

Unterschied zwischen MapReduce und Spark
Map Reduce ist ein Open-Source-Framework zum Schreiben von Daten in HDFS und zum Verarbeiten von strukturierten und unstrukturierten Daten in HDFS. Map Reduce ist auf die Stapelverarbeitung beschränkt und auf anderen Systemen kann Spark jede Art von Verarbeitung ausführen. SPARK ist eine unabhängige Verarbeitungsengine für die Echtzeitverarbeitung, die auf jedem Distributed File-System wie Hadoop installiert werden kann. SPARK bietet eine Leistung, die 10-mal schneller als Map Reduce auf der Festplatte und 100-mal schneller als Map Reduce in einem Netzwerk im Speicher ist.
Need For SPARK
- Iterative Analytics: Map-Reduce ist nicht so effizient wie ein SPARK, um Probleme zu lösen, die iterative Analytics erfordern, da es bei jeder Iteration auf die Festplatte geschrieben werden muss.
- Interactive Analytics: Map-Reduce wird häufig zum Ausführen von Ad-hoc-Abfragen verwendet, bei denen der Speicher auf der Festplatte benötigt wird, der wiederum nicht so effizient ist wie SPARK, da sich dieser auf den Arbeitsspeicher bezieht, der schneller ist.
- Nicht für OLTP geeignet: Da es auf dem Batch-orientierten Framework funktioniert, ist es für eine große Anzahl der kurzen Transaktionen nicht geeignet.
- Nicht für Diagramme geeignet: Die Apache-Diagrammbibliothek verarbeitet das Diagramm, wodurch Map Reduce komplexer wird.
- Nicht für einfache Operationen geeignet: Für Operationen wie Filter und Joins müssen möglicherweise die Jobs neu geschrieben werden, was aufgrund des Schlüsselwertmusters komplexer wird.
Head to Head Vergleich zwischen MapReduce und Spark (Infografik)
Unten sehen Sie den 15 größten Unterschied zwischen MapReduce und Spark

Hauptunterschiede zwischen MapReduce und Spark
Nachfolgend sind die Punktelisten aufgeführt, in denen die wichtigsten Unterschiede zwischen MapReduce und Spark beschrieben sind:
- Spark ist für die Echtzeitverarbeitung mit In-Memory geeignet, während MapReduce auf die Stapelverarbeitung beschränkt ist.
- Spark verfügt über RDD (Resilient Distributed Dataset), das uns Operatoren auf hohem Niveau bietet. In Map Redu müssen wir jedoch jeden einzelnen Vorgang codieren, was es vergleichsweise schwierig macht.
- Spark kann Grafiken verarbeiten und unterstützt das Tool für maschinelles Lernen.
- Unten ist der Unterschied zwischen MapReduce und Spark-Ökosystem.
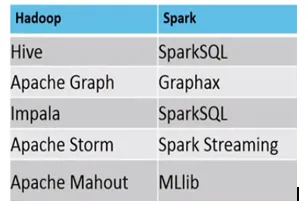
Beispiel, wo MapReduce vs Spark geeignet sind, sind wie folgt
Spark: Erkennung von Kreditkartenbetrug
MapReduce: Erstellung regelmäßiger Berichte, die eine Entscheidungsfindung erfordern.
MapReduce vs Spark Vergleichstabelle
| Vergleichsbasis | Karte verkleinern | Funke |
| Rahmen | Ein Open-Source-Framework zum Schreiben von Daten in HDFS und zum Verarbeiten von strukturierten und unstrukturierten Daten in HDFS. | Ein Open-Source-Framework für eine schnellere und universell einsetzbare Datenverarbeitung |
| Geschwindigkeit | Map-Reduce verarbeitet die Daten (Lese- und Schreibzugriff) von der Festplatte, sodass der Sickerprozess im Vergleich zu Spark langsam ist. | Spark ist mindestens 10-mal schneller auf der Festplatte und 100-mal schneller im Speicher als Map Reduce. |
| Schwierigkeit | Wir müssen jeden Prozess codieren / handhaben. | Mit der Verfügbarkeit von RDD (Resilient Distributed Dataset) ist die Programmierung einfach. |
| Echtzeit | Nicht geeignet für OLTP-Transaktionen nur für den Batch-Modus | Es kann die Echtzeitverarbeitung handhaben. SPARK-Streaming verwenden. |
| Latenz | Latenzberechnungsframework auf hoher Ebene | Low-Level-Latenz-Computing-Framework. |
| Fehlertoleranz | Master-Daemons überprüfen den Heartbeat von Slave-Daemons, und falls Slave-Daemons ausfallen, planen Master-Daemons alle ausstehenden und laufenden Vorgänge für einen anderen Slave neu. | RDDs bieten Fehlertoleranz gegenüber SPARK. Sie beziehen sich auf den in externen Speichern vorhandenen Datensatz wie (HDFS, HBase) und arbeiten parallel. |
| Planer | In Map Reduce verwenden wir einen externen Scheduler wie Oozie. | Da SPARK mit In-Memory-Computing arbeitet, fungiert es als eigener Scheduler. |
| Kosten | Map Reduce ist im Vergleich zu SPARK vergleichsweise günstiger. | Da es im Arbeitsspeicher arbeitet, erfordert es viel RAM, was es vergleichsweise kostspieliger macht. |
| Plattform Entwickelt auf | Map Reduce wurde mit Java entwickelt. | SPARK wurde mit Scala entwickelt. |
| Sprache unterstützt | Map Reduce unterstützt grundsätzlich C, C ++, Ruby, Groovy, Perl, Python. | Spark unterstützt Scala, Java, Python, R, SQL. |
| SQL-Unterstützung | Map Reduce führt Abfragen mit Hive Query Language aus. | Spark hat eine eigene Abfragesprache namens Spark SQL. |
| Skalierbarkeit | In Map Reduce können wir bis zu n Knoten hinzufügen. Der größte Hadoop-Cluster hat 14000 Knoten. | In Spark können wir auch n Knoten hinzufügen. Der größte Spark-Cluster hat 8000 Knoten. |
| Maschinelles Lernen | Map Reduce unterstützt das Apache Mahout-Tool für maschinelles Lernen. | Spark unterstützt das MLlib-Tool für maschinelles Lernen. |
| Caching | Map Reduce kann keine Speicherdaten zwischenspeichern, ist also nicht so schnell wie Spark. | Spark speichert die speicherinternen Daten für weitere Iterationen im Cache, sodass sie im Vergleich zu Map Reduce sehr schnell sind. |
| Sicherheit | Map Reduce unterstützt im Vergleich zu Spark mehr Sicherheitsprojekte und -funktionen | Die Spark-Sicherheit ist noch nicht so ausgereift wie die von Map Reduce |
Fazit - MapReduce vs Spark
Aufgrund des obigen Unterschieds zwischen MapReduce und Spark ist es ziemlich klar, dass SPARK im Vergleich zu Map Reduce eine weitaus fortschrittlichere Computer-Engine ist. Spark ist mit allen Dateiformaten kompatibel und auch schneller als Map Reduce. Darüber hinaus verfügt der Funke über Funktionen zur Grafikverarbeitung und zum maschinellen Lernen.
Auf der einen Seite ist Map Reduce auf die Stapelverarbeitung beschränkt und auf der anderen Seite kann Spark jede Art von Verarbeitung durchführen (Stapelverarbeitung, interaktive Verarbeitung, iterative Verarbeitung, Streaming-Verarbeitung, Diagrammverarbeitung). Aufgrund der großen Kompatibilität ist Spark der Favorit von Data Scientist und ersetzt daher Map Reduce und wächst schnell. Trotzdem müssen wir die Daten in HDFS speichern und manchmal brauchen wir auch HBase. Wir müssen also sowohl Spark als auch Hadoop ausführen, um die besten Ergebnisse zu erzielen.
Empfohlene Artikel:
Dies war ein Leitfaden für MapReduce vs Spark, deren Bedeutung, Kopf-an-Kopf-Vergleich, Hauptunterschiede, Vergleichstabelle und Schlussfolgerung. Sie können sich auch die folgenden Artikel ansehen, um mehr zu erfahren -
- 7 Wichtige Dinge über Apache Spark (Anleitung)
- Hadoop vs Apache Spark - Interessante Dinge, die Sie wissen müssen
- Apache Hadoop gegen Apache Spark | Top 10 Vergleiche, die Sie kennen müssen!
- Wie funktioniert MapReduce?
- Zusammenfluss von Technologie & Business Analytics