

Einführung in Joins in Hive
Joins werden verwendet, um verschiedene Ausgaben mithilfe mehrerer Tabellen abzurufen, indem sie basierend auf bestimmten Spalten kombiniert werden. Damit sich die Tabellen in Hive befinden, müssen Sie die Tabellen erstellen und die Daten in jede Tabelle laden. Wir werden hier zwei Tabellen (Kunde und Produkt) verwenden, um den Zweck zu verstehen.
Verschiedene Befehle
Nachfolgend finden Sie die Befehle zum Erstellen und Laden der Daten in diesen Tabellen:
Für Kundentabelle : 6 Zeilen
Befehl erstellen
Externe Tabelle erstellen, wenn kein Kunde vorhanden ist (ID-Zeichenfolge, Namenszeichenfolge, Ortszeichenfolge)
Zeilenformat getrennt
Felder mit '' abgeschlossen
location '/user/hive/warehouse/test.db/customer'
tblproperties ("skip.header.line.count" = "1");
Befehl laden
Laden Sie die lokalen Daten im Pfad '/home/cloudera/Customer_Neha.txt' in die Tabelle customer.
Kundentabelle Daten

Für Produkttabelle : 6 Reihen
Befehl erstellen
Externe Tabelle erstellen, wenn Produkt nicht vorhanden ist (Cust_Id-Zeichenfolge,
Produktstring, Preisstring)
Zeilenformat getrennt
Felder mit '' abgeschlossen
location '/user/hive/warehouse/test.db/product'
tblproperties ("skip.header.line.count" = "1");
Befehl laden
Laden Sie den lokalen Datenpfad '/home/cloudera/Product_Neha.txt' in das Tabellenprodukt.
Produkttabellendaten
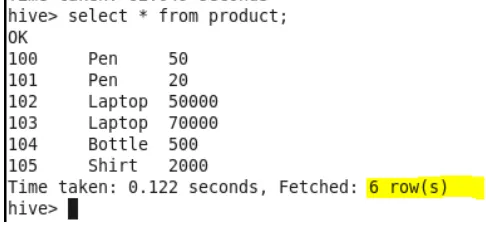
Verwenden Sie den Befehl "desc table name", um das Tabellenschema zu überprüfen.
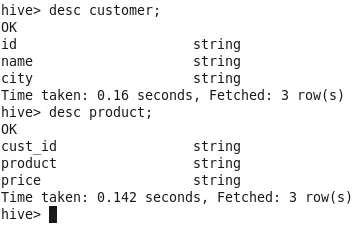
Jetzt haben wir Daten in Tabellen, Lass uns damit spielen ????
Arten von Joins in Hive
Join - Dies ergibt das Kreuzprodukt beider Tabellendaten als Ausgabe. Wie Sie sehen können, haben wir 6 Zeilen in jeder Tabelle. Die Ausgabe für Join beträgt also 36 Zeilen. Die Anzahl der Mapper-1. Es wird jedoch keine Reduzierung auf den Bediener vorgenommen.
Befehl

Ausgabe:
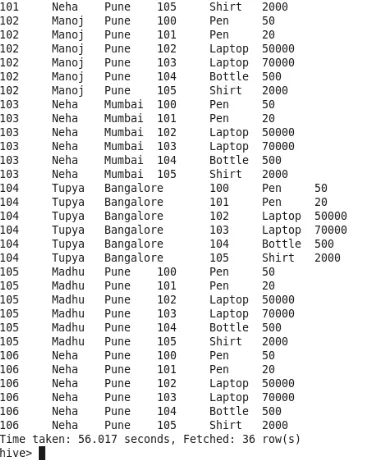
1. Vollständiger Beitritt
Full Join ohne Matchbedingung ergibt das Kreuzprodukt beider Tabellen.
Anzahl der Mapper-2
Anzahl der Reduzierer-1
Dies kann auch mit "Verbinden" erreicht werden, jedoch mit weniger Mapper und Reduzierer.
Full Join mit Matchbedingung
Alle Zeilen werden aus beiden Tabellen verknüpft. Wenn Zeilen in einer anderen Tabelle nicht übereinstimmen, wird die Ausgabe mit NULL aufgefüllt (siehe ID-100.106). Es werden keine Zeilen übersprungen.
Anzahl der Mapper-2
Anzahl der Reduzierer-1
Befehl

Ausgabe:
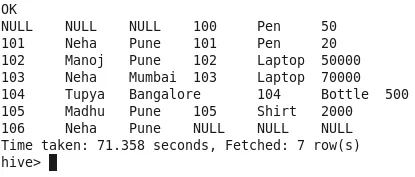
2. Inner Join
Wenn der innere Join ohne die Klausel "on" verwendet wird, wird das Kreuzprodukt als Ausgabe ausgegeben. Wir müssen jedoch die spezifischen Spalten verwenden, auf deren Grundlage der Join ausgeführt werden kann. Die ID-Spalte aus der Kundentabelle und die Cust_id-Spalte aus der Produkttabelle sind meine spezifischen Spalten. Die Ausgabe enthält die Zeilen, in denen Id und Cust_Id übereinstimmen. Sie können beobachten, dass Zeilen mit Id-106 und Cust_Id-100 in der Ausgabe übersprungen werden, weil sie in keiner anderen Tabelle vorhanden sind.
Befehl

Ausgabe:

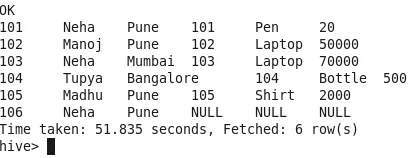
3. Linke Verbindung
Alle Zeilen aus der linken Tabelle werden mit übereinstimmenden Zeilen aus der rechten Tabelle verknüpft. Wenn die rechte Tabelle Zeilen mit IDs enthält, die in der linken Tabelle nicht vorhanden sind, werden diese Zeilen übersprungen (Beachten Sie Cust_Id-100 in der Ausgabe). Wenn die rechte Tabelle keine Zeilen mit IDs enthält, die sich in der linken Tabelle befinden, wird NULL in der Ausgabe eingetragen (Beachten Sie ID-106 in der Ausgabe).
Anzahl der Mapper-1
Anzahl der Reduzierer-0
Befehl

Ausgabe:
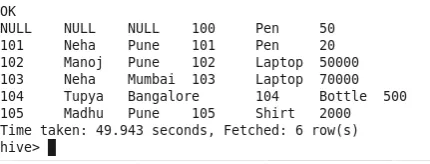
4. Right Join
Alle Zeilen der rechten Tabelle werden mit den Zeilen der linken Tabelle abgeglichen. Wenn die linke Tabelle keine Zeile enthält, wird NULL ausgefüllt (siehe ID 100). Zeilen aus der linken Tabelle werden übersprungen, wenn diese Übereinstimmung nicht in der rechten Tabelle gefunden wird (siehe ID 106).
Anzahl der Mapper-1
Anzahl der Reduzierer-0
Befehl

Ausgabe:
Fazit - schließt sich Hive an
"Verbinden" kann, wie das Wort schon sagt, zwei oder mehr Tabellen in der Datenbank verbinden. Es ähnelt Joins in SQL. Joins werden verwendet, um verschiedene Ausgaben mithilfe mehrerer Tabellen abzurufen, indem sie basierend auf bestimmten Spalten kombiniert werden. Anhand der Anforderung kann entschieden werden, welcher Join für Sie geeignet ist. Wenn Sie beispielsweise überprüfen möchten, welche IDs in der linken Tabelle, aber nicht in der rechten Tabelle vorhanden sind, können Sie einfach den Linken Join verwenden. In Hive-Joins können je nach Komplexität verschiedene Optimierungen durchgeführt werden. Einige Beispiele sind Repartitions-, Replikations- und Semi-Joins.
Empfohlene Artikel
Dies ist eine Anleitung zu Joins in Hive. Hier diskutieren wir die Arten von Joins wie Full Join, Inner Join, Left Join und Right Join in Hive sowie deren Befehl und Ausgabe. Sie können sich auch die folgenden Artikel ansehen, um mehr zu erfahren.
- Was ist ein Bienenstock?
- Hive-Befehle
- Hive Training (2 Kurse, 5+ Projekte)
- Apache Pig vs Apache Hive - Top 12 nützliche Unterschiede
- Merkmale von Hive-Alternativen
- Verwenden der ORDER BY-Funktion in Hive
- Top 6 Arten von Joins in MySQL mit Beispielen