
Einführung in die Hadoop FS-Befehlsliste
Hadoop arbeitet mit einem eigenen Dateisystem, das in der Natur als "Hadoop Distributed File System HDFS " bezeichnet wird . Hadoop setzt auf verteilten Speicher und parallele Verarbeitung. Diese Art der Speicherung der Datei an verteilten Speicherorten in einem Cluster wird als verteiltes Hadoop-Dateisystem (HDFS) bezeichnet. Um verschiedene Operationen auf Dateiebene auszuführen, stellt HDFS einen eigenen Befehlssatz bereit, der als Hadoop-Dateisystembefehle bezeichnet wird. Lassen Sie uns diese Befehle untersuchen. In diesem Thema lernen wir Hadoop FS Command kennen.
Befehle von Hadoop FS
Jeder HDFS-Befehl hat das Präfix "hdfs dfs". Dies bedeutet, dass das Standarddateisystem HDFS ist. Lassen Sie uns Befehle einzeln untersuchen
1. Versionen
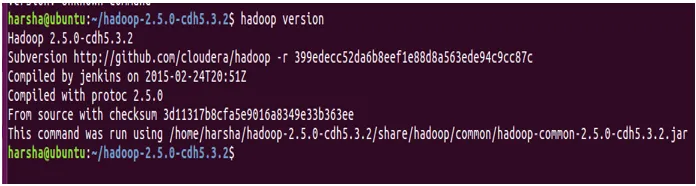
Mit dem Befehl version wird die auf dem System installierte Version von Hadoop ermittelt.
Syntax: Hadoop version
2. ls Befehl
Mit dem Befehl ls in Hadoop wird die Liste der Verzeichnisse im angegebenen Pfad angegeben. Der Befehl ls verwendet den Pfad hdfs als Parameter und gibt eine Liste der im Pfad vorhandenen Verzeichnisse zurück.
Syntax: hdfs dfs -ls
Beispiel: hdfs dfs -ls / user / harsha

Wir können -lsr auch für den rekursiven Modus verwenden
Syntax: hdfs dfs –lsr
3. Cat-Befehl
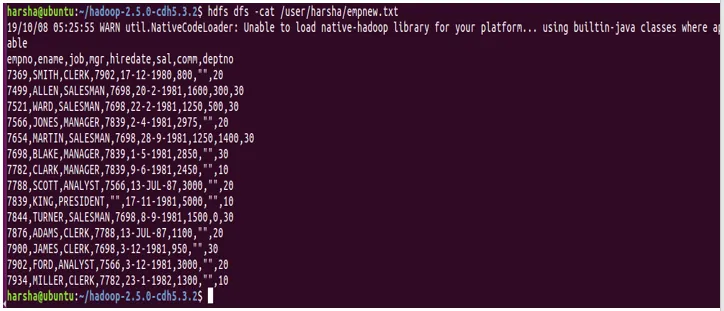
Mit dem Cat-Befehl wird der Inhalt der Datei auf der Konsole angezeigt. Dieser Befehl verwendet den Pfad der hdfs-Datei als Argument und zeigt den Inhalt der Datei an.
Syntax: hdfs dfs -cat
Beispiel: hdfs dfs -cat /user/harsha/empnew.txt
4. Befehl mkdir
Mit dem Befehl mkdir wird ein neues Verzeichnis im hdfs-Dateisystem erstellt. Es nimmt den hdfs-Pfad als Argument und erstellt ein neues Verzeichnis in dem angegebenen Pfad.
Syntax: hdfs dfs -mkdir
Beispiel: hdfs dfs -mkdir / user / example
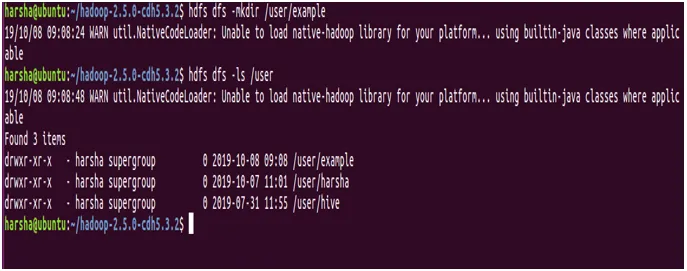
In der obigen Abbildung wird deutlich, dass wir mit dem Befehl mkdir ein neues Verzeichnis mit dem Namen "example" erstellen und dasselbe mit dem Befehl ls.
Auch für den Befehl mkdir können wir die Option '-p' angeben. Es werden übergeordnete Verzeichnisse im Pfad erstellt, wenn sie fehlen.
Beispiel: hdfs dfs -mkdir -p / user / test / example2
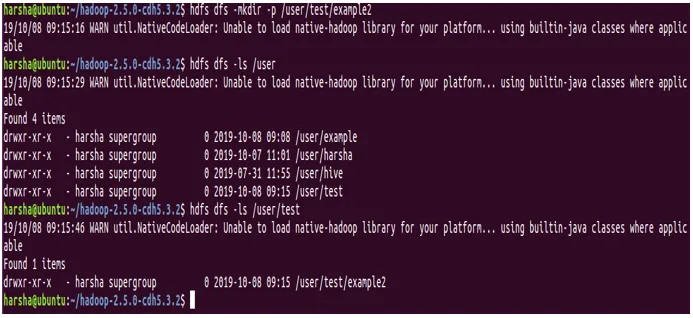
In dem obigen Screenshot ist es ziemlich offensichtlich, dass wir die Option -p haben und dass im Pfad / user / test / example2 sowohl die Verzeichnisse tests als auch example2 erstellt werden.
5. Befehl setzen
Mit dem Befehl put in HDFS werden Dateien vom angegebenen Quellspeicherort in den Ziel-HDFS-Pfad kopiert. Der Quellspeicherort kann ein lokaler Dateisystempfad sein. Der Befehl put benötigt zwei Argumente: Das erste ist der Quellverzeichnispfad und das zweite der HDFS-Zielpfad
Syntax: hdfs dfs -put
Beispiel: hdfs dfs -put /home/harsha/empnew.txt / user / test / example2
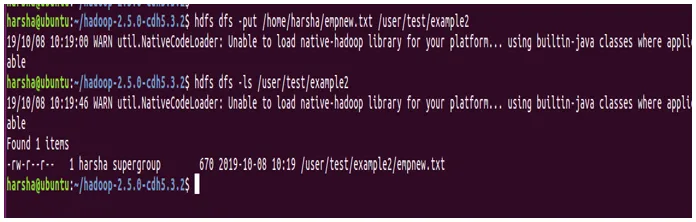
In dem obigen Screenshot sehen wir deutlich, dass die Datei von der Quelle zum Ziel kopiert wird.
6. Befehl copyFromLocal
Der Befehl copyFromLocal in HDFS wird zum Kopieren von Dateien vom Quellpfad in den Zielpfad verwendet. Die Quelle in diesem Befehl ist auf das lokale Dateisystem beschränkt
Syntax: hdfs dfs -copyFromLocal /home/harsha/empnew.txt/user/harsha/example

Unterschied zwischen put-Befehl und copyFromLocal-Befehl: Es gibt keinen großen Unterschied zwischen diesen beiden hdfs-Shell-Befehlen. Beide werden zum Kopieren aus dem lokalen Dateisystem verwendet, um den HDFS-Dateipfad als Ziel festzulegen.
Der Befehl put ist jedoch nützlicher und robuster, da er das Kopieren mehrerer Dateien oder Verzeichnisse zum Ziel in HDFS ermöglicht
hdfs dfs -put
7. Kommando holen
Mit dem Befehl get in hdfs wird eine bestimmte hdfs-Datei oder ein bestimmtes Verzeichnis in den lokalen Dateisystempfad des Ziels kopiert. Es sind zwei Argumente erforderlich, eines ist der Quell-hdfs-Pfad und das andere der Pfad des lokalen Dateisystems
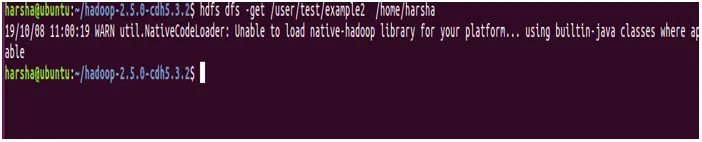
Syntax: hdfs dfs -get
Beispiel: hdfs dfs -get / user / test / example2 / home / harsha
8. Befehl copyToLocal
Der Befehl copyToLocal in hdfs wird verwendet, um eine Datei oder ein Verzeichnis in hdfs in das lokale Dateisystem zu kopieren. Bei diesem Befehl ist das Ziel auf das lokale Dateisystem festgelegt. Dieser Befehl copyFromLocal ähnelt dem Befehl get.
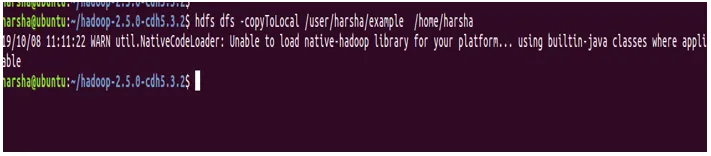
Syntax: hdfs dfs -copyToLocal
Beispiel: hdfs dfs -copyToLocal / user / harsha / example / home / harsha
9. Befehl count
Mit dem Befehl count in hdfs wird die Anzahl der im angegebenen Pfad vorhandenen Verzeichnisse gezählt. Der Befehl count verwendet einen angegebenen Pfad als Argument und gibt die Anzahl der in diesem Pfad vorhandenen Verzeichnisse an.
Syntax: hdfs dfs -count
Beispiel: hdfs dfs -count / user

10. Befehl mv
Der Befehl mv in hdfs dient zum Verschieben einer Datei zwischen hdfs. Mit dem Befehl mv wird die Datei oder das Verzeichnis aus dem angegebenen Quell-HDFS-Pfad in den Ziel-HDFS-Pfad verschoben.
Syntax : hdfs dfs -mv
Beispiel : hdfs dfs -mv / benutzer / test / beispiel2 / benutzer / harsha
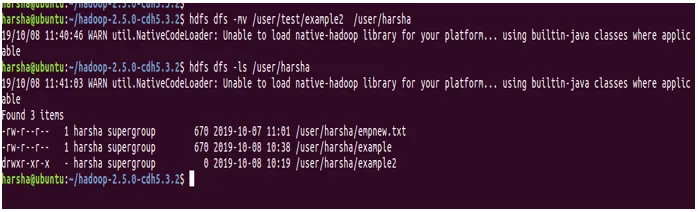
Im obigen Screenshot können wir sehen, dass das Verzeichnis example2 jetzt in / user / harsha vorhanden ist
11. Befehl setrep
Mit dem Befehl setrep in hdfs wird der Replikationsfaktor der angegebenen Datei geändert. Standardmäßig hat hdfs einen Replikationsfaktor von '3'. Wenn der angegebene Pfad ein Verzeichnis ist, ändert dieser Befehl den Replikationsfaktor aller in diesem Verzeichnis vorhandenen Dateien.
Syntax: hdfs dfs -setrep (-R) (-w)
-w: Dieses Flag gibt an, dass der Befehl warten soll, bis die Replikation abgeschlossen ist.
rep: Replikationsfaktor
Beispiel: hdfs dfs -setrep -w 5 /user/harsha/empnew.txt
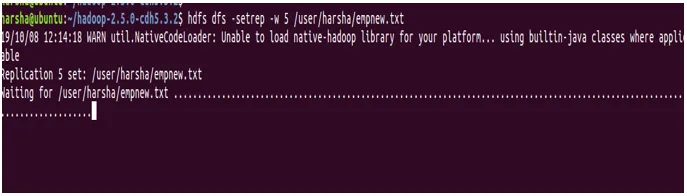
12. du Befehl
Der Befehl du in hdfs zeigt die Festplattenauslastung für den angegebenen hdfs-Pfad an. Es nimmt den hdfs-Pfad als Eingabe und gibt die Festplattenauslastung in Byte zurück.
Syntax : hdfs dfs -du
Beispiel: hdfs dfs -du /user/harsha/empnew.txt
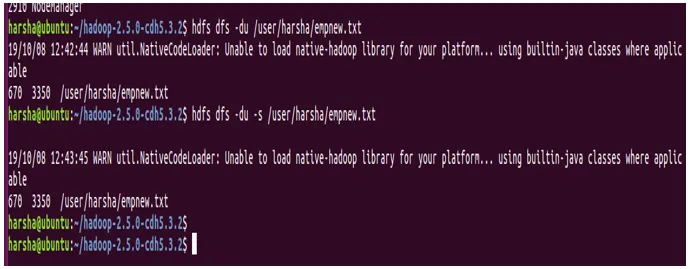
13. Befehl rm
Mit dem Befehl rm in hdfs werden Dateien oder Verzeichnisse im angegebenen hdfs-Pfad entfernt. Dieser Befehl nimmt den hdfs-Pfad als Eingabe und entfernt die in diesem Pfad vorhandenen Dateien.
Syntax : hdfs dfs -rm
Beispiel : hdfs dfs -rm / user / harsha / example
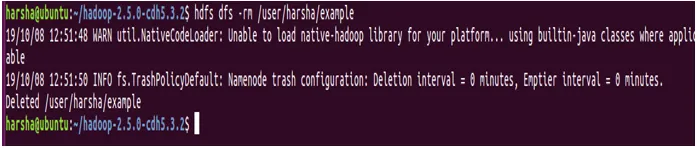
Schlussfolgerung - Hadoop FS-Befehl
Wir haben hiermit verschiedene hdfs-Befehle kennengelernt, deren jeweilige Syntax auch mit Beispielen. Wir sollten beachten, dass alle hdfs-Befehle Kick-Start sind. Wir müssen das Skript bin / hdfs ausführen. Nach hdfs folgt eine Option namens dfs, die angibt, dass wir mit dem verteilten Hadoop-Dateisystem arbeiten. Mit Hilfe der oben genannten Befehle können wir mit dem HDFS-Dateisystem verhandeln.
Empfohlene Artikel
Dies ist eine Anleitung zu Hadoop FS Command. Hier diskutieren wir die am häufigsten verwendeten HDFS-Befehle. Sie können auch den folgenden Artikel lesen, um mehr zu erfahren -
- Hadoop-Architektur
- HADOOP Framework
- Installieren Sie Hadoop
- Hadoop Tools
- Tableau-Versionen
- Leitfaden zur Liste der Unix-Shell-Befehle