

Einführung in Python Pandas DataFrame
Mehrere Erweiterungen für die Python-Bibliothek Pandas sind online verfügbar. Eines davon ist Panel (pan) Data (das). Dieses Wort, * Panel *, deutet subtil auf eine zweidimensionale Datenstruktur hin, die in dieser Bibliothek vorhanden ist und deren Benutzer immens befähigt. Diese Struktur wird als DataFrame bezeichnet.
Es handelt sich im Wesentlichen um eine Matrix aus Zeilen und Spalten, die Ihr gesamtes Dataset enthält und sehr aufwändige Indizierungsoptionen bietet. Der DataFrame (DF) ist bildlich einem Excel-Sheet sehr ähnlich vorstellbar. Leistungsstark ist jedoch die einfache Durchführung von Analyse- und Transformationsvorgängen für die in einem DataFrame gespeicherten Daten.
Was genau ist ein Python Pandas DataFrame?
Pydata-Seite kann für eine offizielle Definition verwiesen werden.
Wenn es richtig verstanden wird, nennt es DataFrame eine Spaltenstruktur, in der jedes Python-Objekt (einschließlich eines DataFrame selbst) als ein Zellenwert gespeichert werden kann. (Eine Zelle wird mithilfe einer eindeutigen Zeilen- und Spaltenkombination indiziert.)
DataFrames bestehen aus drei wesentlichen Komponenten: Daten, Zeilen und Spalten.
- Daten: Bezieht sich auf die tatsächlichen Objekte / Entitäten, die in einer Zelle im DataFrame gespeichert sind, und auf die von diesen Entitäten dargestellten Werte. Ein Objekt hat einen gültigen Python-Datentyp, egal ob eingebaut oder benutzerdefiniert.
- Zeilen: Referenzen, die zum Identifizieren (oder Indizieren) eines bestimmten Satzes von Beobachtungen aus den in einem DataFrame gespeicherten vollständigen Daten verwendet werden, werden als Zeilen bezeichnet. Zur Verdeutlichung stellt es die verwendeten Indizes dar und nicht nur die Daten in einer bestimmten Beobachtung.
- Spalten: Referenzen, mit denen festgelegte Attribute für alle Beobachtungen in einem DataFrame identifiziert (oder indiziert) werden. Wie bei Zeilen beziehen sich diese auf den Spaltenindex (oder die Spaltenüberschriften) und nicht nur auf die Daten in der Spalte.
Probieren wir also ohne weiteres einige Möglichkeiten aus, um diese unglaublich mächtigen Strukturen zu erschaffen.
Schritte zum Erstellen von Python Pandas-Datenrahmen
Ein Python Pandas DataFrame kann mit der folgenden Codeimplementierung erstellt werden:
1. Pandas importieren
Zum Erstellen von DataFrames muss die Pandas-Bibliothek importiert werden (keine Überraschung hier). Wir werden es mit einem Alias pd importieren, um Objekte unter dem Modul bequem zu referenzieren.
Code:
import pandas as pd
2. Erstellen des ersten DataFrame-Objekts
Nach dem Import der Bibliothek stehen Ihnen alle Methoden, Funktionen und Konstruktoren in Ihrem Arbeitsbereich zur Verfügung. Versuchen wir also, einen Vanilla-DataFrame zu erstellen.
Code:
import pandas as pd
df = pd.DataFrame()
print(df)
Ausgabe:
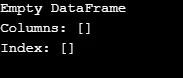
Wie in der Ausgabe gezeigt, gibt der Konstruktor einen leeren DataFrame zurück.
Konzentrieren wir uns nun auf die Erstellung von DataFrames aus Daten, die in einigen der wahrscheinlichen Darstellungen gespeichert sind.
- DataFrame aus einem Wörterbuch: Nehmen wir an, wir haben ein Wörterbuch, in dem eine Liste der Unternehmen in der Softwaredomäne und die Anzahl der Jahre gespeichert ist, in denen sie aktiv waren.
Code:
import pandas as pd
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Infosys', 'Directi'),
'Age':('21', '23', '38', '22') ))
print (df)
Sehen wir uns die Darstellung des zurückgegebenen DataFrame-Objekts an, indem Sie es auf der Konsole drucken.
Ausgabe:

Wie zu sehen ist, wird jeder Schlüssel des Wörterbuchs als Spalte im DataFrame behandelt, und die Zeilenindizes werden automatisch ab 0 generiert. Ziemlich einfach, oder?
Angenommen, Sie möchten einen benutzerdefinierten Index anstelle von 0, 1, .. angeben. 4. Sie müssen nur die gewünschte Liste als Parameter an den Konstruktor übergeben, und Pandas erledigen die erforderlichen Aufgaben.
Code:
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Yahoo', 'Infosys', 'Directi'),
'Age':('21', '23', '24', '38', '22') ),
index=('Alpha', 'Beta', 'Gamma', 'Delta'))
print(df)
Ausgabe:
Firmenalter
Alpha Google 21
Beta Amazon 23
Gamma Infosys 38
Delta Directi 22
Jetzt können Sie Zeilenindizes auf einen beliebigen Wert setzen.
- Datenrahmen aus einer CSV-Datei: Erstellen Sie eine CSV-Datei mit denselben Daten wie im Fall unseres Wörterbuchs. Nennen wir die Datei CompanyAge.csv
Google, 21
Amazon, 23
Infosys, 38
Directi, 22
Die Datei kann wie folgt in einen Datenrahmen geladen werden (vorausgesetzt, sie befindet sich im aktuellen Arbeitsverzeichnis).
Code:
csv_df = pd.read_csv(
'CompanyAge.csv', names=('Company', 'Age'), header=None)
print(csv_df)
Ausgabe:
Firmenalter
0 Google 21
1 Amazon 23
2 Infosys 38
3 Anweisung 22
Wenn Sie die Parameternamen unter Umgehung einer Werteliste festlegen, werden sie als Spaltenüberschriften in der Reihenfolge zugewiesen, in der sie in der Liste enthalten sind. In ähnlicher Weise können Zeilenindizes festgelegt werden, indem eine Liste an den Indexparameter übergeben wird, wie im vorherigen Abschnitt gezeigt. Die Überschrift = Keine zeigt fehlende Spaltenüberschriften in der Datendatei an.
Angenommen, die Spaltennamen waren Teil der Datendatei. Wenn Sie dann header = False setzen, wird der erforderliche Job ausgeführt.
3. CompanyAgeWithHeader.csv
Firma, Alter
Google, 21
Amazon, 23
Infosys, 38
Directi, 22
Der Code ändert sich zu
csv_df = pd.read_csv(
'CompanyAgeWithHeader.csv', header=False)
print(csv_df)
Ausgabe:
Firmenalter
0 Google 21
1 Amazon 23
2 Infosys 38
3 Anweisung 22
- Datenrahmen aus einer Excel-Datei: Oft werden Daten in Excel-Dateien geteilt, da dies das beliebteste Tool für die Ad-hoc-Nachverfolgung ist. Daher sollte es von unserer Diskussion nicht ignoriert werden.
Nehmen wir an, dass die Daten wie in CompanyAgeWithHeader.csv jetzt in CompanyAgeWithHeader.xlsx in einem Blatt mit dem Namen Company Age gespeichert sind. Der gleiche DataFrame wie oben wird mit dem folgenden Code erstellt.
Code:
excel_df= pd.read_excel('CompanyAgeWithHeader.xlsx', sheet_name='CompanyAge')
print(excel_df)
Ausgabe:
Firmenalter
0 Google 21
1 Amazon 23
2 Infosys 38
3 Anweisung 22
Wie Sie sehen, kann derselbe DataFrame erstellt werden, indem der Dateiname und der Blattname übergeben werden.
Weitere Lektüre und nächste Schritte
Die gezeigten Methoden bilden eine sehr kleine Teilmenge im Vergleich zu all den verschiedenen Möglichkeiten, wie DataFrames erstellt werden können. Diese wurden mit der Absicht erstellt, einen Anfang zu machen. Sie sollten auf jeden Fall die aufgelisteten Referenzen untersuchen und versuchen, andere Möglichkeiten zu erkunden, z. B. eine Verbindung zu einer Datenbank herzustellen, um Daten direkt in einen DataFrame einzulesen.
Fazit
Pandas DataFrame hat sich in der Welt von Data Science und Data Analytics als wegweisend erwiesen und eignet sich auch für kurzfristige Ad-hoc-Projekte. Es wird mit einer ganzen Reihe von Werkzeugen geliefert, mit denen der Datensatz äußerst einfach in Scheiben geschnitten und in Würfel geschnitten werden kann. Hoffentlich ist dies ein Sprungbrett für Ihre Reise in die Zukunft.
Empfohlene Artikel
Dies ist eine Anleitung zu Python-Pandas DataFrame. Hier werden die Schritte zum Erstellen eines Python-Pandas-Datenrahmens zusammen mit seiner Codeimplementierung erläutert. Sie können sich auch die folgenden Artikel ansehen, um mehr zu erfahren -
- Die 15 wichtigsten Funktionen von Python
- Verschiedene Arten von Python-Sets
- Die vier wichtigsten Variablentypen in Python
- Top 6 Editoren von Python
- Arrays in der Datenstruktur