
Überblick über neuronale Netzwerkalgorithmen
- Lassen Sie uns zuerst wissen, was ein neuronales Netzwerk bedeutet. Neuronale Netze sind von den biologischen neuronalen Netzen im Gehirn oder dem Nervensystem inspiriert. Es hat viel Aufregung hervorgerufen und es wird immer noch an dieser Untergruppe des maschinellen Lernens in der Industrie geforscht.
- Die grundlegende Recheneinheit eines neuronalen Netzwerks ist ein Neuron oder ein Knoten. Es empfängt Werte von anderen Neuronen und berechnet die Ausgabe. Jeder Knoten / jedes Neuron ist mit dem Gewicht (w) verbunden. Dieses Gewicht wird gemäß der relativen Wichtigkeit dieses bestimmten Neurons oder Knotens angegeben.
- Wenn wir also f als Knotenfunktion verwenden, liefert die Knotenfunktion f die folgende Ausgabe:
Ausgabe des Neurons (Y) = f (w1.X1 + w2.X2 + b)
- Wenn w1 und w2 Gewicht sind, sind X1 und X2 numerische Eingaben, während b die Vorspannung ist.
- Die obige Funktion f ist eine nichtlineare Funktion, die auch Aktivierungsfunktion genannt wird. Sein Hauptzweck ist es, Nichtlinearität einzuführen, da fast alle Daten der realen Welt nichtlinear sind, und wir möchten, dass Neuronen diese Darstellungen lernen.
Verschiedene neuronale Netzwerkalgorithmen
Schauen wir uns nun vier verschiedene neuronale Netzwerkalgorithmen an.
1. Gefälle
Es ist einer der beliebtesten Optimierungsalgorithmen im Bereich des maschinellen Lernens. Es wird beim Trainieren eines maschinellen Lernmodells verwendet. In einfachen Worten, es wird im Grunde genommen verwendet, um Werte der Koeffizienten zu finden, die einfach die Kostenfunktion so weit wie möglich reduzieren. Zunächst definieren wir einige Parameterwerte und passen sie dann mit Hilfe der Berechnungsmethode iterativ an Die verlorene Funktion wird reduziert.
Kommen wir nun zu dem Teil, was Gradient ist. Ein Gradient bedeutet also, dass sich die Ausgabe einer Funktion stark ändert, wenn wir die Eingabe nach und nach verringern oder sie mit anderen Worten als Steigung bezeichnen. Wenn die Steigung steil ist, lernt das Modell schneller, ähnlich wie ein Modell aufhört zu lernen, wenn die Steigung Null ist. Dies liegt daran, dass es sich um einen Minimierungsalgorithmus handelt, der einen bestimmten Algorithmus minimiert.
Unterhalb der Formel zum Finden der nächsten Position wird bei Gefälle angezeigt.
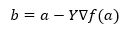
Wobei b die nächste Position ist
a ist die aktuelle Position, gamma ist eine Wartefunktion.
Wie Sie sehen können, ist Gradientenabstieg eine sehr solide Technik, aber es gibt viele Bereiche, in denen Gradientenabstieg nicht richtig funktioniert. Nachfolgend sind einige davon aufgeführt:
- Wenn der Algorithmus nicht richtig ausgeführt wird, kann es vorkommen, dass der Gradient verschwindet. Diese treten auf, wenn der Gradient zu klein oder zu groß ist.
- Probleme treten auf, wenn die Datenanordnung ein nicht konvexes Optimierungsproblem darstellt. Gradient menschenwürdig arbeitet nur mit Problemen, die das konvex optimierte Problem sind.
- Einer der wichtigsten Faktoren, auf die Sie bei der Anwendung dieses Algorithmus achten müssen, sind die Ressourcen. Wenn wir weniger Speicher für die Anwendung zugewiesen haben, sollten wir den Algorithmus für den Gradientenabstieg vermeiden.
2. Newtonsche Methode
Es ist ein Optimierungsalgorithmus zweiter Ordnung. Es wird eine zweite Ordnung genannt, weil es die hessische Matrix verwendet. Die hessische Matrix ist also nichts anderes als eine quadratische Matrix von partiellen Ableitungen zweiter Ordnung einer skalarwertigen Funktion. In Newtons Algorithmus zur Methodenoptimierung wird sie auf die erste Ableitung einer doppelt differenzierbaren Funktion f angewendet, um die Wurzeln zu finden / stationäre Punkte. Kommen wir nun zu den Schritten, die für Newtons Optimierungsmethode erforderlich sind.
Zunächst wird der Verlustindex ausgewertet. Anschließend wird geprüft, ob das Stoppkriterium wahr oder falsch ist. Bei false werden dann die Trainingsrichtung und die Trainingsrate von Newton berechnet und anschließend die Parameter oder Gewichte des Neurons verbessert. Wiederum wird derselbe Zyklus fortgesetzt. Sie können also jetzt sagen, dass im Vergleich zum Gradientenabstieg weniger Schritte erforderlich sind, um das Minimum zu erreichen Wert der Funktion. Obwohl es im Vergleich zum Gradientenabstiegsalgorithmus weniger Schritte erfordert, wird es nicht häufig verwendet, da die genaue Berechnung des Hessischen und seines Inversen rechenintensiv ist.
3. Gradient konjugieren
Es ist eine Methode, die als etwas zwischen Gradientenabstieg und Newtons Methode angesehen werden kann. Der Hauptunterschied besteht darin, dass es die langsame Konvergenz beschleunigt, die wir im Allgemeinen mit Gradientenabstieg assoziieren. Eine weitere wichtige Tatsache ist, dass es sowohl für lineare als auch für nichtlineare Systeme verwendet werden kann und ein iterativer Algorithmus ist.
Es wurde von Magnus Hestenes und Eduard Stiefel entwickelt. Wie oben bereits erwähnt, führt es zu einer schnelleren Konvergenz als zu einer Gradientenabnahme. Dies liegt daran, dass beim Algorithmus "Konjugierter Gradient" die Suche zusammen mit den konjugierten Richtungen erfolgt, wodurch es schneller konvergiert als Algorithmen zur Gradientenabnahme. Ein wichtiger Punkt ist, dass γ der Konjugatparameter genannt wird.
Die Trainingsrichtung wird periodisch auf das Negative des Gradienten zurückgesetzt. Diese Methode ist beim Trainieren des neuronalen Netzes effektiver als der Gradientenabstieg, da keine hessische Matrix erforderlich ist, die die Rechenlast erhöht, und sie konvergiert auch schneller als der Gradientenabstieg. Es ist angebracht, in großen neuronalen Netzen zu verwenden.
4. Quasi-Newton-Methode
Es ist ein alternativer Ansatz zu Newtons Methode, da wir jetzt wissen, dass Newtons Methode rechenintensiv ist. Diese Methode behebt diese Nachteile in einem solchen Ausmaß, dass anstatt die Hessische Matrix zu berechnen und dann die Inverse direkt zu berechnen, diese Methode bei jeder Iteration dieses Algorithmus eine Approximation zur inversen Hessischen aufbaut.
Diese Näherung wird nun anhand der Informationen aus der ersten Ableitung der Verlustfunktion berechnet. Wir können also sagen, dass es wahrscheinlich die am besten geeignete Methode ist, um mit großen Netzwerken umzugehen, da es Rechenzeit spart und außerdem viel schneller ist als die Gradientenabstiegs- oder die konjugierte Gradientenmethode.
Fazit
Bevor wir diesen Artikel beenden, vergleichen wir die Rechengeschwindigkeit und den Speicher für die oben genannten Algorithmen. Gemäß den Speicheranforderungen erfordert der Gradientenabstieg den geringsten Speicher und ist auch der langsamste. Im Gegensatz dazu erfordert Newtons Methode mehr Rechenleistung. Unter Berücksichtigung all dieser Faktoren ist die Quasi-Newton-Methode am besten geeignet.
Empfohlene Artikel
Dies war ein Leitfaden für neuronale Netzwerkalgorithmen. Hier diskutieren wir auch die Übersicht über den neuronalen Netzwerkalgorithmus zusammen mit jeweils vier verschiedenen Algorithmen. Sie können auch unsere anderen Artikelvorschläge durchgehen, um mehr zu erfahren -
- Maschinelles Lernen vs Neuronales Netz
- Frameworks für maschinelles Lernen
- Neuronale Netze vs Deep Learning
- K - bedeutet Clustering-Algorithmus
- Leitfaden zur Klassifikation des neuronalen Netzes