

Was ist eine Bienenstockfunktion?
Wie wir heute wissen, ist Hadoop eine der vielseitigsten Technologien für Big Data. Hadoop ist in der Lage, mit großen Datenmengen umzugehen, aber da das Datenwachstum proportional ist, wird das Schreiben von Programmen zur Kartenreduzierung schwierig. Zur Ausführung von SQL-Abfragen, die in HDFS vorhanden sind, wurde von Hadoop eine solche Technologie namens Apache Hive eingeführt, die von Facebook gestartet wurde. Hive wird vom Datenanalysten in hohem Maße genutzt. Sie werden für drei Funktionen bereitgestellt: Datenzusammenfassung, Datenanalyse für verteilte Dateien und Datenabfrage. Hive bietet SQL-ähnliche Abfragen, die als HQL bezeichnet werden. Die Sprache für hohe Abfragen unterstützt benutzerdefinierte DML-Funktionen. Der Hive-Compiler konvertiert diese Abfrage intern in Map-Reduction-Jobs, was die Arbeit von Hadoop beim Schreiben komplexer Programme vereinfacht. Wir konnten eine Vielzahl von Anwendungen wie Data Warehousing, Datenvisualisierung und Ad-hoc-Analyse sowie Google Analytics finden. Der Hauptvorteil besteht darin, dass sie SQL-Kenntnisse nutzen, eine grundlegende Fähigkeit, die von Datenwissenschaftlern und Softwareprofis eingesetzt wird.
Verschiedene Hive-Funktionen im Detail
Hive unterstützt verschiedene Datentypen, die in anderen Datenbanksystemen nicht vorhanden sind. Es enthält eine Karte, ein Array und eine Struktur. Hive verfügt über einige integrierte Funktionen, mit denen verschiedene mathematische und arithmetische Funktionen für einen bestimmten Zweck ausgeführt werden können. Funktionen in Hive können in die folgenden Typen eingeteilt werden. Sie sind eingebaute Funktionen und benutzerdefinierte Funktionen.
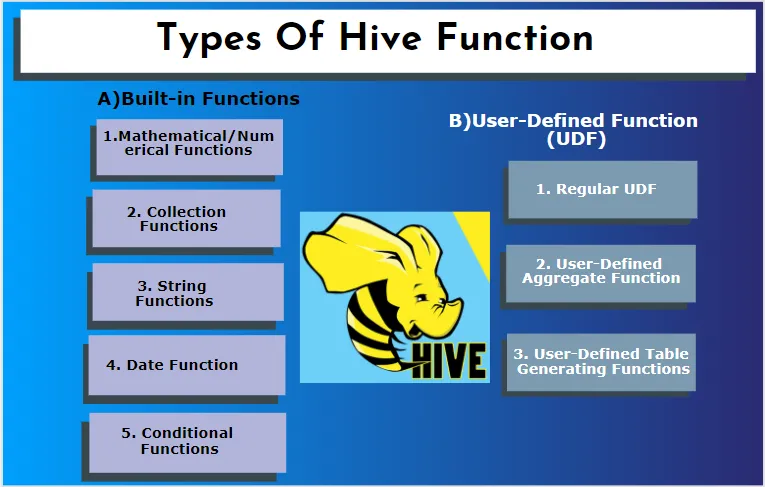
A) Eingebaute Funktionen
Diese Funktionen extrahieren Daten aus den Hive-Tabellen und verarbeiten die Berechnungen. Einige der eingebauten Funktionen sind:
1. Mathematische / Numerische Funktionen
Diese Funktionen werden hauptsächlich für mathematische Berechnungen verwendet. Diese Funktionen werden in SQL-Abfragen verwendet.
| Funktionsname | Beispiel | Beschreibung |
| ABS (doppelt x) | Bienenstock> ABS (-200) aus tmp auswählen; | Es wird der absolute Wert einer Zahl zurückgegeben. |
| CEIL (doppelt x) | Bienenstock> wählen Sie CEIL (8.5) aus tmp; | Es wird die kleinste Ganzzahl abgerufen, die größer oder gleich dem Wert x ist. |
| Rand (), rand (int seed) | Hive> wähle Rand () aus tmp;
Rand (0-9) | Es gibt eine Zufallszahl zurück, abhängig vom Startwert wären die generierten Zufallszahlen deterministisch. |
| Pow (doppeltes x, doppeltes y) | Hive> wähle Pow (5, 2) aus tmp; | Es gibt den x-Wert zurück, der auf die y-Potenz angehoben wird. |
| BODEN (Doppel y) | Bienenstock> wählen Sie BODEN (11.8) aus tmp; | Es gibt eine maximale Ganzzahl zurück, die kleiner oder gleich dem Wert y ist. |
| EXP (doppelt a) | Hive> wähle Exp (30) von tmp; | Es wird der Exponentenwert von 30 zurückgegeben. Die natürlichen Algorithmuswerte. |
| PMOD (int a, int b) | Bienenstock> PMOD (2, 4) aus tmp auswählen; | Es gibt den positiven Modul der Zahl. |
2. Erfassungsfunktionen
Das Zusammenführen aller Elemente und das Zurückgeben einzelner Elemente hängt vom enthaltenen Datentyp ab.
| Funktionsname | Beispiel | Beschreibung |
| Kartenwerte (Karte) | Bienenstock> Kartenwerte auswählen ('hi', 45) | Es werden ungeordnete Array-Elemente abgerufen. |
| Größe (Karte) | Bienenstock> Größe auswählen (Karte) | Gibt die Anzahl der Elemente in der Datentypzuordnung zurück. |
| Array_contains (Array b) | Hive> Array_contains auswählen (a (10)) | Gibt TRUE zurück, wenn das Array den Wert enthält. |
| Sort_array (Array a) | Hive> select sort_array ((10, 3, 6, 1, 7)) | Sortiert das Eingabearray in aufsteigender Reihenfolge nach der natürlichen Reihenfolge der Array-Elemente und gibt den Wert zurück. |
3. String-Funktionen
Mit Hilfe von String-Funktionen wird die Datenanalyse hervorragend durchgeführt.
| Split (Zeichenfolge s, Zeichenfolge pat) | Bienenstock> Split-Ausgabe ('educba ~ hive ~ Hadoop, ' ~ ') auswählen: ("educba", "hive", "Hadoop") | Es teilt den String um pat-Ausdrücke auf und gibt ein Array zurück. |
| Laden (String s, int Len, String Pad) | Bienenstock> Last auswählen ('EDUCBA', 6, 'H') | Es werden Zeichenfolgen mit dem richtigen Abstand zur Länge der Zeichenfolge zurückgegeben. (Pad-Zeichen). |
| Länge (string str) | Bienenstock> Länge auswählen ('educba') | Diese Funktion gibt die Länge der Zeichenkette zurück. |
| Rtrim (String a) | Hive> wähle rtrim ('THEMA');
Ausgabe: 'Topic' | Das Ergebnis wird zurückgegeben, indem Leerzeichen an den rechten Enden abgeschnitten werden. |
| Concat (Saite m, Saite n) | Hive> select concat ('data', 'ware') Ergebnis: Dataware | Es ergibt sich die Zeichenfolge durch Verkettung von zwei Zeichenfolgen, dies kann eine beliebige Anzahl von Eingaben annehmen. |
| Reverse (Zeichenfolge s) | Bienenstock> Rückwärts wählen ('Mobil') | Gibt das Ergebnis einer umgekehrten Zeichenfolge zurück. |
4. Datumsfunktion
Das Datenformat muss in der Struktur vorhanden sein, um Null-Fehler in der Ausgabe zu vermeiden. Es ist erforderlich, dass das Datum kompatibel ist, um die eingeführten Datumsfunktionen nutzen zu können.
| Unix_timestamp (String date, string pattern) | Struktur> Unix_-Zeitstempel auswählen ('2019-06-08', 'JJJJ-MM-TT'); Ergebnis: 124576 400 Zeitaufwand: 0.146 Sekunden | Diese Funktion gibt das Datum in dem bestimmten Format und die Sekunden zwischen Datum und Unix-Zeit zurück. |
| Unix_timestamp (String date) | Bienenstock> Unix_-Zeitstempel auswählen ('2019-06-08 09:20:10', 'JJJJ-MM-TT'); | Es gibt das Datum im Format 'JJJJ-MM-TT HH: MM: SS' in den Unix-Zeitstempel zurück. |
| Stunde (Streichdatum) | Bienenstock> Stunde auswählen ('2019-06-08 09:20:10'); Ergebnis: 09 Stunden | Es gibt die Zeitstempelstunde zurück |
5. Bedingte Funktionen
| If (Boolescher Test, T-Wert true, t false) | Hive> wähle IF (1 = 1, 'TRUE', 'FALSE') als IF_CONDITION_TEST; | Es wird mit der Bedingung überprüft, ob der Wert true 1 und false 0 zurückgibt. |
| Ist nicht null (b) | Hive> Select ist nicht null (null); | Hiermit werden keine NULL-Anweisungen abgerufen. Wenn null, wird false zurückgegeben. |
| Verschmelzen (Wert1, Wert2) | Beispiel: hive> select coalesce (Null, Null, 4, Null, 6). es gibt 4 zurück. | Es ruft zunächst nicht null Werte aus der Werteliste ab. |
B) Benutzerdefinierte Funktion (UDF)
Hive verwendet benutzerspezifische Funktionen gemäß den Clientanforderungen, die in der Java-Programmierung geschrieben wurden. Es wird durch zwei Schnittstellen implementiert, nämlich eine einfache API und eine komplexe API. Sie werden aus der Hive-Abfrage aufgerufen. Drei Arten von UDFs:
1. Regelmäßige UDF
Es funktioniert auf einer Tabelle mit einer einzelnen Zeile. Es wird erstellt, indem eine Java-Klasse erstellt und dann in eine .jar-Datei gepackt wird. Der nächste Schritt ist die Überprüfung mit einem Hive-Klassenpfad. Führen Sie sie anschließend in einer Hive-Abfrage aus.
2. Benutzerdefinierte Aggregatfunktion
Sie verwenden Aggregatfunktionen wie avg / mean, indem sie fünf Methoden init (), iterate (), partial (), merge () und terminate () implementieren.
3. Benutzerdefinierte Tabellenerstellungsfunktionen
Es arbeitet mit einer einzelnen Zeile in einer Tabelle und führt zu mehreren Zeilen.
Fazit
Abschließend haben wir in diesem Artikel im Detail gelernt, wie man in der Hive-Plattform mit integrierten Funktionen und benutzerdefinierten Funktionen arbeitet. Die meisten Organisationen haben Programmierer und SQL-Entwickler, die am serverseitigen Prozess arbeiten. Ein Apache-Hive ist jedoch ein leistungsstarkes Tool, mit dem sie Hadoop-Framework ohne Vorkenntnisse zu Programmen und Kartenreduzierung verwenden können. Hive hilft neuen Benutzern, die Datenanalyse ohne Hindernisse zu starten und zu erkunden.
Empfohlene Artikel
Dies ist eine Anleitung zur Hive-Funktion. Hier diskutieren wir das Konzept, zwei verschiedene Arten von Funktionen und Unterfunktionen in Hive. Sie können auch unsere anderen Artikelvorschläge durchgehen, um mehr zu erfahren -
- Top-String-Funktionen in Hive
- Fragen im Vorstellungsgespräch bei Hive
- Was ist RMAN Oracle?
- Was ist ein Wasserfallmodell?
- Einführung in die Hive-Architektur
- Hive Order By