
Was ist der SVM-Algorithmus?
SVM steht für Support Vector Machine. SVM ist ein beaufsichtigter Algorithmus für maschinelles Lernen, der häufig für Klassifizierungs- und Regressionsaufgaben verwendet wird. Häufige Anwendungen des SVM-Algorithmus sind Intrusion Detection System, Handschrifterkennung, Proteinstrukturvorhersage, Erkennung der Steganographie in digitalen Bildern usw.
Im SVM-Algorithmus wird jeder Punkt als Datenelement im n-dimensionalen Raum dargestellt, wobei der Wert jedes Features der Wert einer bestimmten Koordinate ist.
Nach dem Plotten wurde die Klassifizierung durchgeführt, indem eine Übertreibungsebene gefunden wurde, die zwei Klassen unterscheidet. Lesen Sie das folgende Bild, um dieses Konzept zu verstehen.
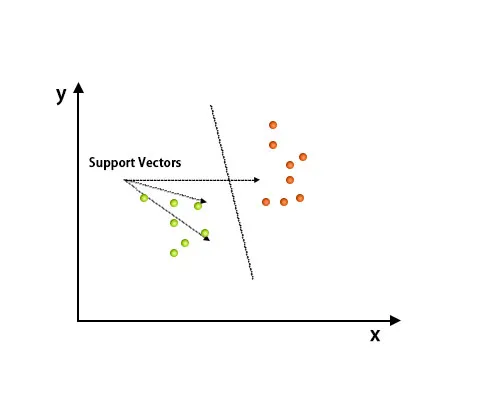
Der Support Vector Machine-Algorithmus wird hauptsächlich zur Lösung von Klassifizierungsproblemen verwendet. Unterstützungsvektoren sind nichts anderes als die Koordinaten jedes Datenelements. Support Vector Machine ist eine Grenze, die zwei Klassen mithilfe der Hyperebene unterscheidet.
Wie funktioniert der SVM-Algorithmus?
Im obigen Abschnitt haben wir die Unterscheidung zweier Klassen mit Hilfe der Hyperebene erörtert. Nun werden wir sehen, wie dieser SVM-Algorithmus tatsächlich funktioniert.
Szenario 1: Identifizieren Sie die rechte Hyperebene
Hier haben wir drei Hyperebenen genommen, nämlich A, B und C. Jetzt müssen wir die richtige Hyperebene identifizieren, um Stern und Kreis zu klassifizieren.
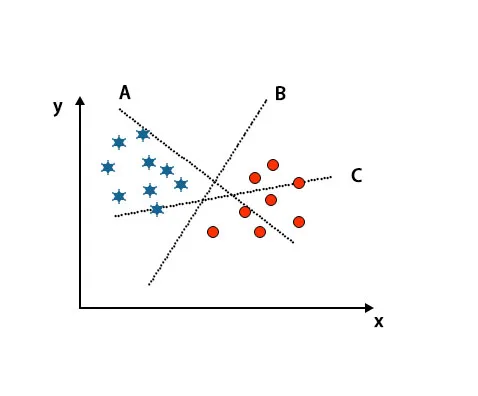
Um die richtige Hyperebene zu identifizieren, sollten wir die Daumenregel kennen. Wählen Sie eine Hyperebene, die zwei Klassen unterscheidet. In dem oben erwähnten Bild unterscheidet die Hyperebene B zwei Klassen sehr gut.
Szenario 2: Identifizieren Sie die rechte Hyperebene
Hier haben wir drei Hyperebenen genommen, dh A, B und C. Diese drei Hyperebenen unterscheiden Klassen bereits sehr gut.
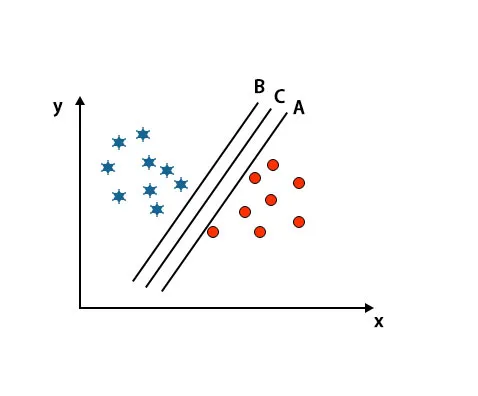
In diesem Szenario erhöhen wir den Abstand zwischen den nächsten Datenpunkten, um die richtige Hyperebene zu identifizieren. Diese Distanz ist nichts anderes als ein Spielraum. Siehe Bild unten.
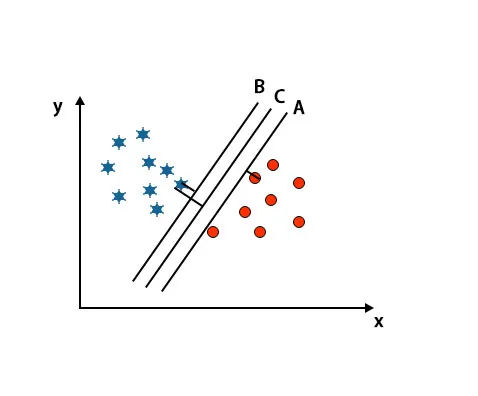
In dem oben erwähnten Bild ist der Rand der Hyperebene C höher als die Hyperebene A und die Hyperebene B. In diesem Szenario ist C also die rechte Hyperebene. Wenn wir die Hyperebene mit einem Mindestspielraum wählen, kann dies zu einer Fehlklassifizierung führen. Daher haben wir uns wegen der Robustheit für die Hyperebene C mit maximalem Abstand entschieden.
Szenario 3: Identifizieren Sie die rechte Hyperebene
Hinweis: Um die Hyperebene zu identifizieren, befolgen Sie die gleichen Regeln wie in den vorherigen Abschnitten.
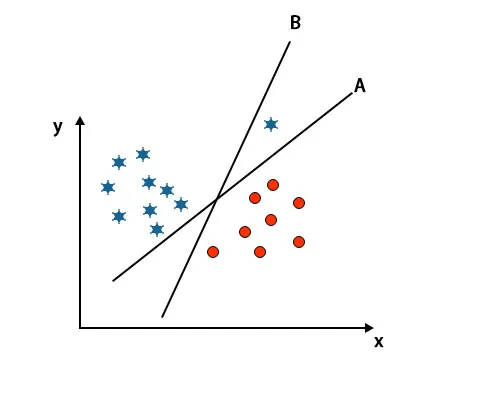
Wie Sie in dem oben erwähnten Bild sehen können, ist der Rand der Hyperebene B höher als der Rand der Hyperebene A, weshalb einige die Hyperebene B als rechts auswählen. Im SVM-Algorithmus wird jedoch die Hyperebene ausgewählt, die die Klassen vor dem Maximieren des Spielraums genau klassifiziert. In diesem Szenario hat die Hyperebene A alle genau klassifiziert, und es gibt einen Fehler bei der Klassifizierung der Hyperebene B. Daher ist A die richtige Hyperebene.
Szenario 4: Klassifizieren Sie zwei Klassen
Wie Sie in der folgenden Abbildung sehen können, können wir zwei Klassen nicht durch eine gerade Linie unterscheiden, da ein Stern als Ausreißer in der anderen Kreisklasse liegt.
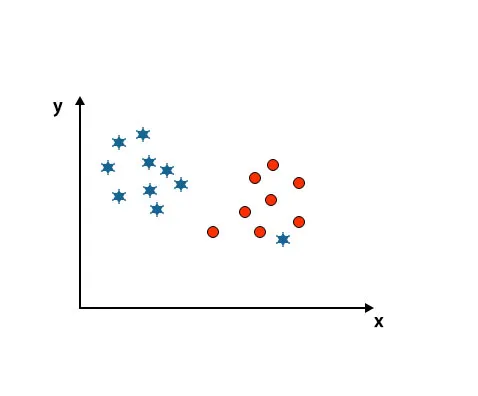
Hier ist ein Stern in einer anderen Klasse. Für die Sternenklasse ist dieser Stern der Ausreißer. Aufgrund der Robustheitseigenschaft des SVM-Algorithmus wird die richtige Hyperebene mit höherem Rand gefunden, wobei ein Ausreißer ignoriert wird.
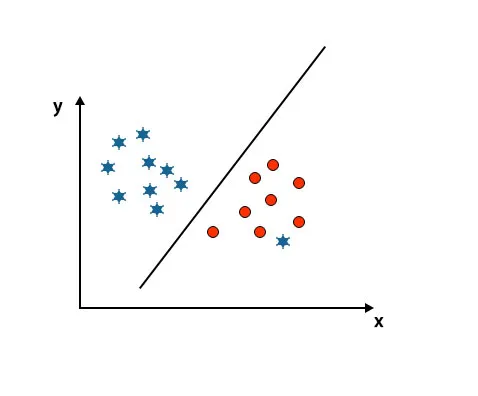
Szenario 5: Feine Hyperebene zur Unterscheidung von Klassen
Bis jetzt haben wir lineare Hyperebene geschaut. In der folgenden Abbildung haben wir keine lineare Hyperebene zwischen Klassen.
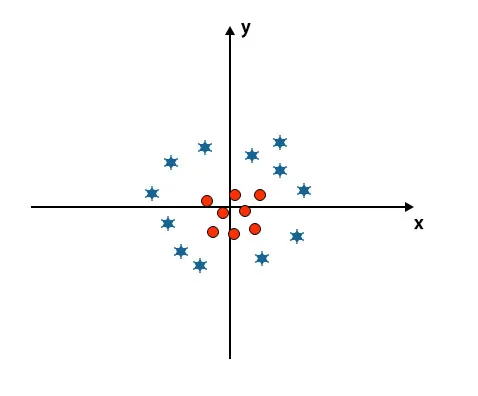
Um diese Klassen zu klassifizieren, führt SVM einige zusätzliche Funktionen ein. In diesem Szenario verwenden wir diese neue Funktion z = x 2 + y 2.
Zeichnet alle Datenpunkte auf der x- und z-Achse.

Hinweis
- Alle Werte auf der z-Achse sollten positiv sein, da z gleich der Summe von x-Quadrat und y-Quadrat ist.
- In der oben erwähnten Darstellung sind rote Kreise um den Ursprung der x- und y-Achse geschlossen, wobei der Wert von z nach unten führt und der Stern genau das Gegenteil des Kreises ist, er ist vom Ursprung der x-Achse entfernt und y-Achse, die den Wert von z zu hoch führt.
Im SVM-Algorithmus ist es einfach, mithilfe einer linearen Hyperebene zwischen zwei Klassen zu klassifizieren. Hier stellt sich jedoch die Frage, ob wir dieses Merkmal von SVM hinzufügen sollten, um die Hyperebene zu identifizieren. Die Antwort lautet also nein, um dieses Problem zu lösen, hat SVM eine Technik, die allgemein als Kernel-Trick bekannt ist.
Kernel-Trick ist die Funktion, die Daten in eine geeignete Form umwandelt. Es gibt verschiedene Arten von Kernelfunktionen, die im SVM-Algorithmus verwendet werden, z. B. Polynom, Linear, Nichtlinear, Radiale Basisfunktion usw. Hier wird mithilfe des Kernel-Tricks der niedrigdimensionale Eingaberaum in einen höherdimensionalen Raum konvertiert.
Wenn wir die Hyperebene als Ursprung der Achse und der y-Achse betrachten, sieht sie wie ein Kreis aus. Siehe Bild unten.
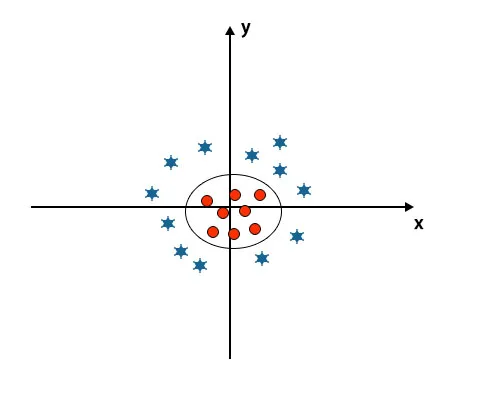
Vorteile des SVM-Algorithmus
- Auch wenn Eingabedaten nicht linear und nicht trennbar sind, generieren SVMs aufgrund ihrer Robustheit genaue Klassifizierungsergebnisse.
- In der Entscheidungsfunktion verwendet es eine Untermenge von Trainingspunkten, die als Unterstützungsvektoren bezeichnet werden, und ist daher speichereffizient.
- Es ist nützlich, komplexe Probleme mit einer geeigneten Kernelfunktion zu lösen.
- In der Praxis werden SVM-Modelle verallgemeinert, wobei das Risiko einer Überanpassung in SVM geringer ist.
- SVMs eignen sich hervorragend für die Textklassifizierung und zum Ermitteln des besten linearen Trennzeichens.
Nachteile des SVM-Algorithmus
- Bei der Arbeit mit großen Datenmengen ist eine lange Einarbeitungszeit erforderlich.
- Das endgültige Modell und die individuellen Auswirkungen sind schwer zu verstehen.
Fazit
Es wurde zur Unterstützung des Vektormaschinenalgorithmus geführt, der ein Algorithmus zum maschinellen Lernen ist. In diesem Artikel haben wir erläutert, was der SVM-Algorithmus ist, wie er funktioniert und welche Vorteile er im Detail hat.
Empfohlene Artikel
Dies war eine Anleitung zum SVM-Algorithmus. Hier diskutieren wir die Arbeit mit einem Szenario, Vor- und Nachteilen des SVM-Algorithmus. Sie können sich auch die folgenden Artikel ansehen, um mehr zu erfahren -
- Data Mining-Algorithmen
- Data Mining-Techniken
- Was ist maschinelles Lernen?
- Werkzeuge für maschinelles Lernen
- Beispiele für den C ++ - Algorithmus