
Einführung in Autoencoder
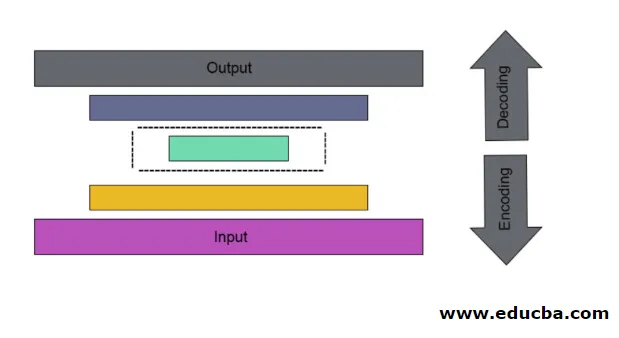
Es ist der Fall eines künstlichen neuronalen Gitters, das verwendet wird, um eine wirksame Datencodierung auf unbeaufsichtigte Weise zu entdecken. Das Ziel des Autoencoders besteht darin, die Darstellung für eine Gruppe von Daten zu lernen, insbesondere für das Verringern der Dimensionalität. Autoencoder haben eine einzigartige Funktion, bei der ihre Eingabe der Ausgabe entspricht, indem sie Feedforwarding-Netzwerke bilden. Autoencoder wandelt die Eingabe in komprimierte Daten um, um einen niedrigdimensionalen Code zu bilden, und zeichnet die Eingabe dann erneut zurück, um die gewünschte Ausgabe zu bilden. Der komprimierte Eingabecode wird auch als Latentraumdarstellung bezeichnet. Das Hauptziel besteht einfach darin, die Verzerrung zwischen den Schaltungen zu verringern.
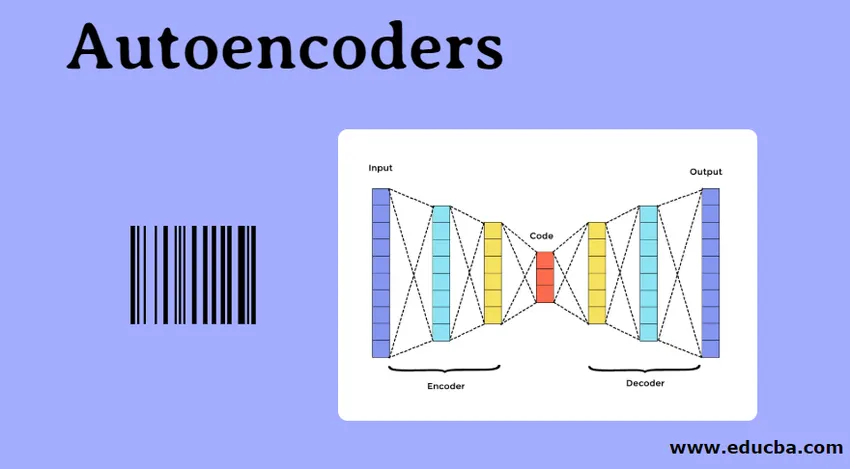
In Autoencoder gibt es drei Hauptkomponenten. Sie sind Encoder, Decoder und Code. Encoder und Decoder sind vollständig zu einem Feed Forwarding Mesh verbunden. Der Code fungiert als einzelne Ebene, die als eigene Dimension fungiert. Um einen Autoencoder zu entwickeln, müssen Sie einen Hyperparameter festlegen, dh die Anzahl der Knoten in der Kernebene. In detaillierterer Weise ist das Ausgangsnetzwerk des Decodierers ein Spiegelbild des Eingangscodierers. Der Decoder erzeugt nur mit Hilfe der Codeschicht die gewünschte Ausgabe.
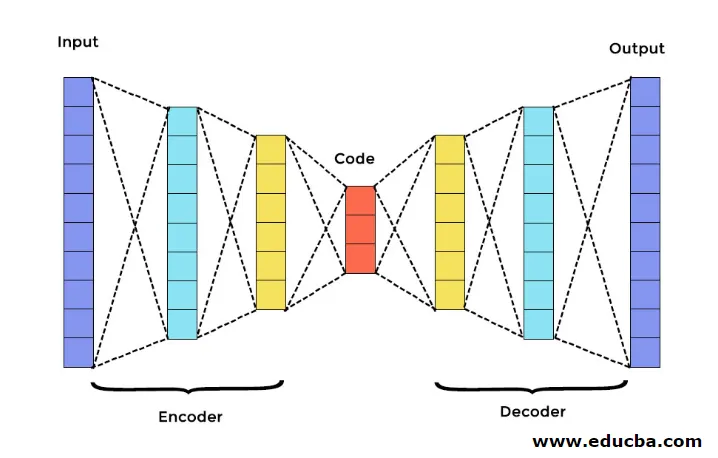
Stellen Sie sicher, dass Encoder und Decoder die gleichen Maßangaben haben. Der wichtige Parameter zum Einstellen des Autoencoders ist die Codegröße, die Anzahl der Ebenen und die Anzahl der Knoten in jeder Ebene.
Die Codegröße wird durch die Gesamtanzahl der in der mittleren Ebene vorhandenen Knoten definiert. Um eine effektive Komprimierung zu erzielen, ist die geringe Größe einer mittleren Schicht ratsam. Die Anzahl der Ebenen im Autoencoder kann je nach Wunsch tief oder flach sein. Die Anzahl der Knoten im Autoencoder sollte sowohl im Encoder als auch im Decoder gleich sein. Die Schicht aus Decoder und Encoder muss symmetrisch sein.
Im gestapelten Autoencoder haben Sie eine unsichtbare Ebene sowohl im Encoder als auch im Decoder. Es besteht aus handgeschriebenen Bildern mit einer Größe von 28 * 28. Jetzt können Sie Autoencoder mit 128 Knoten in der unsichtbaren Ebene mit 32 als Codegröße entwickeln. Verwenden Sie diese Funktion, um viele Ebenen hinzuzufügen
model.add(Dense(16, activation='relu'))
model.add(Dense(8, activation='relu'))
für umwandlung,
layer_1 = Dense(16, activation='relu')(input)
layer_2 = Dense(8, activation='relu')(layer_1)
Jetzt wird die Ausgabe dieser Ebene als Eingabe zur nächsten Ebene hinzugefügt. Dies ist die aufrufbare Ebene in dieser dichten Methode. Der Decoder führt diese Funktion aus. Es verwendet die Sigmoid-Methode, um eine Ausgabe zwischen 0 und 1 zu erhalten. Da die Eingabe zwischen 0 und 1 liegt

Die Rekonstruktion der Eingabe durch einen Autoencoder bei dieser Methode erfolgt durch Vorhersage. Der Einzelbildtest wird durchgeführt und die Ausgabe ist nicht genau wie die Eingabe, sondern ähnlich wie die Eingabe. Um diese Schwierigkeiten zu überwinden, können Sie den Autoencoder effizienter gestalten, indem Sie viele Ebenen und mehrere Knoten zu Ebenen hinzufügen. Wenn Sie es jedoch leistungsfähiger machen, erhalten Sie eine Kopie der Daten, die der Eingabe ähnlich sind. Dies ist jedoch nicht das erwartete Ergebnis.
Architektur von Autoencoder
In dieser gestapelten Architektur hat die Codeschicht einen kleinen Dimensionswert als die Eingabeinformation, in der sie sich unter vollständigem Autocodierer befindet.
1. Entrauschen von Autoencodern
Bei dieser Methode können Sie das Eingangssignal nicht in das Ausgangssignal kopieren, um das perfekte Ergebnis zu erzielen. Denn hier enthält das Eingangssignal Rauschen, das subtrahiert werden muss, bevor das Ergebnis erhalten wird, das den benötigten Daten zugrunde liegt. Dieser Vorgang wird als Entrauschungs-Autoencoder bezeichnet. Die erste Reihe enthält Originalbilder. Um ein rauschbehaftetes Eingangssignal zu erzeugen, werden rauschbehaftete Daten hinzugefügt. Jetzt können Sie den Autoencoder wie folgt für eine rauschfreie Ausgabe konfigurieren
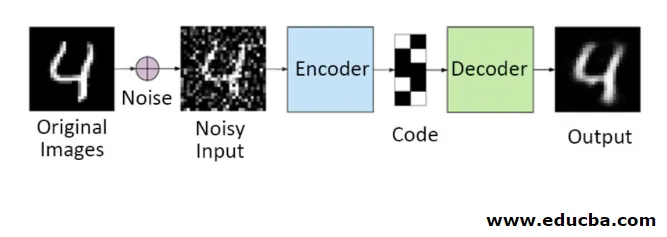
autoencoder.fit(x_train, x_train)
Ein modifizierter Autoencoder sieht wie folgt aus:
autoencoder.fit(x_train_noisy, x_train)
Somit können Sie problemlos eine rauschfreie Ausgabe erhalten.
Der Faltungsautocodierer wird verwendet, um komplexe Signale zu verarbeiten und ein besseres Ergebnis als der normale Prozess zu erzielen
2. Sparse Autoencoder
Um Autoencoder effektiv zu verwenden, können Sie zwei Schritte ausführen.
Stellen Sie eine kleine Codegröße ein und die andere rauscht den Autoencoder.
Dann ist Regularisierung eine andere effektive Methode. Um diese Regularisierung anzuwenden, müssen Sie Sparsity-Einschränkungen regularisieren. Um einige Teile von Knoten in der Ebene zu aktivieren, fügen Sie der Verlustfunktion einige zusätzliche Terme hinzu, die den Autoencoder veranlassen, jede Eingabe als kombinierte kleinere Knoten auszuführen, und den Encoder dazu bringen, einige eindeutige Strukturen in den angegebenen Daten zu finden. Dies gilt auch für eine große Anzahl von Daten, da nur ein Teil der Knoten aktiviert ist.
Der Wert der Sparsity-Einschränkung liegt näher bei Null
So generieren Sie eine Codeebene:
code = Dense(code_size, activation='relu')(input_img)
Um einen Regularisierungswert hinzuzufügen,
code = Dense(code_size, activation='relu', activity_regularizer=l1(10e-6))(input_img)
In diesem Modell ist nur 0, 01 der endgültige Verlust, der auch aufgrund des Regularisierungszeitraums entsteht.
In diesem spärlichen Modell entspricht eine Reihe von Codewerten dem erwarteten Ergebnis. Es hat aber relativ niedrige Varianzwerte.
Regularisierte Autoencoder haben einzigartige Eigenschaften wie Robustheit gegenüber fehlenden Eingaben, spärliche Darstellung und den Derivaten in Präsentationen am nächsten liegende Werte. Halten Sie für eine effektive Verwendung die minimale Codegröße und den flachen Encoder und Decoder ein. Sie stellen eine hohe Eingabekapazität fest und benötigen keinen zusätzlichen Regularisierungsterm, damit die Codierung effektiv ist. Sie sind darauf trainiert, einen maximierten Effekt zu erzielen, anstatt zu kopieren und einzufügen.
3. Variations-Autoencoder
Es wird in komplexen Fällen verwendet und ermittelt die Verteilungschancen beim Entwerfen der Eingabedaten. Dieser Auto-Variationscodierer verwendet eine Abtastmethode, um seine effektive Ausgabe zu erhalten. Es folgt der gleichen Architektur wie bei regulierten Autoencodern
Fazit
Daher werden Autoencoder verwendet, um reale Daten und Bilder zu lernen, die an binären und mehrklassigen Klassifizierungen beteiligt sind. Sein einfaches Verfahren zur Dimensionsreduzierung. Es wird in einer Restricted-Boltzmann-Maschine angewendet und spielt dabei eine entscheidende Rolle. Es wird auch in der biochemischen Industrie verwendet, um den nicht aufgedeckten Teil des Lernens zu entdecken und um das Muster intelligenten Verhaltens zu identifizieren. Jede Komponente des maschinellen Lernens hat einen selbstorganisierten Charakter. Autoencoder ist eine der Komponenten, die zum erfolgreichen Lernen in der künstlichen Intelligenz gehören
Empfohlene Artikel
Dies ist eine Anleitung zu Autoencodern. Hier werden die Hauptkomponenten von Autoencoder erläutert: Encoder, Decoder und Code sowie die Architektur von Autoencoder. Sie können sich auch die folgenden Artikel ansehen, um mehr zu erfahren -
- Big Data-Architektur
- Encoding vs Decoding
- Architektur des maschinellen Lernens
- Big Data-Technologien