

Einführung in die Lineare Algebra im maschinellen Lernen
Die lineare Algebra ist ein Teil der Mathematik, der lineare Gleichungen und deren Darstellungen durch Matrizen und Vektorräume umfasst. Es hilft bei der Beschreibung der Funktionen von Algorithmen und deren Implementierung. Es wird mit Tabellendaten oder Bildern verwendet, um die Algorithmen besser zu optimieren und das beste Ergebnis zu erzielen. In diesem Thema lernen wir die lineare Algebra im maschinellen Lernen kennen.
Matrix: Dies ist eine Reihe von Zahlen in rechteckiger Form, die durch Zeilen und Spalten dargestellt werden.
Beispiel:
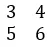
Vektor: Ein Vektor ist eine Zeile oder eine Spalte einer Matrix.
Beispiel:
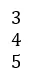
Tensor: Tensoren sind ein Array von Zahlen oder Funktionen, die mit bestimmten Regeln umgewandelt werden, wenn sich die Koordinaten ändern.
Wie funktioniert lineare Algebra beim maschinellen Lernen?
Da das maschinelle Lernen die Kontaktstelle für Informatik und Statistik ist, hilft die lineare Algebra dabei, Wissenschaft, Technologie, Finanzen und Rechnungswesen sowie den gesamten Handel miteinander zu verbinden. Numpy ist eine Bibliothek in Python, die mehrdimensionale Arrays für wissenschaftliche Berechnungen in Data Science und ML bearbeitet.
Die lineare Algebra funktioniert auf verschiedene Weise, wie in den folgenden Beispielen gezeigt wird:
1. Datensatz und Datendateien
Daten sind eine Matrix oder eine Datenstruktur in der linearen Algebra. Ein Datensatz enthält eine Reihe von Zahlen oder Daten in tabellarischer Form. Zeilen stellen Beobachtungen dar, während Spalten Merkmale davon darstellen. Jede Reihe ist gleich lang. Daten werden also vektorisiert. Die Zeilen sind vorkonfiguriert und werden zur einfacheren und authentischeren Berechnung einzeln in das Modell eingefügt.
2. Bilder und Fotografien
Alle Bilder sind tabellarisch aufgebaut. Jede Zelle in Schwarzweißbildern besteht aus Höhe, Breite und einem Pixelwert. In ähnlicher Weise enthalten Farbbilder, abgesehen von Höhe und Breite, 3-Pixel-Werte. Es bildet eine Matrix in der linearen Algebra. Alle Arten von Bearbeitungen wie Zuschneiden, Skalieren usw. und Manipulationstechniken werden mit algebraischen Operationen ausgeführt.
3. Regularisierung
Die Regularisierung ist eine Methode, mit der die Größe von Koeffizienten beim Einfügen in Daten minimiert wird. L1 und L2 sind einige gebräuchliche Implementierungsmethoden bei der Regularisierung, bei denen es sich um Maße für die Größe von Koeffizienten in einem Vektor handelt.
4. Tiefes Lernen
Diese Methode wird hauptsächlich in neuronalen Netzen mit verschiedenen realen Lösungen wie maschineller Übersetzung, Bildunterschrift, Spracherkennung und vielen anderen Bereichen verwendet. Es funktioniert mit Vektoren, Matrizen und sogar Tensoren, da lineare Datenstrukturen hinzugefügt und miteinander multipliziert werden müssen.
5. Eine heiße Kodierung
Es ist eine beliebte Kodierung für kategoriale Variablen, um Operationen in der Algebra zu vereinfachen. Eine Tabelle wird mit einer Spalte für jede Kategorie und einer Zeile für jedes Beispiel erstellt. Die Ziffer 1 wird für einen kategorialen Wert hinzugefügt, dem im Rest eine 0 folgt, und so weiter, wie nachstehend angegeben:

6. Lineare Regression
Die lineare Regression, eine der statistischen Methoden, wird zur Vorhersage numerischer Werte für Regressionsprobleme sowie zur Beschreibung der Beziehung zwischen Variablen verwendet.
Beispiel: y = A. b wobei A ein Datensatz oder eine Matrix ist, b ein Koeffizient ist und y die Ausgabe ist.
7. Hauptkomponentenanalyse oder PCA
Die Hauptkomponentenanalyse kann beim Arbeiten mit hochdimensionalen Daten für die Visualisierung und Modelloperationen angewendet werden. Wenn wir irrelevante Daten finden, neigen wir dazu, die redundanten Spalten zu entfernen. PCA fungiert also als Lösung. Die Matrixfaktorisierung ist das Hauptziel der PCA.
8. Single-Value Decomposition oder SVD
Es ist auch eine Matrixfaktorisierungsmethode, die allgemein bei der Visualisierung, Rauschunterdrückung usw. verwendet wird.
9. Latent Semantic Analysis
Dokumente werden dabei als große Matrizen dargestellt. Das in diesen Matrizen verarbeitete Dokument ist leicht zu vergleichen, abzufragen und zu verwenden. Es wird eine Matrix erstellt, in der Zeilen Wörter und Spalten Dokumente darstellen. SVD wird verwendet, um die Anzahl der Spalten zu verringern und gleichzeitig die Ähnlichkeit zu erhalten.
10. Empfehlungssysteme
Vorhersagemodelle stützen sich auf die Empfehlung von Produkten. Mit Hilfe der Linearen Algebra kann SVD Daten mit euklidischen Distanz- oder Punktprodukten bereinigen. Wenn wir beispielsweise ein Buch bei Amazon kaufen, basieren die Empfehlungen auf unserer Kaufhistorie, wobei andere irrelevante Artikel außer Acht gelassen werden.
Vorteile der linearen Algebra beim maschinellen Lernen
- Dient als solide Grundlage für maschinelles Lernen unter Einbeziehung von Mathematik und Statistik.
Sowohl Tabellen als auch Bilder können in linearen Datenstrukturen verwendet werden. - Es ist verteilend, assoziativ und kommunikativ.
- Es ist ein einfacher, konstruktiver und vielseitiger Ansatz in ML.
- Die lineare Algebra ist in vielen Bereichen anwendbar, z. B. Vorhersagen, Signalanalysen, Gesichtserkennung usw.
Lineare Algebra-Funktionen beim maschinellen Lernen
Es gibt einige lineare Algebra-Funktionen, die für ML- und Data Science-Operationen von entscheidender Bedeutung sind, wie unten beschrieben:
1. Lineare Funktion
Der lineare Regressionsalgorithmus verwendet eine lineare Funktion, bei der die Ausgabe kontinuierlich ist und eine konstante Steigung aufweist. Lineare Funktionen haben im Diagramm eine gerade Linie.
F (x) = mx + b
Wobei F (x) der Wert der Funktion ist,
m ist die Steigung der Linie,
b ist der Wert der Funktion, wenn x = 0,
x ist der Wert der x-Koordinate.
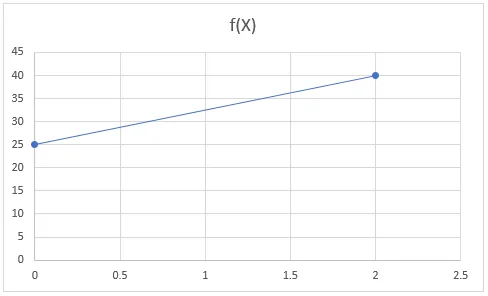
Beispiel: y = 5x + 25
Sei x = 0, dann y = 5 * 1 + 25 = 25
Sei x = 2, dann y = 5 * 2 + 25 = 40
2. Identitätsfunktion
Die Identitätsfunktion fällt unter den unüberwachten Algorithmus und wird hauptsächlich in neuronalen Netzen in ML verwendet, wo die Ausgabe des mehrschichtigen neuronalen Netzes der Eingabe entspricht, wie nachstehend angegeben:
Für jedes x ordnet f (x) x zu, dh x ordnet sich selbst zu.
Beispiel: x + 0 = x
x / 1 = x
1 --–> 1
2 -> 2
3 -> 3
3. Zusammensetzung
ML verwendet in seinen Algorithmen Kompositions- und Pipelining-Funktionen höherer Ordnung für mathematische Berechnungen und Visualisierungen. Die Zusammensetzungsfunktion wird wie folgt beschrieben:
(gof) (x) = g (f (x))
Beispiel: Es sei g (y) = y
f (x) = x + 1
gof (x + 1) = x + 1
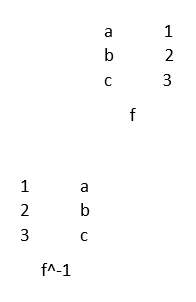
4. Inverse Funktion
Das Inverse ist eine Funktion, die sich selbst umkehrt. Die Funktionen f und g sind umgekehrt, wenn fog und gof definiert sind und Identitätsfunktionen sind
Beispiel:
5. Umkehrbare Funktion
Eine inverse Funktion ist invertierbar.
eins zu eins

auf zu
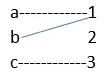
Fazit
Die lineare Algebra ist ein Teilgebiet der Mathematik. Es hat jedoch eine breitere Anwendung im maschinellen Lernen von der Notation bis zur Implementierung von Algorithmen in Datensätzen und Bildern. Mit Hilfe von ML hat die Algebra einen größeren Einfluss auf reale Anwendungen wie Suchmaschinenanalysen, Gesichtserkennung, Vorhersagen, Computergrafiken usw.
Empfohlene Artikel
Dies ist eine Anleitung zur linearen Algebra beim maschinellen Lernen. Hier diskutieren wir, wie die lineare Algebra beim maschinellen Lernen mit den Vorteilen und einigen Beispielen funktioniert. Sie können sich auch den folgenden Artikel ansehen.
- Hyperparameter Maschinelles Lernen
- Clustering im maschinellen Lernen
- Data Science Maschinelles Lernen
- Unüberwachtes maschinelles Lernen
- Unterschied zwischen linearer Regression und logistischer Regression