

Unterschied zwischen Apache Nifi und Apache Spark
Bis zu einer langen Zeit, als es eine schwere Arbeit gab, die erledigt werden musste, verließen sich die Menschen auf Pferde, um schwere Lasten zu ziehen, die Geschwindigkeit aufrechtzuerhalten oder irgendetwas anderes dazwischen. Allerdings waren nicht alle Pferde für jede Aufgabe geeignet. Dasselbe gilt für die heutige Technologie. Mit dem Aufkommen neuer Technologien, die jeden Tag einfließen, wird es äußerst wichtig, ihre tatsächlichen Anwendungen zu kennen. Zwei solche Technologien sind Apache Nifi und Apache Spark, und wir werden sie in diesem Beitrag untersuchen.
Apache Spark ist ein Open-Source-Framework für Cluster-Computing, das eine Schnittstelle für die Programmierung einer ganzen Reihe von Clustern mit impliziter Fehlertoleranz und Datenparallelität bereitstellen soll. Es verwendet RDDs (Resilient Distributed Datasets) und verarbeitet die Daten in Form von diskretisierten Streams, die zu Analysezwecken weiterverwendet werden.
Apache Nifi (die Kurzform von NiagaraFiles) ist ein weiteres Softwareprojekt, das darauf abzielt, den Datenfluss zwischen Softwaresystemen zu automatisieren. Das Design basiert auf einem flussbasierten Programmiermodell, das Funktionen bereitstellt, die das Arbeiten mit Clustern umfassen. Es ist ein einfach zu bedienendes, zuverlässiges und leistungsstarkes System zur Verarbeitung und Verteilung von Daten. Es unterstützt skalierbare gerichtete Diagramme für Datenrouting, Systemvermittlung und Transformationslogik. Lassen Sie uns die Vergleiche beider Themen diskutieren.
Head to Head Vergleich zwischen Apache Nifi und Apache Spark (Infografik)
Unten ist die Top 9 Vergleich zwischen Apache Nifi und Apache Spark
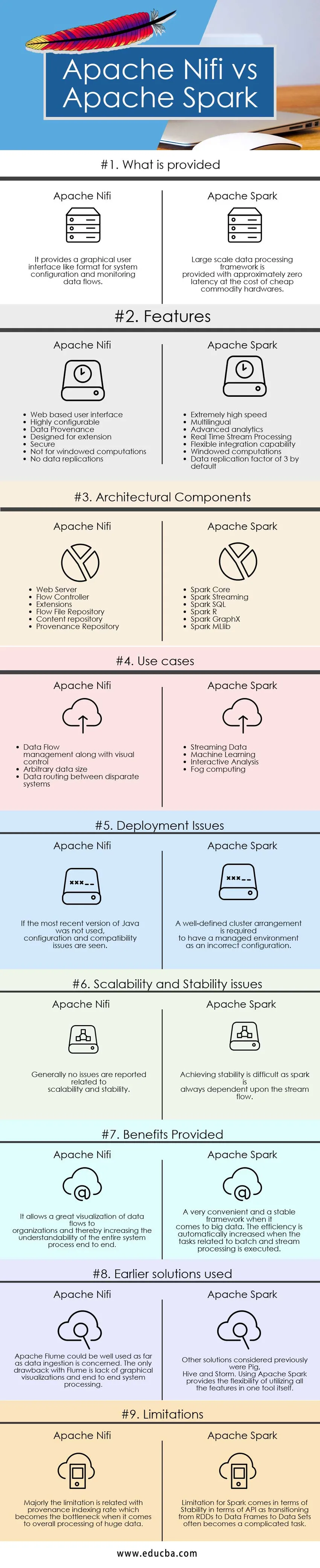
Hauptunterschiede zwischen Apache Nifi und Apache Spark
Die Unterschiede zwischen Apache Nifi und Apache Spark werden in den folgenden Punkten erläutert:
- Apache Nifi ist ein Tool zur Datenerfassung, mit dem ein benutzerfreundliches, leistungsstarkes und zuverlässiges System bereitgestellt wird, mit dem die Verarbeitung und Verteilung von Daten über Ressourcen einfach wird. Apache Spark ist eine extrem schnelle Cluster-Computing-Technologie, die für eine schnellere Berechnung durch entwickelt wurde Effiziente Nutzung interaktiver Abfragen bei der Speicherverwaltung und Stream-Verarbeitung.
- Apache Nifi arbeitet im Standalone-Modus und im Cluster-Modus, wohingegen Apache Spark im lokalen oder im Standalone-Modus, in Mesos, Yarn und anderen Arten von Big-Data-Cluster-Modi gut funktioniert.
- Zu den Funktionen von Apache Nifi gehören garantierte Datenübertragung, effiziente Datenpufferung, priorisierte Warteschlangen, Flow-spezifische QoS, Datenprovenanz, Wiederherstellung des Rollpuffers, visuelle Befehle und Kontrolle, Flow-Vorlagen, Sicherheit und paralleles Streaming. Zu den Funktionen von Apache Spark gehört Lightning Fast Geschwindigkeitsverarbeitungsfähigkeit, Mehrsprachigkeit, In-Memory-Computing, effiziente Nutzung von Standardhardwaresystemen, Advanced Analytics, effiziente Integrationsfähigkeit.
- Apache Nifi ermöglicht eine bessere Lesbarkeit und ein besseres Verständnis des Systems, indem Visualisierungsfunktionen und Drag & Drop-Funktionen bereitgestellt werden. Der Datenfluss kann mit herkömmlichen Techniken und Prozessen einfach verwaltet und gesteuert werden, während im Falle von Apache Spark ein Cluster-Management-System wie Ambari erforderlich ist, um diese Art von Visualisierungen anzuzeigen. Apache Spark an sich bietet keine Visualisierungsmöglichkeiten und ist nur in Bezug auf die Programmierung gut. Es ist bei weitem ein sehr komfortables und stabiles System für die Verarbeitung großer Datenmengen.
- Die Einschränkung bei Apache Nifi hängt mit dem Vorteil zusammen. Die einzige Drag-and-Drop-Funktion bietet die Einschränkung, dass die Integration mit anderen Komponenten und Tools nicht skalierbar und robust ist, während bei Apache Spark die Hauptbeschränkung in der Verwendung umfangreicher Standardhardware und deren Verwaltung besteht wird zuweilen zu einer mühsamen Aufgabe. Die andere gemeldete Einschränkung ergibt sich aus den Streaming-Funktionen für Discretized Stream und Windowed oder Batch-Stream, bei denen die Umwandlung von RDDs in Datenrahmen und Datensätze zuweilen zu Instabilitäten führt.
Apache Nifi vs Apache Spark Vergleichstabelle
| Vergleichsbasis | Apache Nifi | Apache Spark |
| Was ist vorgesehen | Es bietet eine grafische Benutzeroberfläche wie ein Format für die Systemkonfiguration und die Überwachung des Datenflusses. | Ein umfangreiches Datenverarbeitungs-Framework wird mit einer Latenz von ungefähr Null zu Lasten billiger Standardhardware bereitgestellt. |
| Eigenschaften |
|
|
| Architektonische Komponenten |
|
|
| Anwendungsfälle |
|
|
| Bereitstellungsprobleme | Wenn die neueste Version von Java nicht verwendet wurde, treten Konfigurations- und Kompatibilitätsprobleme auf | Eine genau definierte Clusteranordnung ist erforderlich, um eine verwaltete Umgebung als falsche Konfiguration zu haben |
| Skalierbarkeits- und Stabilitätsprobleme | Im Allgemeinen werden keine Probleme in Bezug auf Skalierbarkeit und Stabilität gemeldet | Das Erreichen von Stabilität ist schwierig, da ein Funke immer vom Stromfluss abhängt. |
| Vorteile zur Verfügung gestellt | Es ermöglicht eine hervorragende Visualisierung der Datenflüsse zu Organisationen und erhöht so die Verständlichkeit des gesamten Systemprozesses von Ende zu Ende | Ein sehr komfortables und stabiles Framework, wenn es um Big Data geht. Die Effizienz wird automatisch erhöht, wenn die Aufgaben im Zusammenhang mit der Stapel- und Stream-Verarbeitung ausgeführt werden. |
| Frühere Lösungen verwendet | Apache Flume könnte gut verwendet werden, wenn es um die Datenaufnahme geht. Der einzige Nachteil von Flume ist das Fehlen grafischer Visualisierungen und einer durchgängigen Systemverarbeitung | Andere Lösungen, die zuvor in Betracht gezogen wurden, waren Pig, Hive und Storm. Die Verwendung von Apache Spark bietet die Flexibilität, alle Funktionen in einem Tool selbst zu nutzen. |
| Einschränkungen | Die Einschränkung hängt hauptsächlich mit der Indizierungsrate der Provenienz zusammen, die zum Engpass bei der Gesamtverarbeitung großer Datenmengen wird | Die Einschränkung für Spark hängt mit der Stabilität der API zusammen, da der Übergang von RDDs zu Datenrahmen zu Datensätzen häufig zu einer komplizierten Aufgabe wird. |
Fazit - Apache Nifi vs Apache Spark
Um den Beitrag abzuschließen, kann gesagt werden, dass Apache Spark ein schweres Kriegspferd ist, während Apache Nifi ein flinkes Rennpferd ist. Beide haben ihre eigenen Vor- und Nachteile, die sie in ihren jeweiligen Bereichen nutzen können. Sie müssen das richtige Tool für Ihr Unternehmen auswählen. Weitere Artikel zu neueren Big-Data-Technologien finden Sie in unserem Blog.
Empfohlener Artikel
Dies war eine Anleitung zu Apache Nifi und Apache Spark, deren Bedeutung, Kopf-an-Kopf-Vergleich, Hauptunterschiede, Vergleichstabelle und Schlussfolgerung. Sie können sich auch die folgenden Artikel ansehen, um mehr zu erfahren -
- Apache Hadoop gegen Apache Spark | Top 10 Vergleiche, die Sie kennen müssen!
- Apache Storm vs Apache Spark - Lerne 15 nützliche Unterschiede
- 7 Wichtige Dinge über Apache Spark (Anleitung)
- Die besten 15 Dinge, die Sie über MapReduce vs Spark wissen müssen