um die Echtzeitverarbeitung von Daten zu analysieren. |
| Beispiele | Hubspot ist ein Beispiel für Hive | Facebook ist das beste Beispiel für Hbase |
Codierungsunterschiede zwischen Hive und HBase
Lassen Sie uns nun die grundlegenden Unterschiede zwischen Hive und HBase in der Codierung diskutieren.
| Vergleichsbasis | Bienenstock | Hbase |
| So erstellen Sie eine Datenbank | CREATE DATABASE (WENN NICHT EXISTIERT) DATABASE-NAME; | Da es sich bei Hbase um eine Datenbank handelt, müssen wir keine bestimmte Datenbank erstellen |
| So legen Sie eine Datenbank ab | DATENBANK DATENBANK-NAME (EINSCHRÄNKUNG ODER KASKADE); | N / A |
| So erstellen Sie eine Tabelle | CREATE (TEMPORARY ODER EXTERNAL) TABLE (WENN NICHT EXISTIERT) TABLE-NAME ((Spaltenname Datentyp (Kommentar Spaltenkommentar), ….)) (Kommentar Tabellenkommentar) (Zeilenformat ROW FORMAT) (Gespeichert als Dateiformat) | ERSTELLEN '', '' |
| Eine Tabelle ändern | ALTER TABLE name RENAME TO new-name
ALTER TABLE name DROP (COLUMN) Spaltenname ALTER TABLE-Name ADD COLUMNS (col-spec (, col-spec ..)) ALTER TABLE name CHANGE Spaltenname neuer Name neuer Typ ALTER TABLE name SPALTEN ERSETZEN (col-spec (, col-spec ..)) | ALTER 'TABLE-NAME', NAME => 'COLUMN-NAME', VERSIONS => |
| Deaktivieren einer Tabelle | N / A | deaktiviere 'TABLE-NAME' -> um den angegebenen Tabellennamen zu deaktivieren
disable_all 'r *' -> um alle Tabellen zu deaktivieren, die dem regulären Ausdruck entsprechen |
| Aktivieren einer Tabelle | N / A | aktiviere 'TABLE-NAME' |
| Einen Tisch fallen lassen | DROP TABLE IF EXISTS Tabellenname | Wenn wir eine Tabelle löschen möchten, müssen wir sie zuerst deaktivieren
deaktiviere 'tabellenname' drop 'tabellenname' Ebenso können wir disable_all und drop_all verwenden, um die Tabellen zu löschen, die dem angegebenen regulären Ausdruck entsprechen. |
| Datenbanken auflisten | Datenbanken anzeigen; | N / A |
| So listen Sie Tabellen in der Datenbank auf | Tabellen anzeigen; | aufführen |
| Schema einer Tabelle beschreiben | beschreibe den Tabellennamen; | beschreibe 'tabellenname' |
Integration von Hive vs HBase
- Installieren und konfigurieren Sie Hive.
- Installieren und konfigurieren Sie HBase.
- Für die Integration von Hive und HBase verwenden wir STORAGE HANDLERS in Hive.
- Storage Handlers ist eine Kombination aus SERDE, InputFormat und OutputFormat, die jede externe Entität als Tabelle in Hive akzeptiert.
- Diese Funktion unterstützt einen Benutzer beim Ausgeben von SQL-Abfragen, unabhängig davon, ob die Tabelle in Hadoop oder in der NOSQL-basierten Datenbank wie HBase, MongoDB, Cassandra oder Amazon DynamoDB vorhanden ist.
- Nun werden wir uns ein Beispiel für die Verbindung von Hive mit HBase mit HiveStorageHandler ansehen:
- Zuerst müssen wir eine Hbase-Tabelle mit dem Befehl erstellen.
erstelle 'Student', 'personalinfo', 'dept info'
-> Personalinfo und Abteilungsinfo erstellen zwei verschiedene Spaltenfamilien in der Schülertabelle.
- Wir müssen einige Daten in die Schülertabelle einfügen. Zum Beispiel, wie unten erwähnt.
setze 'student', 'sid01', 'personalinfo: name', 'Ram'
setze 'student', 'sid01', 'personalinfo: mailid', ' '
setze 'student', 'sid01', 'deptinfo: deptname', 'Java'
setze 'Student', 'sid01', 'deptinfo: joinyear', '1994'
-> Ebenso können wir Daten für sid02, sid03 erstellen …
- Jetzt müssen wir eine Hive-Tabelle erstellen, die auf die HBase-Tabelle zeigt.
- Für jede Spalte in der Hbase erstellen wir eine bestimmte Tabelle für diese Spalte in der Hive. In diesem Fall erstellen wir zwei Tabellen in der Hive
create external table student_hbase(sid String, name String, mailid String)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler with serdeproperties("hbase.columns.mapping"=":key, personalinfo:name, personalinfo:mailid")
tblproperties("hbase.table.name"="student");
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
-> Ebenso müssen wir eine Dept-Info-Detailtabelle in der Struktur erstellen.
- Jetzt können wir eine SQL-Abfrage in eine Struktur schreiben, wie unten erwähnt.
select * from student_hbase;
Auf diese Weise können wir Hive in HBase integrieren.
Fazit - Hive vs HBase
Wie bereits erwähnt, handelt es sich bei beiden um unterschiedliche Technologien, die unterschiedliche Funktionen bereitstellen, wenn Hive mithilfe der SQL-Sprache arbeitet. Sie können auch als HQL- und HBase-Schlüsselwertpaare zur Analyse der Daten bezeichnet werden. Hive und HBase funktionieren besser, wenn sie kombiniert werden, da Hive eine geringe Latenz aufweist und eine große Datenmenge verarbeiten kann, aber keine aktuellen Daten verwalten kann. HBase unterstützt keine Datenanalyse, sondern Aktualisierungen auf Zeilenebene für eine große Menge von Dateien.
Empfohlener Artikel
Dies war eine Anleitung zu Hive vs HBase, deren Bedeutung, Kopf-an-Kopf-Vergleich, Hauptunterschiede, Vergleichstabelle und Schlussfolgerung. Sie können sich auch die folgenden Artikel ansehen, um mehr zu erfahren -
- Apache Pig vs Apache Hive - Top 12 nützliche Unterschiede
- Finden Sie die 7 besten Unterschiede zwischen Hadoop und HBase heraus
- Top 12 Vergleich von Apache HBase vs Apache Hive (Infographics)
- Hadoop vs Hive - Finde die besten Unterschiede heraus