

Was ist AWS Kinesis?
Kinesis ist eine Plattform, die beim Sammeln, Verarbeiten und Analysieren von Streaming-Daten in Amazon Web Services hilft. Beim Streaming von Daten handelt es sich um eine große Datenmenge, die aus verschiedenen Quellen wie Social Media, IoT-Sensoren, Wettervorhersage, Gesundheitswesen usw. stammt. Diese Daten werden je nach Benutzeranforderung beim Erstellen von Anwendungen verwendet. Einige der gängigen Anwendungen umfassen Predictive Analytics in Big Data, Maschinelles Lernen usw. In diesem Thema erfahren Sie mehr über AWS Kinesis.
AWS Kinesis Services
Bevor wir zu den Diensten übergehen, lassen Sie uns zunächst einige in Kinesis verwendete Terminologien verstehen.
Terminologie
| Begriff | Definition |
| Datensatz | Dateneinheit, die im Datenstrom von Kinesis gespeichert ist. Es besteht aus einem Daten-Blob, einer Sequenznummer und einem Partitionsschlüssel |
| Scherbe | Satz der Reihenfolge der Datensätze. Die Anzahl der Shards kann erhöht oder verringert werden, wenn die Datenrate erhöht wird. |
| Aufbewahrungsfrist | Der Zeitraum, in dem auf die Daten zugegriffen werden kann, nachdem sie dem Stream hinzugefügt wurden.
Standardaufbewahrungsdauer: 24 Stunden |
| Produzent | Es füttert Datensätze in Kinesis Stream |
| Verbraucher | Es werden Datensätze von Kinesis Stream abgerufen und verarbeitet. |
Kinesis bietet 3 Kerndienste an. Sie sind:
1. Kinesis Streams
Kinesis Stream besteht aus einer Reihe von Datensätzen, die als Shards bezeichnet werden. Diese Shards haben eine feste Kapazität, die eine maximale Lesegeschwindigkeit von 2 MB / s und eine Schreibgeschwindigkeit von 1 MB / s bieten kann. Die maximale Kapazität eines Streams ist die Summe der Kapazität jedes Shards.
Funktionsweise von Kinesis:
- Daten, die vom Internet der Dinge (IoT) und anderen als Produzenten bezeichneten Quellen erzeugt wurden, werden zur Speicherung in Shards in die Kinesis Streams eingespeist.
- Diese Daten sind in Shard maximal 24 Stunden lang verfügbar.
- Wenn es länger als diese Standardzeit aufbewahrt werden muss, kann der Benutzer die Aufbewahrungsfrist auf 7 Tage verlängern.
- Sobald die Daten die Shards erreichen, können EC2-Instanzen diese Daten für verschiedene Zwecke verwenden.
- EC2-Instanzen, die Daten abrufen, werden als Konsumenten bezeichnet.
- Nach der Verarbeitung der Daten werden diese in einen der Amazon Web Services wie Simple Storage Service (S3), DynamoDB, Redshift usw. eingespeist.
2. Kinesis Firehose
Kinesis Firehose ist hilfreich beim Verschieben von Daten zu Amazon-Webdiensten wie Redshift, Simple Storage Service, Elastic Search usw. Es ist Teil der Streaming-Plattform, die keine Ressourcen verwaltet. Datenproduzenten sind so konfiguriert, dass Daten an Kinesis Firehose gesendet werden müssen und diese dann automatisch an das entsprechende Ziel gesendet werden.
Funktionsweise von Kinesis Firehose:
- Wie in der Arbeit von AWS Kinesis Streams erwähnt, bezieht Kinesis Firehose auch Daten von Herstellern wie Mobiltelefonen, Laptops, EC2 usw. Dies muss jedoch keine Daten in Shards aufnehmen oder die Aufbewahrungsfristen verlängern, wie dies bei Kinesis Streams der Fall ist. Das liegt daran, dass Kinesis Firehose dies automatisch tut.
- Die Daten werden dann automatisch analysiert und in den Simple Storage Service eingespeist
- Da es keine Aufbewahrungsfrist gibt, müssen die Daten je nach Anforderung des Benutzers entweder analysiert oder an einen Speicher gesendet werden.
- Wenn Daten an Redshift gesendet werden müssen, müssen sie zuerst in den Simple Storage Service verschoben und von dort nach Redshift kopiert werden.
- Im Fall von Elastic Search können Daten jedoch direkt eingespeist werden, ähnlich wie bei Simple Storage Service.
3. Kinesis Analytics
Kinesis Firehose ermöglicht das Ausführen der SQL-Abfragen in den Daten, die in Kinesis Firehose vorhanden sind. Mithilfe dieser SQL-Abfragen können Daten in Redshift, Simple Storage Service, ElasticSearch usw. gespeichert werden.
AWS Kinesis-Architektur
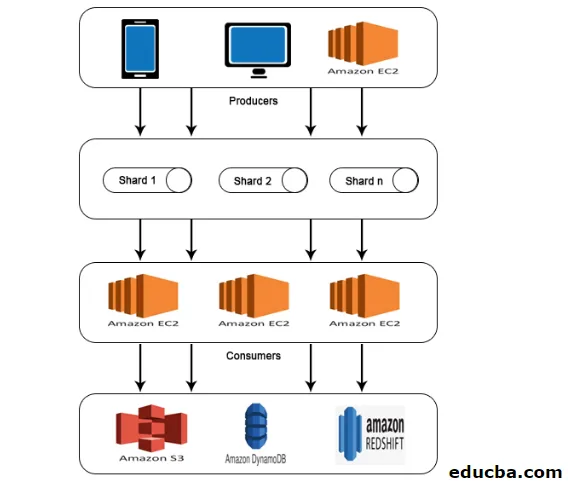
AWS Kinesis Architecture besteht aus
- Produzenten
- Scherben
- Verbraucher
- Lager
Ähnlich wie bei der in AWS Kinesis Data Stream erläuterten Arbeit werden Daten von Produzenten in Shards eingespeist, wo sie verarbeitet und analysiert werden. Die analysierten Daten werden dann zur Ausführung bestimmter Anwendungen in EC2-Instanzen verschoben. Endlich werden Daten in allen Amazon-Webdiensten wie S3, Redshift usw. gespeichert.
Wie verwende ich AWS Kinesis?
Um mit AWS Kinesis zu arbeiten, müssen die folgenden zwei Schritte ausgeführt werden.
1. Installieren Sie die AWS Command Line Interface (CLI).
Die Installation der Befehlszeilenschnittstelle ist für verschiedene Betriebssysteme unterschiedlich. Installieren Sie also die CLI basierend auf Ihrem Betriebssystem.
Verwenden Sie für Linux-Benutzer den Befehl sudo pip install AWS CLI
Stellen Sie sicher, dass Sie eine Python-Version 2.6.5 oder höher haben. Konfigurieren Sie es nach dem Herunterladen mit dem Befehl AWS configure. Dann werden die folgenden Details wie unten gezeigt abgefragt.
AWS Access Key ID (None): #########################
AWS Secret Access Key (None): #########################
Default region name (None): ##################
Default output format (None): ###########
Laden Sie für Windows-Benutzer das entsprechende MSI-Installationsprogramm herunter und führen Sie es aus.
2. Führen Sie Kinesis-Vorgänge mit der CLI aus
Bitte beachten Sie, dass Kinesis-Datenströme für die kostenlose Stufe AWS nicht verfügbar sind. Daher werden die erstellten Kinesis-Streams berechnet.
Lassen Sie uns nun einige Kinesis-Operationen in CLI sehen.
- Stream erstellen
Erstellen Sie mit dem folgenden Befehl einen Stream KStream mit Shard count 2.
aws kinesis create-stream --stream-name KStream --shard-count 2
Überprüfen Sie, ob der Stream erstellt wurde.
aws kinesis describe-stream --stream-name KStream
Wenn es erstellt wird, wird eine Ausgabe angezeigt, die dem folgenden Beispiel ähnelt.
(
"StreamDescription": (
"StreamStatus": "ACTIVE",
"StreamName": " KStream ",
"StreamARN": ####################,
"Shards": (
(
"ShardId": #################,
"HashKeyRange": (
"EndingHashKey": ###################,
"StartingHashKey": "0"
),
"SequenceNumberRange": (
"StartingSequenceNumber": "###################"
)
)
) )
)
- Rekord stellen
Jetzt kann ein Datensatz mit dem Befehl put-record eingefügt werden. Hier wird ein Datensatz mit einem Datentest in den Stream eingefügt.
aws kinesis put-record --stream-name KStream --partition-key 456 --data test
Wenn das Einfügen erfolgreich ist, wird die Ausgabe wie unten gezeigt angezeigt.
(
"ShardId": "#############",
"SequenceNumber": "##################"
)
- Aufzeichnung abrufen
Zunächst muss der Benutzer den Shard-Iterator abrufen, der die Position des Streams für den Shard darstellt.
aws kinesis get-shard-iterator --shard-id shardId-########## --shard-iterator-type TRIM_HORIZON --stream-name KStream
Führen Sie dann den Befehl mit dem erhaltenen Shard-Iterator aus.
aws kinesis get-records --shard-iterator ###########
Eine Beispielausgabe wird wie unten gezeigt erhalten.
(
"Records":( (
"Data":"######",
"PartitionKey":"456”,
"ApproximateArrivalTimestamp": 1.441215410867E9,
"SequenceNumber":"##########"
) ),
"MillisBehindLatest":24000,
"NextShardIterator":"#######"
)
- Aufräumen
Um Gebühren zu vermeiden, kann der erstellte Stream mit dem folgenden Befehl gelöscht werden.
aws kinesis delete-stream --stream-name KStream
Fazit
AWS Kinesis ist eine Plattform, die Streaming-Daten für verschiedene Anwendungen wie maschinelles Lernen, Predictive Analytics usw. sammelt, verarbeitet und analysiert. Streaming-Daten können ein beliebiges Format haben, z. B. Audio-, Video- oder Sensordaten.
Empfohlene Artikel
Dies ist eine Anleitung zu AWS Kinesis. Hier diskutieren wir, wie Sie AWS Kinesis und seinen Service mit Arbeiten und Architektur verwenden. Sie können auch den folgenden Artikel lesen, um mehr zu erfahren -
- AWS-Architektur
- Was ist AWS Lambda?
- Big Data-Technologien
- Data Mining-Architektur
- AWS Storage Services
- Leitfaden für Wettbewerber von AWS mit Funktionen