
Einführung in Datenanalysetechniken
Im 21. Jahrhundert ist die Datenanalyse eines der am häufigsten verwendeten Wörter in allen Bereichen. Lassen Sie uns heute sehen, was jeder unter Datenanalyse und einigen wichtigen Techniken in der Datenanalyse versteht. Bei der Datenanalyse werden Daten untersucht, bereinigt, transformiert und modelliert, um nützliche Informationen zu finden, die die Entscheidungsfindung verbessern können. Im Jahr 2019 sagte der Ökonom: „Das wertvollste Gut der Welt ist nicht mehr Öl, sondern DATEN“. Die Datenanalyse ist eng mit der Datenvisualisierung verbunden. Basierend auf der Datenmenge, die die Industrie jede Minute generiert, und basierend auf ihrem Bedarf gibt es eine Vielzahl von Techniken, die ins Leben gerufen wurden. Lassen Sie uns sehen, was sie im nächsten Abschnitt sind. In diesem Thema lernen wir die Arten von Datenanalysetechniken kennen.
Wichtige Arten von Datenanalysetechniken
Datenanalysetechniken werden grob in zwei Typen eingeteilt
- Methoden basierend auf mathematischen und statistischen Ansätzen
- Methoden basierend auf künstlicher Intelligenz und maschinellem Lernen
Mathematische und statistische Ansätze
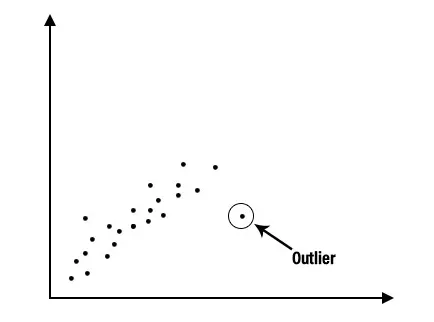
1. Deskriptive Analyse: Die deskriptive Analyse ist ein wichtiger erster Schritt für die Durchführung statistischer Analysen. Es liefert uns eine Vorstellung von der Verteilung von Daten, hilft uns dabei, Ausreißer zu erkennen und Assoziationen zwischen Variablen zu identifizieren. Auf diese Weise bereiten wir die Daten für die Durchführung weiterer statistischer Analysen vor. Die deskriptive Analyse eines riesigen Datensatzes kann durch Aufteilung in zwei Kategorien vereinfacht werden. Dabei handelt es sich um eine deskriptive Analyse für jede einzelne Variable und eine deskriptive Analyse für Kombinationen von Variablen.
2. Regressionsanalyse: Die Regressionsanalyse ist eine der wichtigsten Datenanalysetechniken, die derzeit in der Branche eingesetzt werden. Bei dieser Art von Technik können wir die Beziehung zwischen zwei oder mehreren interessierenden Variablen erkennen und im Kern untersuchen sie alle den Einfluss einer oder mehrerer unabhängiger Variablen auf die abhängige Variable. Um zu sehen, ob es eine Beziehung zwischen den Variablen gibt oder nicht, müssen wir zuerst die Daten in einem Diagramm darstellen und es wird offensichtlich, ob es eine Beziehung gibt. Betrachten Sie beispielsweise das unten dargestellte Diagramm, um ein klares Verständnis zu erhalten.
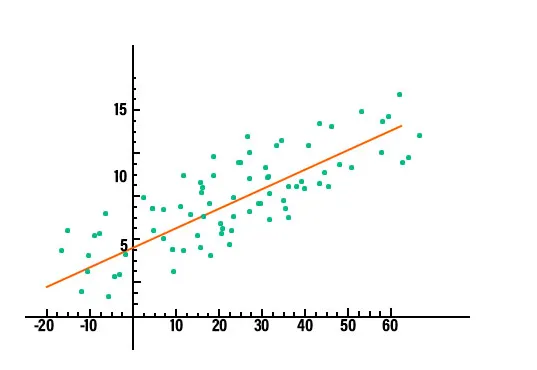
Beim Data Mining wird diese Technik verwendet, um die Werte einer Variablen in diesem bestimmten Dataset vorherzusagen. Es gibt verschiedene Arten von Regressionsmodellen. Einige davon sind lineare Regression, logistische Regression und multiple Regression.
3. Dispersionsanalyse: Dispersion ist das Ausmaß, in dem eine Verteilung gestreckt oder gequetscht wird. Im mathematischen Ansatz kann die Streuung auf zwei Arten definiert werden, im Wesentlichen als Differenz der Werte untereinander und im zweiten als Differenz zwischen den Durchschnittswerten. Wenn der Unterschied zwischen dem Wert und dem Durchschnitt sehr gering ist, kann man sagen, dass die Streuung in diesem Fall geringer ist. Einige der gebräuchlichen Dispersionsmaße sind Varianz, Standardabweichung und Interquartilbereich.
4. Faktorenanalyse: Die Faktorenanalyse ist eine Art Datenanalysetechnik, mit deren Hilfe die zugrunde liegende Struktur in einer Reihe von Variablen ermittelt werden kann. Es hilft bei der Suche nach unabhängigen Variablen im Datensatz, die die Muster und Modelle von Beziehungen beschreiben. Dies ist der erste Schritt in Richtung Clustering- und Klassifizierungsverfahren. Die Faktoranalyse ist auch mit der Hauptkomponentenanalyse (Principal Component Analysis, PCA) verwandt, aber beide sind nicht identisch. Wir können PCA als die grundlegendere Version der exploratorischen Faktoranalyse bezeichnen
5. Zeitreihen: Die Zeitreihenanalyse ist eine Datenanalysetechnik, die sich mit Zeitreihendaten oder Trendanalysen befasst. Lassen Sie uns nun verstehen, was Zeitreihendaten sind. Zeitreihendaten sind Daten in einer Reihe bestimmter Zeitintervalle oder -perioden. Aus wissenschaftlicher Sicht werden die meisten Messungen im Laufe der Zeit durchgeführt.
Methoden basierend auf maschinellem Lernen und künstlicher Intelligenz
1. Entscheidungsbäume: Die Entscheidungsbaumanalyse ist eine grafische Darstellung, ähnlich einer baumartigen Struktur, in der die Probleme bei der Entscheidungsfindung in Form eines Flussdiagramms mit Verzweigungen für alternative Antworten dargestellt werden. Entscheidungsbäume sind ein Top-Down-Ansatz, bei dem der erste Entscheidungsknoten auf der Grundlage der Antwort am ersten Entscheidungsknoten oben in Zweige unterteilt wird und der fortgesetzt wird, bis der Baum zu einer endgültigen Entscheidung gelangt. Die Zweige, die sich nicht mehr teilen, nennt man Blätter.
2. Neuronale Netze: Neuronale Netze sind eine Reihe von Algorithmen, die das menschliche Gehirn nachahmen sollen. Es wird auch als "Netzwerk künstlicher Neuronen" bezeichnet. Die Anwendungen des neuronalen Netzes beim Data Mining sind sehr breit. Sie haben eine hohe Akzeptanzfähigkeit für verrauschte Daten und hohe Genauigkeit der Ergebnisse. Basierend auf der Notwendigkeit werden gegenwärtig viele Arten von neuronalen Netzen verwendet, von denen einige wiederkehrende neuronale Netze und Faltungs-neuronale Netze sind. Faltungs-Neuronale Netze werden hauptsächlich in Bildverarbeitungs-, natürlichen Sprachverarbeitungs- und Empfehlungssystemen verwendet. Wiederkehrende neuronale Netze werden hauptsächlich zur Handschrift- und Spracherkennung verwendet.
3. Evolutionäre Algorithmen: Evolutionäre Algorithmen nutzen die Mechanismen, die durch Rekombination und Selektion inspiriert sind. Diese Arten von Algorithmen sind unabhängig von der Domäne und können große Datenmengen untersuchen, Muster und Lösungen entdecken. Sie sind im Vergleich zu anderen Datentechniken unempfindlich gegen Rauschen.
4. Fuzzy-Logik: Es handelt sich um einen Computeransatz, der auf dem Wahrheitsgrad und nicht auf der üblichen booleschen Logik (wahr / falsch oder 0/1) basiert. Wie oben in Entscheidungsbäumen am Entscheidungsknoten besprochen, haben wir entweder Ja oder Nein als Antwort. Was ist, wenn wir eine Situation haben, in der wir nicht absolut Ja oder absolut Nein entscheiden können? In diesen Fällen spielt die Fuzzy-Logik eine wichtige Rolle. Hierbei handelt es sich um eine Logik mit verschiedenen Werten, bei der der Wahrheitswert zwischen vollständig wahr und vollständig falsch liegen kann, dh einen beliebigen realen Wert zwischen 0 und 1 annehmen kann. Die Fuzzy-Logik ist anwendbar, wenn die Werte eine erhebliche Menge an Rauschen aufweisen.
Fazit
Die schwierige Frage, mit der alle Unternehmen konfrontiert sind, ist, welche Art von Datenanalysetechnik für sie am besten geeignet ist. Wir können keine Technik als die beste definieren. Stattdessen können wir mehrere Techniken ausprobieren und feststellen, welche am besten zu unserem Datensatz passt, und sie verwenden. Die oben genannten Techniken sind einige der wichtigsten Techniken, die derzeit in der Industrie verwendet werden.
Empfohlene Artikel
Dies ist ein Leitfaden für Arten von Datenanalysetechniken. Hier werden die Arten von Datenanalysetechniken erläutert, die derzeit in der Branche verwendet werden. Sie können sich auch die folgenden Artikel ansehen, um mehr zu erfahren -
- Data Science Tools
- Data Science Platform
- Data Science Karriere
- Big Data-Technologien
- Clustering im maschinellen Lernen
- Fuzzy Logic System | Verwendungszweck: Architektur
- Kompletter Leitfaden zur Implementierung neuronaler Netze
- Was ist Datenanalyse?
- Entscheidungsbaum mit Vorteilen anlegen
- Leitfaden für verschiedene Arten der Datenanalyse