
Einführung in Bäume in der Datenstruktur
Bevor wir die Arten von Bäumen in der Datenstruktur verstehen, werden wir zunächst die Bäume in der Datenstruktur untersuchen. Der Baum im Computerfeld wird auch als Baum der realen Welt bezeichnet. Der Unterschied zwischen der realen Welt und dem Baum des Computerfelds besteht jedoch darin, dass er als verkehrt herum und als Wurzel darüber dargestellt wird und sich von der Wurzel zu den Blättern des Baums verzweigt. Unter verschiedenen realen Anwendungen wird die Baumdatenstruktur verwendet, da sie Beziehungen zwischen verschiedenen Knoten mit der Parent-Child-Hierarchie demonstrieren kann. Aus diesem Grund wird es auch als hierarchische Datenstruktur bezeichnet. Es ist am beliebtesten, um das Suchen und Sortieren zu vereinfachen und zu beschleunigen. Es gilt als eine der stärksten und fortschrittlichsten Datenstrukturen. Ein Baum ist eine Darstellung der nichtlinearen Datenstruktur. Ein Baum kann mit verschiedenen benutzerdefinierten oder primitiven Datentypen angezeigt werden. Wir können Arrays, Klassen verbundene Listen oder andere Arten von Datenstrukturen verwenden, um den Baum zu implementieren. Es ist eine Gruppe von Knoten, die miteinander verbunden sind. An den Rändern sind Knoten angebracht, um die Beziehung zu veranschaulichen.
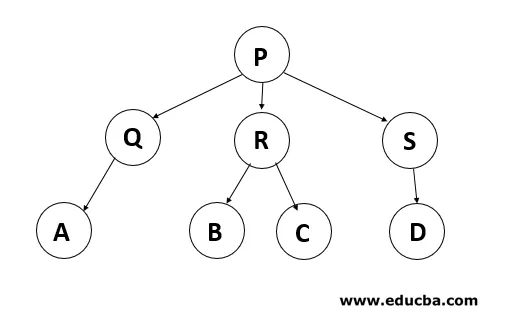
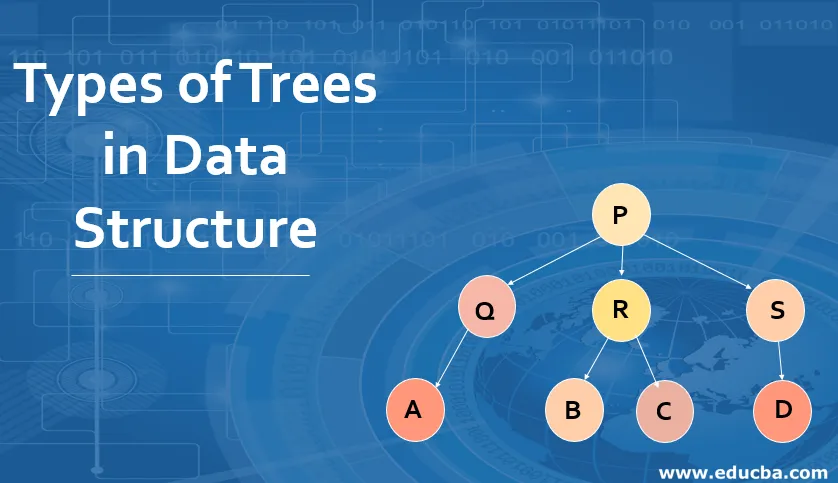
Beziehungen in einem Baum: In dem oben angegebenen Diagramm ist P die Wurzel des Baumes, außerdem ist P Eltern von Q, R und S. Q ist das Kind von P. Daher sind Q, R und S Geschwister. Während P Großeltern von A, B, C, D und E ist.
Was sind Bäume?
Ein Baum ist eine hierarchische Datenstruktur, in der die Informationen auf natürliche Weise hierarchisch gespeichert werden. Die Tree-Datenstruktur ist eine der effizientesten und ausgereiftesten. Die durch die Kanten verbundenen Knoten werden dargestellt.
Eigenschaften des Baums: Jeder Baum hat einen bestimmten Wurzelknoten. Jeder Baumknoten kann von einem Wurzelknoten gekreuzt werden. Es heißt Wurzel, da der Baum die einzige Wurzel war. Jedes Kind hat nur einen Elternteil, aber der Elternteil kann viele Kinder haben.
Baumarten in der Datenstruktur
Nachfolgend sind die Baumarten in einer Datenstruktur aufgeführt:
1. Allgemeiner Baum
Wenn die Hierarchie des Baums nicht eingeschränkt ist, wird ein Baum als allgemeiner Baum bezeichnet. Jeder Knoten kann unendlich viele untergeordnete Elemente in der allgemeinen Baumstruktur haben. Der Baum ist die Obermenge aller anderen Bäume.
2. Binärer Baum
Der binäre Baum ist die Art von Baum, in dem die meisten zwei Kinder für jedes Elternteil gefunden werden können. Die Kinder sind als linkes und rechtes Kind bekannt. Dies ist beliebter als die meisten anderen Bäume. Wenn bestimmte Einschränkungen und Merkmale in einem Binärbaum angewendet werden, wird auch eine Reihe anderer verwendet, z. B. AVL-Baum, BST (Binary Search Tree), RBT-Baum usw. Wenn wir fortfahren, werden wir all diese Stile im Detail erklären.
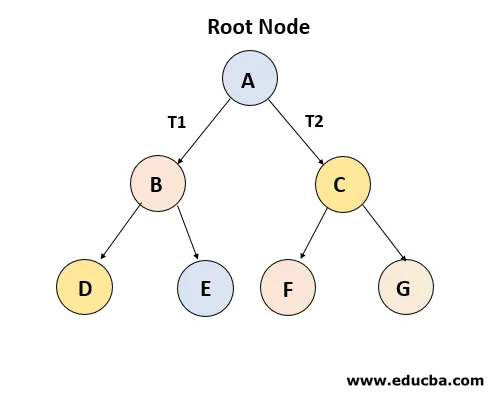
3. Binärer Suchbaum
Binary Search Tree (BST) ist eine binäre Baumerweiterung mit mehreren optionalen Einschränkungen. Der linke untergeordnete Wert eines Knotens sollte in BST kleiner oder gleich dem übergeordneten Wert sein und der rechte untergeordnete Wert sollte immer größer oder gleich dem übergeordneten Wert sein. Diese Eigenschaft des binären Suchbaums ist ideal für Suchvorgänge, da an jedem Knoten genau bestimmt werden kann, ob sich der Wert im linken oder rechten Teilbaum befindet. Aus diesem Grund wird der Suchbaum benannt.
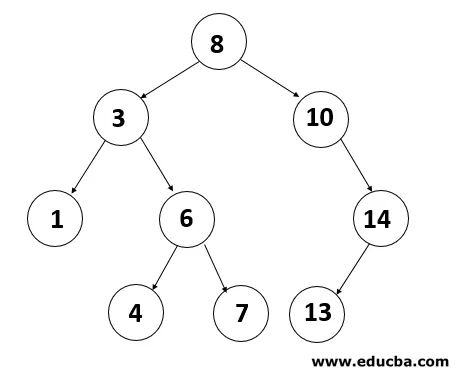
4. AVL-Baum
Der AVL-Baum ist ein binärer Suchbaum, der sich selbst ausbalanciert. Im Auftrag der Erfinder Adelson-Velshi und Landis wird der Name AVL vergeben. Dies war der erste Baum, der sich dynamisch ausbalancierte. Für jeden Knoten im AVL-Baum wird ein Ausgleichsfaktor zugewiesen, der davon abhängt, ob der Baum ausgeglichen ist oder nicht. Die Größe der Node Kids beträgt maximal 1. AVL Rebe. Im AVL-Baum ist der richtige Ausgleichsfaktor 1, 0 und -1. Wenn der Baum einen neuen Knoten hat, wird er gedreht, um sicherzustellen, dass der Baum ausgeglichen ist. Es wird dann gedreht. Gängige Vorgänge wie das Anzeigen, Einfügen und Entfernen benötigen im AVL-Baum eine Zeitspanne von 0 (log n). Es wird hauptsächlich beim Arbeiten mit Suchvorgängen angewendet.
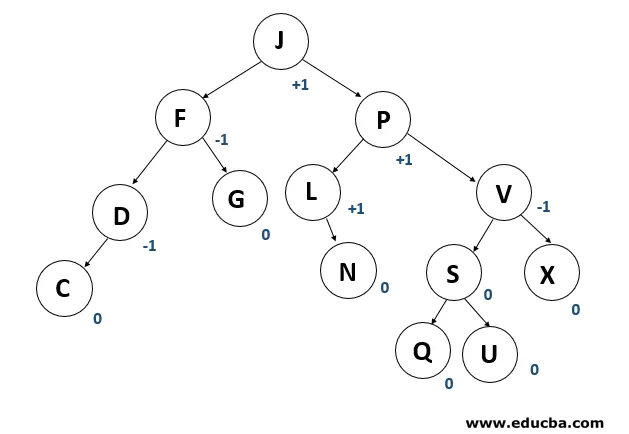
5. Rot-Schwarzer Baum
Eine andere Art von Auto-Balancing-Baum ist Rot-Schwarz. Der rot-schwarze Name wird angegeben, weil der rot-schwarze Baum je nach den Eigenschaften des rot-schwarzen Baums entweder rot oder schwarz auf jeden Knoten gemalt ist. Es hält das Gleichgewicht des Waldes. Obwohl dieser Baum kein vollständig ausgeglichener Baum ist, dauert die Suchoperation nur O (log n) Zeit. Wenn die neuen Knoten im Rot-Schwarz-Baum hinzugefügt werden, werden die Knoten erneut gedreht, um die Eigenschaften des Rot-Schwarz-Baums beizubehalten.
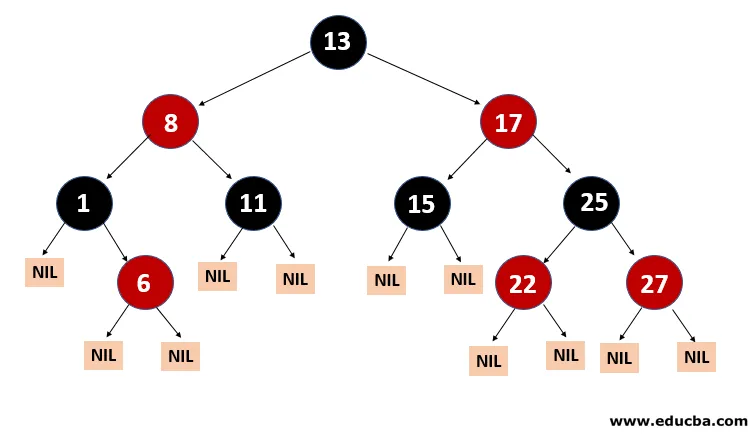
6. N-ary Baum
Die maximale Anzahl von Kindern in diesem Baumtyp, die einen Knoten haben können, ist N. Ein Binärbaum ist ein Zweijahresbaum, wie höchstens 2 Kinder in jedem Binärbaumknoten. Ein vollständiger N-ary-Baum ist ein Baum, in dem die Kinder eines Knotens entweder 0 oder N sind.
Vorteile von Tree
Jetzt werden wir die Vorteile von Tree verstehen:
- Der Baum spiegelt sich in den Datenstrukturverbindungen wider.
- Der Baum wird für die Hierarchie verwendet.
- Es bietet einen effizienten Such- und Einfügevorgang.
- Die Bäume sind flexibel. Dadurch können Teilbäume mit minimalem Aufwand verschoben werden.
Schlussfolgerung - Arten von Bäumen in der Datenstruktur
In diesem Artikel haben wir also gesehen, was Baumstruktur ist, welche Arten von Bäumen in der Datenstruktur vorhanden sind und welche Vorteile sie haben. Ich hoffe, Sie haben eine Vorstellung von einigen der häufigsten Bäume in der Struktur der Daten.
Empfohlene Artikel
Dies ist eine Anleitung zu Baumarten in der Datenstruktur. Hier diskutieren wir, was ist Bäume, 6 Arten von Bäumen in der Datenstruktur, mit Vorteilen. Sie können auch unsere anderen verwandten Artikel durchgehen, um mehr zu erfahren -
- AWS-Datenpipeline
- Oracle Data Warehousing
- Mehrdimensionale Datenbank
- Fragen im Vorstellungsgespräch zu Data Structure Java