

Was ist Big Data und Hadoop?
Die Daten wachsen von Tag zu Tag exponentiell und mit diesen Daten wächst auch die Notwendigkeit, diese Daten zu nutzen. Wie früher hatten wir Diskettenlaufwerke zum Speichern von Daten und die Datenübertragung war ebenfalls langsam, aber heutzutage sind diese unzureichend und der Cloud-Speicher wird verwendet, da wir Terabytes an Daten haben. In der heutigen Welt tragen soziale Medien am meisten zum Datenwachstum bei. Es besteht aus Verhalten, Denkweise und einigen anderen Aspekten der Menschen. Es wird gesagt, dass in jeder Minute 300 Stunden Video auf YouTube hochgeladen werden, über 20 Millionen Fotos auf Facebook und viele andere hochgeladen werden. Darüber hinaus gibt es keine ordnungsgemäße Struktur der hochgeladenen Daten, was die größte Herausforderung für die Verarbeitung dieser Daten darstellt.
Da enorme Datenmengen mit hoher Geschwindigkeit generiert werden, waren herkömmliche RDBMS-Systeme nicht in der Lage, dieses rasante Wachstum zu bewältigen. Darüber hinaus sind sie auch nicht in der Lage, unstrukturierte Daten zu verarbeiten. Es wurde sehr schwierig, mit einer so großen Menge heterogener Daten, die schnell wuchsen, umzugehen und diese Daten mit hoher Verarbeitungsgeschwindigkeit zu verarbeiten. Daher bestand ein Bedürfnis nach einem solchen System, das große Datenmengen effizient handhaben kann. Um das Szenario zu lösen, entstand Hadoop. HDFS ist die Komponente von Hadoop, die das Speicherproblem des großen Datasets mithilfe von verteiltem Speicher behebt, während YARN die Komponente ist, die das Verarbeitungsproblem behebt und die Verarbeitungszeit drastisch verkürzt.
Hadoop ist ein Open-Source-Software-Framework zum Speichern und Verarbeiten großer Datenmengen unter Verwendung eines verteilten großen Clusters von Standardhardware. Es wurde von Doug Cutting und Michael J. Cafarella entwickelt und unter Apache lizensiert. Es wurde mit Java geschrieben und basiert auf der Arbeit von Google über das MapReduce-System. Es wendet Konzepte der funktionalen Programmierung an. Es ist zuverlässig, wirtschaftlich, flexibel und skalierbar.
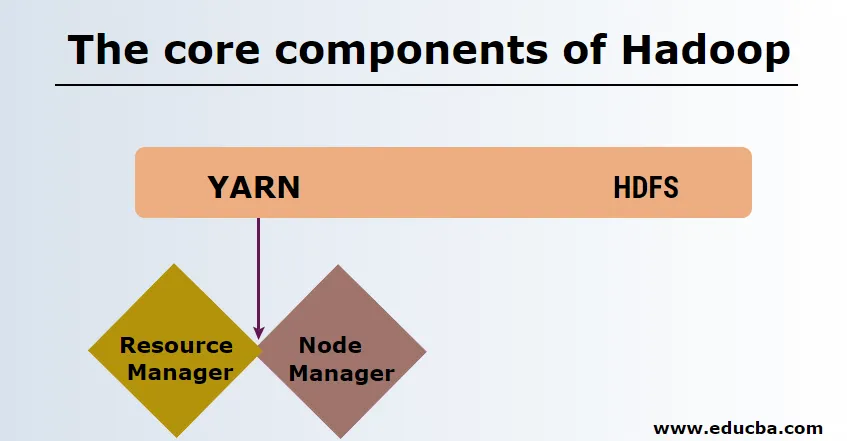
Die Kernkomponenten von Hadoop
Die Kernkomponenten von Hadoop sind wie folgt
-
HDFS
HDFS oder Hadoop Distributed File System haben Namenode und Datenknoten. Namenode ist der Masterknoten, auf dem der Master-Daemon ausgeführt wird. Er verwaltet die Datenknoten und protokolliert alle Vorgänge. Datenknoten sind die Slaves, in denen die Daten tatsächlich gespeichert werden.
-
GARN
YARN besteht aus zwei Hauptkomponenten:
1. ResourceManager: Läuft auf dem Masterknoten und verwaltet alle Ressourcen und plant alle Anwendungen. Es verfügt über Scheduler & ApplicationManager.
2. NodeManager: Er wird auf jedem Slave-Knoten ausgeführt und ist für die Verwaltung der Container und die Überwachung der Ressourcennutzung verantwortlich.
Mehrere Komponenten von Hadoop
Es gibt verschiedene Bestandteile von Hadoop, wie das Schwein, den Bienenstock, den Sqoop, die Rinne, den Mahout, das Oozie, den Tierpfleger, die HBase usw.
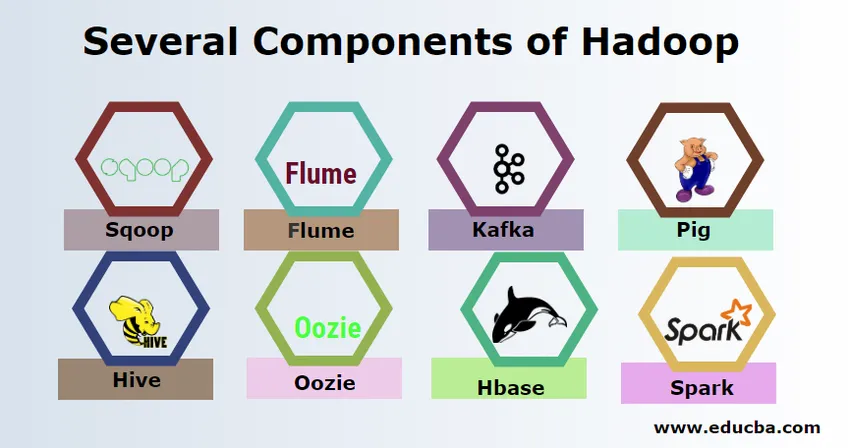
- Sqoop - Wird zum Importieren und Exportieren von Daten aus RDBMS nach Hadoop und umgekehrt verwendet.
- Flume - Es wird zum Abrufen von Echtzeitdaten in Hadoop verwendet.
- Kafka - Hierbei handelt es sich um ein Nachrichtensystem, mit dem Echtzeitdaten an Hadoop weitergeleitet werden.
- Schwein - Es wird als Skriptsprache für die Datenverarbeitung verwendet.
- Hive - Es handelt sich um ein auf HDFS basierendes Data Warehousing-Framework, mit dem Benutzer, die mit SQL vertraut sind, Abfragen ausführen können, um die Daten abzurufen. Diese Abfragen heißen HiveQL.
- Oozie - Es wird verwendet, um den Workflow von Jobs so zu planen, dass sie zu bestimmten Ereignissen oder Zeitpunkten ausgeführt werden.
- Hbase - Dies ist die No-SQL-Datenbank, die im Rahmen von Apache Hadoop bereitgestellt wird.
- Funken - Wird verwendet, um eine In-Memory-Verarbeitung durchzuführen, die viel schneller ist als die Hadoop-Map-Reduzierung.
Hadoop-Anbieter
Es gibt viele Unternehmen, die Hadoop-Distributionen anbieten. Nachfolgend einige der besten Anbieter für Hadoop:
- Cloudera
- Hortonworks
- MapR
Es gibt nur wenige Voraussetzungen, um Hadoop zu lernen. Vorkenntnisse in Java und Skriptsprache sind erforderlich. Obwohl Hadoop bereits über eigene Programmiersprachen wie pig and hive verfügt, die den Backend-Code für die weitere Verarbeitung generieren, ist es dennoch möglich, eigene Programmiersprachen wie Ruby, Python, Perl und sogar C-Programmierung zu erstellen.
Bigdata und Hadoop sind auf dem heutigen Markt sehr gefragt. Dies wird in den kommenden Tagen weiter zunehmen. Viele Organisationen sind bereits in Hadoop eingezogen, und diejenigen, die noch nicht eingezogen sind, werden bald umziehen. Es gibt einen aktuellen Bericht, der besagt, dass große Unternehmen begonnen haben, in Big-Data-Analysen zu investieren. Die Prognose für das Big-Data-Marketing ist immer im Aufwärtstrend und keineswegs kurzlebig. Abgesehen davon bieten die Jobs in Hadoop und Big Data im Vergleich zu anderen Technologien immer eine hohe Bezahlung.
Top Big Data- und Hadoop-Unternehmen
Im Folgenden sind einige Top-Unternehmen aufgeführt, die die meisten Hadoop-Ressourcen einsetzen.
- Yahoo
- Amazonas
- Royal Bank of Scotland
- British Airways
- Expedia
- Walmart
Es gibt viele Unternehmen, die Big-Data-Anwendungen verwenden. Diese sind:
-
Nokia
Es verwendet Cloudera- und Hadoop-Komponenten wie HDFS, HBase, Sqoop, Scribe für die Anwendung. Es nutzte Benutzerdaten effektiv, um die Benutzererfahrung zu verstehen und zu verbessern. Es verwendet Datenverarbeitung und komplexe Analysen zum Erstellen der Karte mit prädiktiven Verkehrs- und Ebenenhöhenmodellen.
-
SAS
Es hat mit Hadoop zusammengearbeitet, um Datenwissenschaftlern zu helfen, bessere Einblicke zu gewinnen, indem eine Umgebung bereitgestellt wird, die visuelles und interaktives Erleben ermöglicht und somit dazu beiträgt, neue Trends zu erkunden. Die Analyseprogramme extrahieren aussagekräftige Erkenntnisse aus Daten, und die In-Memory-Technologie ermöglicht einen schnelleren Datenzugriff.
Es gibt auch viele andere Unternehmen, die Big-Data-Plattformen für verschiedene Analysen verwenden. Hierbei handelt es sich um Flugdatenanalysen von Black Box in der Luftfahrtindustrie, die unterschiedliche Analyse im Aktienmarkt usw.
Vorteile von Haddop
Im Folgenden sind einige der Vorteile von Hadoop aufgeführt
- Skalierbar - Anders als herkömmliches RDBMS ist es eine hochskalierbare Plattform, da große Datenmengen in verteilten Clustern über parallel arbeitende Standardhardware gespeichert werden können.
- Kostengünstig - Die Kosten waren für RDBMS zu hoch, um Daten zu speichern, die in Hadoop entlastet wurden.
- Schnell und flexibel - Es bietet Daten, auf die über sein verteiltes Dateisystem schnell zugegriffen werden kann. Es bietet auch die Möglichkeit, geschäftliche Erkenntnisse aus halbstrukturierten und unstrukturierten Daten abzuleiten.
- Fehlertolerant - Immer wenn Daten an einen Knoten gesendet werden, werden dieselben Daten auf andere Knoten repliziert, auf die bei einem Ausfall des ersten Knotens zugegriffen werden kann.
Fazit - Was ist Big Data und Hadoop?
Die Daten wachsen kontinuierlich und daher werden immer Big Data und Hadoop erforderlich sein, um diese Daten sinnvoll zu nutzen. Aus diesem Grund werden Fachleute mit Hadoop-Kenntnissen in den kommenden Tagen immer reichliche Möglichkeiten finden und können ein entscheidendes Kapital für eine Organisation sein, die das Geschäft und ihre Karriere fördert.
Empfohlene Artikel
Dies war ein Leitfaden zu Big Data und Hadoop. Hier haben wir die grundlegenden Konzepte und Komponenten von Big Data und Hadoop besprochen. Sie können auch den folgenden Artikel lesen, um mehr zu erfahren -
- Big Data Analytics-Beispiele
- Verwendung von Hadoop
- Leitfaden zur Datenvisualisierung
- Was ist Big Data Analytics?