
Text Mining Einführung
Text Mining - Im heutigen Kontext ist Text das häufigste Mittel, über das Informationen ausgetauscht werden. Aber die Bedeutung des Textes zu verstehen, ist überhaupt keine leichte Aufgabe. Wir brauchen ein gutes Business-Intelligence-Tool, mit dem sich die Informationen auf einfache Weise verstehen lassen.
Was ist Text Mining?
Text Mining wird auch als Textanalyse bezeichnet. Es ist der Prozess des Verstehens von Informationen aus einer Reihe von Texten. Text Mining soll dem Unternehmen helfen, wertvolles Wissen aus textbasierten Inhalten zu ermitteln. Diese Inhalte können in Form von Word-Dokumenten, E-Mails oder Beiträgen in sozialen Medien vorliegen.
Text Mining ist die Verwendung automatisierter Methoden zum Verständnis des in den Textdokumenten verfügbaren Wissens.
Mit Text Mining kann der Computer auch strukturierte oder unstrukturierte Daten verstehen. Qualitative Daten oder unstrukturierte Daten sind Daten, die nicht in Zahlen gemessen werden können. Diese Daten enthalten normalerweise Informationen wie Farbe, Textur und Text. Quantitative Daten oder strukturierte Daten sind Daten, die einfach gemessen werden können.
Text Mining ist ein interdisziplinäres Feld, das ua Information Retrieval, Data Mining, maschinelles Lernen und Statistik umfasst. Text Mining unterscheidet sich geringfügig vom Data Mining.
Vorteile von Text Mining
Die Verwendung von Text Mining bietet viele Vorteile. Sie sind unten aufgeführt
- Es spart Zeit und Ressourcen und arbeitet effizienter als das menschliche Gehirn.
- Es hilft, Meinungen im Laufe der Zeit zu verfolgen
- Mit Text Mining können Sie die Dokumente zusammenfassen
- Mithilfe der Textanalyse können Konzepte aus Text extrahiert und auf einfachere Weise dargestellt werden
- Der mit Text Mining indizierte Text kann in der Vorhersageanalyse verwendet werden
- Sie können beliebige Vokabeln hinzufügen, um die Terminologie in Ihrem Interessengebiet zu verwenden
Verwendung von Text Mining
- Die Namen verschiedener Entitäten und Beziehungen zwischen dem Text können mit verschiedenen Techniken leicht gefunden werden.
- Es hilft, Muster aus einer großen Menge unstrukturierter Daten zu extrahieren
- Systematische Literaturrecherche - Sie kann eine gründliche Recherche von Texten durchführen, Schlüsselthemen ermitteln und die wiederholten Begriffe oder Texte und die beliebten Themen über einen bestimmten Zeitraum hervorheben.
- Testen der Hypothese - Durch Text Mining kann eine bestimmte Hypothese getestet werden, um festzustellen, ob das Dokument die Hypothese bestätigt oder ablehnt. Meistens wird ein etablierter Glaube zuerst über das Dokument geprüft.
Effektiv Lösungen für geschäftliche Probleme entwickeln. Erfahren Sie, wie Sie Geschäftsanforderungen definieren, analysieren und dokumentieren. Untersuchen Sie Geschäftsaktivitäten, um sie effizienter zu gestalten.
Bedeutung von Text Mining
- Text Mining ermöglicht eine bessere und intelligentere Entscheidungsfindung
- Es hilft bei der Lösung von Wissensentdeckungsproblemen in verschiedenen Geschäftsbereichen
- Durch Text Mining können Sie die Daten auf viele Arten wie HTML-Tabellen, Diagramme, Grafiken und andere leicht visualisieren
- Es ist ein großartiges Produktivitätswerkzeug. Es liefert schneller bessere Ergebnisse als jedes andere Werkzeug.
- Text Mining-Tool wird sowohl von großen als auch von kleinen Organisationen verwendet, die wissensbasierte Organisationen sind.
Anwendungen des Text Mining
-
Analyse von Antworten auf offene Umfragen
Offene Fragen zu Umfragen helfen den Befragten, ihre Meinung oder Meinung ohne Einschränkungen zu äußern. Dies hilft dabei, mehr über die Meinungen der Kunden zu erfahren, als sich auf strukturierte Fragebögen zu verlassen. Mit Text Mining können solche Informationen in Textform analysiert werden.
-
Automatische Verarbeitung von Nachrichten, E-Mails
Text Mining wird auch hauptsächlich zum Klassifizieren des Texts verwendet. Text Mining kann verwendet werden, um unnötige E-Mails mithilfe bestimmter Wörter oder Ausdrücke zu filtern. Solche Mails werden automatisch als Spam verworfen. Ein solches automatisches System zum Klassifizieren und Filtern ausgewählter E-Mails und zum Versenden an die entsprechende Abteilung erfolgt unter Verwendung des Text-Mining-Systems. Text Mining sendet auch eine Warnung an den E-Mail-Benutzer, um die E-Mails mit solchen beleidigenden Wörtern oder Inhalten zu entfernen.
-
Analyse von Gewährleistungs- oder Versicherungsansprüchen
In den meisten Unternehmensorganisationen werden Informationen hauptsächlich in Textform gesammelt. Beispielsweise können in einem Krankenhaus die Patienteninterviews kurz in Textform und die Berichte auch in Textform erzählt werden. Diese Notizen werden jetzt einen Tag lang elektronisch gesammelt, damit sie problemlos in Text Mining-Algorithmen übertragen werden können. Diese Aufzeichnungen können dann verwendet werden, um die tatsächliche Situation zu diagnostizieren.
-
Untersuchung von Wettbewerbern durch Crawlen ihrer Websites
Ein weiteres wichtiges Anwendungsgebiet von Text Mining ist die Verarbeitung der Inhalte von Webseiten in einer bestimmten Domäne. Auf diese Weise findet das Text-Mining-System automatisch eine Liste von Begriffen, die auf der Site verwendet werden. Auf diese Weise kann man die wichtigsten auf der Website verwendeten Begriffe herausfinden. Auf diese Weise kann man die Fähigkeiten der Wettbewerber kennen, die Ihnen dabei helfen können, Ihr Geschäft effizient zu betreiben.
Die anderen Anwendungen von Text Mining umfassen Folgendes
- Business Intelligence
- E Entdeckung
- Bioinformatik
- Aktenverwaltung
- Nationale Sicherheit oder Geheimdienst funktioniert
- Social Media Überwachung
In Text Mining verwendete Techniken
Im Text Mining-System werden fünf grundlegende Technologien verwendet. Sie werden nachstehend ausführlich erörtert
-
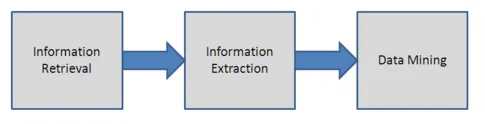
Informationsextraktion
Dies wird verwendet, um den unstrukturierten Text zu analysieren, indem die wichtigen Wörter herausgefunden und die Beziehungen zwischen ihnen gefunden werden. Bei dieser Technik wird der Prozess des Mustervergleichs verwendet, um die Reihenfolge im Text herauszufinden. Es hilft bei der Umwandlung des unstrukturierten Textes in eine strukturierte Form. Die Informationsextraktionstechnik beinhaltet Sprachverarbeitungsmodule. Dies wird hauptsächlich bei großen Datenmengen verwendet. Der Vorgang der Informationsextraktion wird in der folgenden Abbildung erläutert.
-
Kategorisierung
Die Kategorisierungstechnik klassifiziert das Textdokument unter einer oder mehreren Kategorien. Es basiert auf Input-Output-Beispielen für die Klassifizierung. Der Kategorisierungsprozess umfasst Vorverarbeitung, Indexierung, Dimensionsreduzierung und Klassifizierung. Der Text kann mit Techniken wie Naive Bayesian Classifier, Decision Tree, Nearest Neighbor Classifier und Support Vendor Machines kategorisiert werden.
-
Clustering
Die Clustering-Methode dient zum Gruppieren von Textdokumenten mit ähnlichen Inhalten. Es hat Partitionen, die als Cluster bezeichnet werden, und jede Partition enthält eine Reihe von Dokumenten mit ähnlichen Inhalten. Durch Clustering wird sichergestellt, dass kein Dokument in der Suche ausgelassen wird, und es werden alle Dokumente mit ähnlichen Inhalten abgeleitet. K-means ist die häufig verwendete Clustering-Technik. Diese Technik vergleicht auch jeden Cluster und ermittelt, wie gut die Dokumente miteinander verbunden sind. Unternehmen verwenden diese Technik, um eine Datenbank mit Tausenden ähnlicher Dokumente zu erstellen.
-
Visualisierung
Die Visualisierungstechnik vereinfacht das Auffinden relevanter Informationen. Diese Technik verwendet Textflags, um Dokumente oder Dokumentgruppen darzustellen, und Farben, um die Kompaktheit anzuzeigen. Die Visualisierungstechnik hilft, Textinformationen attraktiver anzuzeigen. Das folgende Bild zeigt die Visualisierungstechnik
-
Zusammenfassung
Das Zusammenfassungsverfahren hilft, die Länge des Dokuments zu verringern und die Details der Dokumente kurz zusammenzufassen. Dadurch kann das Dokument für die Benutzer gelesen werden und der Inhalt wird auf einen Blick verstanden. Die Zusammenfassung ersetzt den gesamten Dokumentensatz. Es fasst große Textdokumente einfach und schnell zusammen. Menschen nehmen sich mehr Zeit zum Lesen und Zusammenfassen des Dokuments, aber diese Technik macht es sehr schnell. Es hilft, wichtige Punkte in einem Dokument hervorzuheben. Der Zusammenfassungsprozess ist in der folgenden Abbildung dargestellt.
In Text Mining verwendete Methoden und Modelle
Basierend auf dem Informationsabruf hat Text Mining vier Hauptmethoden
-
Term Based Method (TBM)
Begriff in einem Dokument bedeutet ein Wort, das semantische Bedeutung hat. Bei dieser Methode wird der gesamte Dokumentensatz anhand der Laufzeit analysiert. Ein Hauptnachteil dieser Methode ist das Problem der Synonymie und Polysemie. Synonymie ist, wenn mehrere Wörter die gleiche Bedeutung haben. In der Polysemie hat ein einzelnes Wort mehr Bedeutungen.
-
Phrasenbasierte Methode (PBM)
Bei dieser Methode wird das Dokument anhand der Sätze analysiert, die für mehr Bedeutungen weniger offensichtlich und diskriminierender sind. Die Nachteile dieser Methode beinhalten
- Sie haben schlechtere statistische Eigenschaften als Terme
- Sie haben eine geringe Häufigkeit des Auftretens
- Sie haben eine große Anzahl von lauten Phrasen
-
Konzeptbasierte Methode (CBM)
Bei dieser Methode wird das Dokument basierend auf Satz- und Dokumentebene analysiert. Bei dieser Methode gibt es drei Hauptkomponenten. Die erste Komponente untersucht den sinnvollen Teil der Sätze. Die zweite Komponente erzeugt einen konzeptuellen ontologischen Graphen zur Erläuterung der Strukturen. Die dritte Komponente extrahiert Top-Konzepte basierend auf den ersten beiden Komponenten. Diese Methode kann zwischen wichtigen und unwichtigen Wörtern unterscheiden.
-
Muster Taxonomie Methode (PTM)
Bei dieser Methode wird das Dokument anhand der Muster analysiert. Muster in einem Dokument können mithilfe von Data-Mining-Techniken wie Assoziationsregel-Mining, sequentiellem Pattern-Mining, häufigem Item-Set-Mining und geschlossenem Pattern-Mining ermittelt werden. Diese Methode verwendet zwei Prozesse - Pattern Deployment und Pattern Evolving. Diese Methode ist nachweislich leistungsfähiger als alle anderen Modelle oder Methoden.
Wie funktioniert Text Mining?
Jetzt sollten Sie verstanden haben, dass Text Mining es ermöglicht, den Text besser zu verstehen als alles andere. Text Mining-System macht einen Austausch von Wörtern aus unstrukturierten Daten in numerische Werte. Mit Text Mining können Sie Muster und Beziehungen identifizieren, die in einer großen Textmenge vorhanden sind. Text Mining verwendet häufig Rechenalgorithmen zum Lesen und Analysieren von Textinformationen. Ohne Text Mining ist es schwierig, den Text einfach und schnell zu verstehen. Text kann systematischer und umfassender verarbeitet werden, und die Informationen über das Unternehmen können automatisch erfasst werden. Die Schritte im Text Mining-Prozess sind unten aufgeführt.
-
Schritt 1: Informationsbeschaffung
Dies ist der erste Schritt beim Data Mining. In diesem Schritt wird mithilfe einer Suchmaschine die Textsammlung ermittelt, die auch als Textkorpus bezeichnet wird und möglicherweise konvertiert werden muss. Diese Texte sollten auch in einem bestimmten Format zusammengestellt werden, das den Benutzern das Verständnis erleichtert. Normalerweise ist XML der Standard für Text Mining
-
Schritt 2: Verarbeitung natürlicher Sprache
Dieser Schritt ermöglicht es dem System, eine grammatische Analyse eines Satzes durchzuführen, um den Text zu lesen. Es analysiert auch den Text in Strukturen.
-
Schritt 3: Informationsextraktion
Dies ist die zweite Stufe, in der die Bedeutung einer bestimmten Textauszeichnung ermittelt wird. In dieser Phase werden der Datenbank Metadaten zum Text hinzugefügt. Dazu gehört auch das Hinzufügen von Namen oder Orten zum Text. In diesem Schritt kann die Suchmaschine die Informationen abrufen und die Beziehungen zwischen den Texten mithilfe ihrer Metadaten ermitteln.
-
Schritt 4: Data Mining
Die letzte Phase ist das Data Mining mit verschiedenen Tools. In diesem Schritt werden die Ähnlichkeiten zwischen den Informationen mit derselben Bedeutung ermittelt, die ansonsten schwer zu finden sind. Text Mining ist ein Tool, das den Rechercheprozess beschleunigt und das Testen der Abfragen erleichtert.
Text Mining enthält die folgende Liste von Elementen
- Textkategorisierung
- Text-Clustering
- Konzept- / Entitätsextraktion
- Granulare Taxonomien
- Stimmungsanalyse
- Dokumentzusammenfassung
- Modellierung von Entitätsbeziehungen
Herausforderungen beim Text Mining
Die größte Herausforderung für das Text Mining-System ist die natürliche Sprache. Die natürliche Sprache steht vor dem Problem der Mehrdeutigkeit. Mehrdeutigkeit bedeutet, dass ein Begriff mehrere Bedeutungen hat, eine Phrase auf verschiedene Arten interpretiert wird und dadurch unterschiedliche Bedeutungen erhalten werden.
Eine weitere Einschränkung besteht darin, dass bei der Verwendung des Informationsextraktionssystems eine semantische Analyse erforderlich ist. Aus diesem Grund wird der vollständige Text nicht angezeigt, sondern nur ein begrenzter Teil des Textes wird den Benutzern angezeigt. Heutzutage besteht jedoch ein Bedarf an mehr Textverständnis.
Text Mining unterliegt auch Beschränkungen des Urheberrechts. Es gibt viele Einschränkungen beim Text-Mining eines Dokuments. Meistens beinhaltet es die Rechte der Urheberrechtsinhaber. Die meisten Texte sind nicht als Open Source verfügbar. In diesem Fall ist eine Genehmigung der jeweiligen Autoren, Verlage und sonstigen Beteiligten erforderlich.
Eine weitere Einschränkung ist, dass Text Mining keine neuen Fakten generiert und kein Endprozess ist.
Fazit
Text Mining oder Textanalyse sind eine boomende Technologie, aber die Ergebnisse und die Tiefe der Analyse variieren von Unternehmen zu Unternehmen. Eine Organisation kann Text Mining verwenden, um Informationen zu inhaltsspezifischen Werten zu erhalten.