

Einführung in Pig-Befehle
Apache Pig ist ein Tool / eine Plattform, mit der große Datenmengen analysiert und lange Datenoperationen durchgeführt werden können. Schwein wird mit Hadoop verwendet. Alle Pig-Skripte werden intern in Map-Reduction-Tasks konvertiert und dann ausgeführt. Es kann strukturierte, semi-strukturierte und unstrukturierte Daten verarbeiten. Schwein speichert das Ergebnis in HDFS. In diesem Artikel erfahren Sie mehr über die verschiedenen Arten von Pig-Befehlen.
Hier sind einige Eigenschaften von Pig:
- Selbstoptimierend: Pig kann die Ausführungsjobs optimieren, der Benutzer hat die Freiheit, sich auf die Semantik zu konzentrieren.
- Einfaches Programmieren: Pig bietet eine Hochsprache / einen Hochdialekt, bekannt als Pig Latin, die / der einfach zu schreiben ist. Pig Latin bietet viele Operatoren, mit denen der Programmierer die Daten verarbeiten kann. Der Programmierer hat die Flexibilität, auch seine eigenen Funktionen zu schreiben.
- Erweiterbar: Pig erleichtert die Erstellung von benutzerdefinierten Funktionen, die als UDFs (User defined functions) bezeichnet werden und es Programmierern ermöglichen, jede Verarbeitungsanforderung schnell und einfach zu erfüllen. Pig Script läuft auf einer Shell, die als Grunzen bekannt ist.
Warum Schweinebefehle?
Programmierer, die mit Java nicht gut umgehen können, haben normalerweise Schwierigkeiten, Programme in Hadoop zu schreiben, dh Aufgaben mit reduzierter Kartengröße zu schreiben. Für sie ist Pig Latin, das der SQL-Sprache sehr ähnlich ist, ein Segen. Sein Ansatz mit mehreren Abfragen reduziert die Länge des Codes.
Insgesamt also seine prägnante und effektive Art der Programmierung. Pig-Befehle können Code in vielen Sprachen wie JRuby, Jython und Java aufrufen.
Die Architektur von Pig-Befehlen
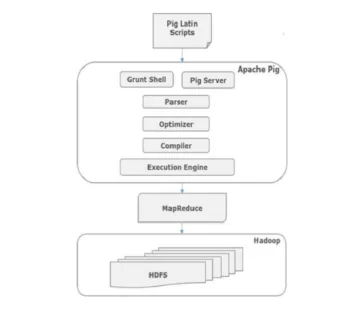
Alle Skripte, die in Pig-Latin über die Grunt-Shell geschrieben wurden, gehen an den Parser, um die Syntax zu überprüfen. Die Ausgabe des Parsers ist eine DAG. Diese DAG wird dann an den Optimierer übergeben, der dann eine logische Optimierung wie z. B. Projektion und Pushdown durchführt. Der Compiler erfüllt dann den logischen Plan für MapReduce-Jobs. Schließlich werden diese MapReduce-Jobs in sortierter Reihenfolge an Hadoop übergeben. Diese Jobs werden ausgeführt und führen zu den gewünschten Ergebnissen.
Das Pig-Latin-Datenmodell ist vollständig verschachtelt und ermöglicht komplexe Datentypen wie Map und Tupel.
Jeder einzelne Wert der lateinischen Sprache Pig (unabhängig vom Datentyp) wird als Atom bezeichnet.
Grundlegende Pig-Befehle
Werfen wir einen Blick auf einige der folgenden Basic Pig-Befehle:
1. Fs: Dies listet alle Dateien im HDFS auf
grunzen> fs –ls
2. Clear: Hiermit wird die interaktive Grunt-Shell gelöscht.
grunzen> klar
3. Geschichte:
Dieser Befehl zeigt die bisher ausgeführten Befehle an.
grunzen> geschichte
4. Lesen von Daten: Angenommen, die Daten befinden sich in HDFS, und wir müssen Daten in Pig lesen.
grunt> college_students = LOAD 'hdfs: // localhost: 9000 / pig_data / college_data.txt'
USING PigStorage (', ')
as (id: int, vorname: chararray, nachname: chararray, telefon: chararray,
Stadt: Chararray);
PigStorage () ist die Funktion, die Daten als strukturierte Textdateien lädt und speichert.
5. Speichern von Daten: Mit dem Operator Speichern werden die verarbeiteten / geladenen Daten gespeichert.
grunt> STORE college_students INTO 'hdfs: // localhost: 9000 / pig_Output /' USING PigStorage (', ');
Hier ist "/ pig_Output /" das Verzeichnis, in dem die Beziehung gespeichert werden muss.
6. Dump Operator: Mit diesem Befehl werden die Ergebnisse auf dem Bildschirm angezeigt. Es hilft normalerweise beim Debuggen.
grunzen> Dump college_students;
7. Operator beschreiben: Er hilft dem Programmierer, das Schema der Beziehung anzuzeigen.
grunzen> beschreiben college_students;
8. Erklären: Mit diesem Befehl können Sie die logischen, physischen und Map-reduzierten Ausführungspläne überprüfen.
grunzen> college_students erklären;
9. Operator veranschaulichen: Dies ermöglicht die schrittweise Ausführung von Anweisungen in Pig-Befehlen.
grunzen> illustriere college_students;
Intermediate Pig-Befehle
1. Group: Mit diesem Pig-Befehl können Sie Daten mit demselben Schlüssel gruppieren.
grunt> group_data = GROUP college_students nach Vorname;
2. COGROUP: Funktioniert ähnlich wie der Gruppenoperator. Der Hauptunterschied zwischen Gruppen- und Cogroup-Operatoren besteht darin, dass Gruppenoperatoren normalerweise mit einer Beziehung verwendet werden, während Cogroup mit mehr als einer Beziehung verwendet wird.
3. Join: Hiermit werden zwei oder mehr Relationen kombiniert.
Beispiel: Um eine Selbstverknüpfung durchzuführen, wird die Beziehung "customer" aus HDFS-tp-pig-Befehlen in zwei Beziehungen customers1 und customers2 geladen.
grunt> customers3 = JOIN customers1 BY id, customers2 BY id;
Join kann Self-Join, Inner-Join, Outer-Join sein.
4. Kreuz: Dieser Molch-Befehl berechnet das Kreuzprodukt von zwei oder mehr Relationen.
grunt> cross_data = CROSS Kunden, Bestellungen;
5. Union: Es verschmilzt zwei Beziehungen. Voraussetzung für das Zusammenführen ist, dass sowohl die Spalten als auch die Domänen der Beziehung identisch sind.
grunzen> student = UNION student1, student2;
Erweiterte Pig-Befehle
Werfen wir einen Blick auf einige der erweiterten Pig-Befehle, die unten aufgeführt sind:
1. Filter: Dies hilft, die Tupel basierend auf bestimmten Bedingungen aus der Beziehung herauszufiltern.
filter_data = FILTER college_students BY city == 'Chennai';
2. Distinct: Dies hilft beim Entfernen redundanter Tupel aus der Relation.
grunzen> distinct_data = DISTINCT college_students;
Durch diese Filterung wird der neue Beziehungsname "distinct_data" erstellt.
3. Foreach: Dies hilft bei der Generierung einer Datentransformation basierend auf Spaltendaten.
grunzen> foreach_data = FOREACH student_details GENERATE id, age, city;
Dadurch werden die Werte für ID, Alter und Stadt jedes Schülers aus der Beziehung student_details abgerufen und in einer anderen Beziehung mit dem Namen foreach_data gespeichert.
4. Sortieren nach: Dieser Befehl zeigt das Ergebnis in einer sortierten Reihenfolge an, die auf einem oder mehreren Feldern basiert.
grunt> order_by_data = ORDER college_students NACH Alter DESC;
Dadurch wird die Beziehung "college_students" in absteigender Reihenfolge nach Alter sortiert.
5. Limit: Dieser Befehl wird limitiert. Tupel aus der Relation.
grunzen> limit_data = LIMIT student_details 4;
Tipps und Tricks
Nachfolgend sind die verschiedenen Tipps und Tricks der Pig-Befehle aufgeführt:
1. Aktivieren Sie die Komprimierung für Ihre Ein- und Ausgabe:
set input.compression.enabled true;
set output.compression.enabled true;
Die oben genannten Codezeilen müssen sich am Anfang des Skripts befinden, damit Pig-Befehle komprimierte Dateien lesen oder komprimierte Dateien als Ausgabe generieren können.
2. Verbinden Sie mehrere Beziehungen:
Für die Ausführung des Links-Joins für beispielsweise drei Relationen (Eingabe1, Eingabe2, Eingabe3) muss SQL ausgewählt werden. Dies liegt daran, dass der äußere Join von Pig nicht für mehr als zwei Tabellen unterstützt wird.
Vielmehr führen Sie links, um in zwei Schritten beizutreten, wie:
data1 = JOIN Eingabe1 BY- Taste LINKS, Eingabe2 BY- Taste;
data2 = JOIN data1 BY input1 :: key LEFT, input3 BY key;
Dies bedeutet zwei Aufträge zur Kartenreduzierung.
Um die oben genannte Aufgabe effektiver auszuführen, kann man sich für "Cogroup" entscheiden. Cogroup kann mehreren Beziehungen beitreten. Cogroup führt standardmäßig einen Outer Join durch.
Fazit
Pig ist eine prozedurale Sprache, die im Allgemeinen von Datenwissenschaftlern zur Durchführung von Ad-hoc-Verarbeitung und schnellem Prototyping verwendet wird. Es ist ein großartiges ETL- und Big-Data-Verarbeitungswerkzeug. Pig-Skripte können von anderen Sprachen aufgerufen werden und umgekehrt. Daher können Pig-Befehle verwendet werden, um größere und komplexere Anwendungen zu erstellen.
Empfohlene Artikel
Dies war eine Anleitung für Pig-Befehle. Hier haben wir grundlegende sowie erweiterte Pig-Befehle und einige unmittelbare Pig-Befehle besprochen. Sie können auch den folgenden Artikel lesen, um mehr zu erfahren -
- Adobe Photoshop-Befehle
- Tableau-Befehle
- Spickzettel SQL (Befehle, kostenlose Tipps und Tricks)
- VBA-Befehle zum Abschluss
- Verschiedene Operationen in Bezug auf Tupel