
Was ist Cassandra?
Cassandra ist eine NoSQL-Datenbank, bei der es sich um eine Peer-to-Peer-Datenbank handelt. Es wird auf einem Cluster mit homogenen Knoten ausgeführt. Es ist so konzipiert, dass es mit großen Datenmengen umgehen kann. Der Umgang mit diesen Daten sollte auch in der Lage sein, eine hohe Leistungsfähigkeit zu erbringen. Cassandra bietet durchweg hohe Leistung beim Lesen und Schreiben. Die Architektur von Cassandra Cluster hat keine Master, Slaves oder spezifischen Anführer. Auf diese Weise wird sichergestellt, dass es keine einzelne Fehlerstelle gibt. Betrachten wir die Architektur im Detail.
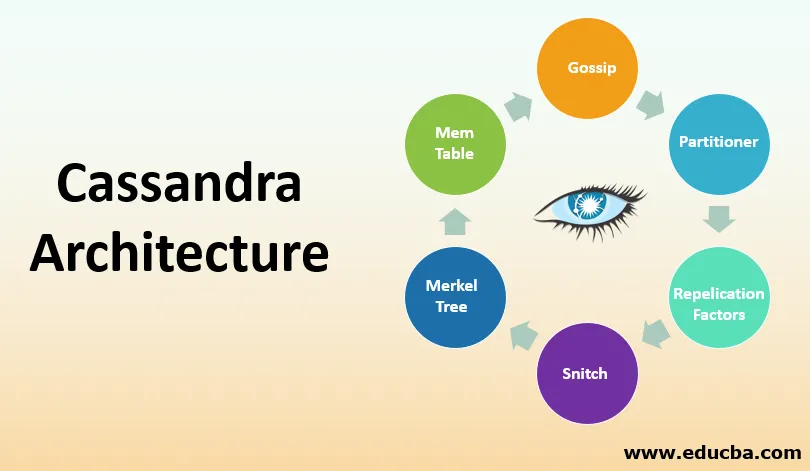
Cassandra Architektur
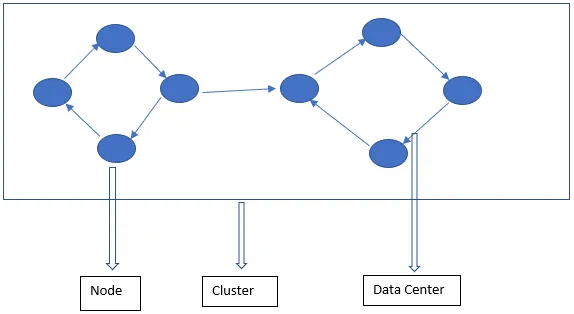
Die Cassandra-Architektur besteht hauptsächlich aus Knoten, Cluster und Rechenzentrum. Neben diesen gibt es auch andere Komponenten. Cassandra ist eine zeilengespeicherte Datenbank. Es ermöglicht autorisierten Benutzern, mithilfe von CQL eine Verbindung zu einem beliebigen Knoten in einem beliebigen Rechenzentrum herzustellen.
Schlüsselstrukturen in Cassandra
Dies sind die folgenden Schlüsselstrukturen in Cassandra:
- Knoten - Hier werden die Daten gespeichert. Es ist die grundlegendste Komponente von Cassandra. Es kann als ein einzelner Server in einem Rack betrachtet werden. Es stellt sicher, dass es keine einzelne Fehlerstelle gibt.
- Rechenzentrum - Ein Rechenzentrum ist eine Sammlung von Knoten. Dies kann entweder eine physische oder eine virtuelle sein. Je nach Auslastung werden Rechenzentren aufgeteilt und ausgewählt. Der Replikationsfaktor wird anhand des Rechenzentrums festgelegt. Abhängig von diesem Replikationsfaktor können Daten in verschiedene Rechenzentren geschrieben werden.
- Cluster - Cluster besteht aus einem oder mehreren Rechenzentren. Cluster erstrecken sich normalerweise über verschiedene physische Standorte.
Zusätzlich zu diesen sind die anderen Komponenten, die eine Rolle in Cassandra spielen, wie folgt.
1. Protokoll festschreiben
Die Daten, die zur Aufrechterhaltung der Haltbarkeit von Daten festgeschrieben werden, werden im Festschreibungsprotokoll gespeichert. Die Daten werden in eine sortierte Zeichenfolgentabelle verschoben (wird als Nächstes erläutert). Sobald diese Verschiebung abgeschlossen ist, kann das Festschreibungsprotokoll archiviert, gelöscht oder wiederverwendet werden.
2. SS-Tabelle
Diese Tabelle speichert, wie im vorherigen Punkt erwähnt, die Protokoll- oder Speichertabellen in regelmäßigen Abständen. Es ist eine unveränderliche Datendatei. SS-Tabellen können Daten häufig nacheinander speichern. Sie hängen Daten an und pflegen Informationen für jede Cassandra-Tabelle.
3. CQL-Tabelle
Die Cassandra-Abfragetabelle ist eine Sammlung geordneter Spalten, mit denen eine Zeile aus dieser Tabelle abgerufen werden kann. In dieser Tabelle sind Spalten gespeichert, in denen Daten mithilfe des Primärschlüssels abgerufen werden können.
4. Bloom Filter
Es ist eine einfache Art von Cache, in dem nicht deterministische Algorithmen zum Testen gespeichert sind. Es prüft, ob ein Element ein Mitglied der Menge ist oder nicht. Auf diese Filter wird normalerweise nach jeder ausgeführten Abfrage zugegriffen.
Wichtige Komponenten zur Konfiguration von Cassandra
Es gibt die folgenden Komponenten in Cassandra:
1. Klatsch
- Wie der Name schon sagt, muss es eine Kommunikation zwischen Peers geben, um den Standort und den Status von Informationen über alle Knoten zu ermitteln und auszutauschen.
- Diese Informationen sollten lokal gespeichert bleiben, damit jeder Knoten die Informationen verwenden kann, sobald ein Knoten neu gestartet werden muss. Knoten erkennen Informationen über andere Knoten, indem sie Informationen austauschen.
- Dies kann für maximal drei Knoten erfolgen. Die Informationen werden nicht mit jedem Knoten geteilt, der im Cluster oder Rechenzentrum vorhanden ist. Die Informationen werden mit einigen Knoten geteilt, aber schließlich werden die Statusinformationen im gesamten Cluster übertragen.
2. Partitionierer
- Der Partitionierer entscheidet, welcher Knoten das erste Replikat aller Daten erhalten soll. Es ist auch verantwortlich für die Verteilung dieser Repliken.
- Es wird festgelegt, welcher Knoten welche Replikation im Cluster haben soll. Jede Datenzeile sollte eindeutig identifiziert werden. Dies kann mithilfe eines Primärschlüssels oder eines Partitionsschlüssels erfolgen.
- Der Partitionierer ist eine Hash-Funktion, mit der ein Token von einem Primärschlüssel einer beliebigen Zeile abgerufen werden kann. Jedem Knoten ist ein num_token-Wert zugewiesen, der als Partitionierer festgelegt werden kann.
- Der generierte Tokenwert hilft beim Bestimmen, welcher Knoten die Replik der Zeilen empfängt.
3. Replikationsfaktor
- Dieser Faktor bestimmt die Gesamtzahl der im Cluster vorhandenen Replikate. Wenn der Replikationsfaktor 1 ist, befindet sich nur eine Kopie jeder Zeile auf einem Knoten.
- Wenn der Replikationsfaktor zwei beträgt, werden zwei Kopien verwaltet, wobei jede Kopie auf einem anderen Knoten vorhanden ist. Wie bereits erwähnt, gibt es in Cassandra keine Master-Slave-Architektur. Jede Kopie ist wichtig.
- Der Replikationsfaktor wird für jedes Rechenzentrum definiert. Dieser Faktor sollte größer als eins und nicht größer als die Anzahl der im Cluster vorhandenen Knoten sein.
4. Schnatz
- Die Replikationsstrategie, die dabei hilft, den Ort zu ermitteln, an dem Repliken für eine Gruppe von Computern im Rechenzentrum und im Rack platziert werden sollen, wird als Snitch bezeichnet.
- Es gibt eine dynamische Ebene, die bei der Überwachung und Leistung hilft und bei der Auswahl der besten Replik, von der Daten gelesen werden können. Snitches sollten nur konfiguriert werden, wenn ein Cluster erstellt wird.
- Für die meisten Bereitstellungen sind Standardwerte aktiviert. Die Konfigurationsänderungen können in der Datei Cassandra.yml vorgenommen werden, in der der dynamische Snitch-Schwellenwert für jeden Knoten vorhanden ist.
5. Merkle Tree
- Es kann Unterschiede in den Datenblöcken geben. Um die Unterschiede leicht zu finden, ist Merkle Tree ein Hash-Baum, der dabei hilft.
- Die Blattknoten des Hash-Baums enthalten Hashes von separaten Datenblöcken und Elternknoten haben die Informationen oder sie speichern auch die Hashes ihrer Kinder.
- Mit dieser Technik ist es einfacher, Unterschiede zwischen den vorhandenen Knoten zu finden.
6. Mem-Tabelle
- Diese Tabelle enthält Informationen zum Cache, dessen Daten noch nicht gelöscht wurden und der sich im Speicher befindet.
Fazit
Cassandra ist eine NoSQL-Datenbank, die bei der Verarbeitung großer Datenmengen hilfreich ist. Es gibt keine typische Master-Slave-Architektur und daher sind alle Knoten gleich wichtig. Die Knoten verfügen über Replikate im gesamten Cluster gemäß dem Replikationsfaktor. Dies stellt die Konsistenz und Beständigkeit der Daten sicher. Mit all diesen Funktionen ist klar, dass Cassandra für Big Data sehr nützlich ist. Cassandra ist daher langlebig, schnell und zuverlässig.
Empfohlene Artikel
Dies ist eine Anleitung zu Cassandra Architecture. Hier diskutieren wir die Einführung, die Cassandra-Architektur, die Schlüsselstruktur und die Schlüsselkomponenten von Cassandra. Sie können auch unsere anderen Artikelvorschläge durchgehen -
- Überblick über die Kubernetes-Architektur
- Was ist Big Data-Architektur?
- Zu AutoCAD Architecture hinzugefügte Funktionen
- Cloud-Computing-Architektur