

So installieren Sie Apache
Bevor wir uns mit der Installation des Apache-Teils befassen, möchten wir zunächst einen allgemeinen Überblick über Apache und dessen Verwendung in der Datenwissenschaft geben.
Was ist Apache?

Apache Web Server ist ein HTTP-Server, der Websites Besuchern präsentiert, die auf Ihren Server gelangen. Wenn Sie also eine Website für ein Unternehmen oder Ihre Organisation bereitstellen möchten, würden Sie dafür höchstwahrscheinlich Apache verwenden.
Es gibt andere HTTP-Server wie IIS, aber Apache ist der Standard, den die meisten Menschen verwenden, egal ob sie unter Linux, Windows oder Mac arbeiten. Apache ist die Standardeinstellung, zu der die meisten Leute gehen, weil es bekannt ist, sehr zuverlässig ist und kostenlos ist.
Bei Apache ist jedoch zu beachten, dass Sie, da es sich um einen HTTP-Server handelt, bei einer Installation unter Linux, Windows oder Mac lediglich statische Websites den Besuchern Ihres Servers präsentieren können. Wenn Sie eine HTML-Website ohne andere Programmiersprachen als JavaScript codieren, können Sie diese also nur mit einem Apache-Server verwenden. Sie können alle Ihre Tags in den Apache-Server stecken und Ihren Besuchern präsentieren.
Wie hat Apache in Data Science verwendet?
Data Science ist das gefragteste Studienfach der modernen Welt. Data Scientist gilt als der sexieste Job im 21. Jahrhundert, bei dem Fachleute aus verschiedenen Disziplinen lernen und Data Scientist werden möchten. Apache spielt eine entscheidende Rolle für jeden Data Science-Enthusiasten, da er ausreichende Kenntnisse des Apache Hadoop-Ökosystems benötigt.
Apache Hadoop-Ökosystem
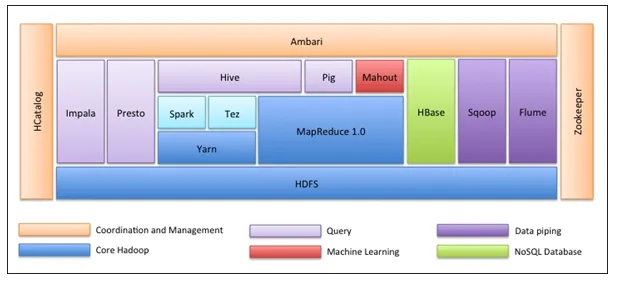
Das allererste ist, dass das Hadoop-Ökosystem kein einziges Werkzeug ist. Es ist keine Programmiersprache oder ein einzelnes Framework. Hierbei handelt es sich um eine Gruppe von Tools, die von verschiedenen Unternehmen in verschiedenen Domänen für mehrere Aufgaben zusammen verwendet werden. Wir werden jedes Werkzeug einzeln durchgehen:
- Apache HDFS (Hadoop Distributed File System) ist die Speichereinheit von Hadoop, in der strukturierte, halbstrukturierte und unstrukturierte Daten gespeichert werden können. HDFS verfügt über Metadaten, in denen die Protokolldatei zu den gespeicherten Daten gespeichert wird. Es besteht aus zwei Komponenten - NameNode und DataNode.
- Apache Yarn ist der Ressourcenverhandler, der alle Verarbeitungsaktivitäten wie das Planen von Aufgaben, das Zuweisen von Ressourcen usw. ausführt. Er hat zwei Dienste: Erstens den Ressourcenmanager, der Anwendungen plant, die auf Yarn ausgeführt werden. Zweitens überwacht der Node Manager die Ressourcennutzung .
- Apache Map Reduce ist die Datenverarbeitungskomponente von Hadoop, die große Datenmengen mithilfe von verteiltem und parallelem Computing verarbeitet, das auf den Funktionen Map, Sortieren und Mischen sowie Reduzieren basiert. Die Kartenfunktion filtert die Daten, sortiert und mischt sie. Am Ende fasst die Reduce-Funktion das Ergebnis zusammen.
- Apache Pig wird hauptsächlich in ETL verwendet. Es besteht aus zwei Teilen - Pig Latin und Pig Runtime. Pig Latin ist die Sprache, die für die Datenverarbeitung mithilfe einer Abfrage verwendet wird, während Pig Runtime die Ausführungsumgebung ist. Eine Zeile Pig Latin entspricht fast 100 Zeilen Map Reduce-Code. Bei diesem Vorgang werden zuerst die Daten geladen und dann in HDFS gruppiert, sortiert, gefiltert und gespeichert.
- Apache Hive verwendet eine SQL-ähnliche Abfrage, um Daten in einer verteilten Umgebung zu analysieren. Es besteht aus zwei Komponenten: der Hive-Befehlszeile und dem JDBC / ODBC-Server. Die verwendete Sprache heißt HiveQL.
- Apache Mahout ist die in Java geschriebene Maschinelle Lernbibliothek, mit der maschinelle Lernanwendungen wie Clustering, Klassifizierung oder Regression erstellt werden. Es verfügt über verschiedene Algorithmen für verschiedene Anwendungsfälle.
- Apache HBase ist eine in Java geschriebene NoSQL-Datenbank, die über Hadoop ausgeführt wird. Es basiert auf Googles BigTable und kann alle Arten von Daten verarbeiten.
- Apache Sqoop ist eines der Tools zur Datenerfassung, das für die strukturierte Datenübertragung zwischen RDBMS und Hadoop verwendet wird.
- Apache Flume ist ein weiteres Tool zur Datenerfassung, das für die halbstrukturierte und unstrukturierte Datenübertragung zwischen Hadoop und anderen Datenquellen verwendet wird.
- ZooKeeper ist der Koordinator, der die Koordination zwischen verschiedenen Tools im Hadoop-Ökosystem sicherstellt.
- Apache Ambari ist ein Cluster-Manager, der Hadoop-Cluster bereitstellt, verwaltet und auch deren Zustand und Status überwacht.
- Apache Tez ist ein neues Tool im Hadoop-Ökosystem, das die Abfrageverarbeitung von Hadoop beschleunigt.
- Apache Presto ist eine Open-Source-Abfrage-Engine für verteiltes SQL, die plattformübergreifende Abfragefunktionen ermöglicht.
- Apache HCatalog ist ein Metadaten- und Tabellenverwaltungssystem für Hadoop, das die Interoperabilität zwischen Datenverarbeitungstools ermöglicht. Außerdem können Benutzer die besten Tools für ihre Umgebung auswählen.
- Apache Spark ist das am weitesten verbreitete und beliebteste Framework unter Data Scientists. Es ist ein Hochgeschwindigkeits-Cluster-Computing-System, das die Ressourcennutzung bei vielen iterativen Aufgaben optimiert. Es bietet Flexibilität sowohl für die Stapelverarbeitung als auch für die Echtzeit-Datenanalyse.
Im Folgenden finden Sie die Schritte zum Installieren von Apache
Bisher haben wir etwas über Apache gelernt und wie nützlich es für alle ist, die Data Science oder Big Data Analytics erlernen möchten. Jetzt werden wir nach unten springen und Apache auf Windows installieren, basierend auf den folgenden Schritten.
- Gehen Sie zu https://httpd.apache.org/ und klicken Sie unter Apache httpd 2.4.38 Released auf den Link Download.

- Sie gelangen auf die folgende Seite und klicken auf Dateien für Microsoft Windows.
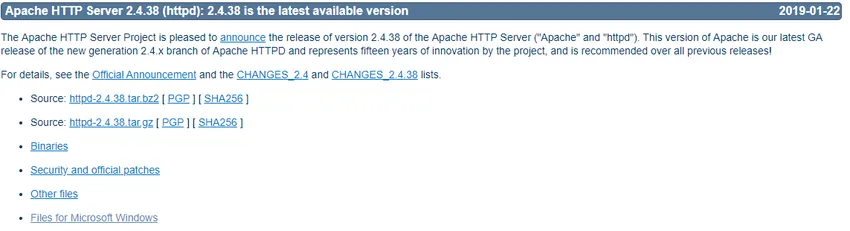
- Klicken Sie auf Apache Lounge.

- Sie können 32-Bit- oder 64-Bit-Dateien der ZIP-Datei herunterladen, die auf Ihrem Windows-Betriebssystem basieren. Wir werden die 64-Bit-Version hier herunterladen. Klicken Sie zum Herunterladen auf den entsprechenden .zip-Link.

- Jetzt ist C ++ Redistributable Visual Studio 2017 erforderlich. Daher werden wir es über den entsprechenden 32-Bit- oder 64-Bit-Link herunterladen

- Nachdem beide Dateien heruntergeladen wurden, gehen wir zuerst zum heruntergeladenen Speicherort und installieren C ++ Redistributable Visual Studio 2017. Doppelklicken Sie auf die EXE-Datei.

- Aktivieren Sie "Ich stimme zu" und klicken Sie auf "Installieren".

- Die Installation von Apache ist im Gange.
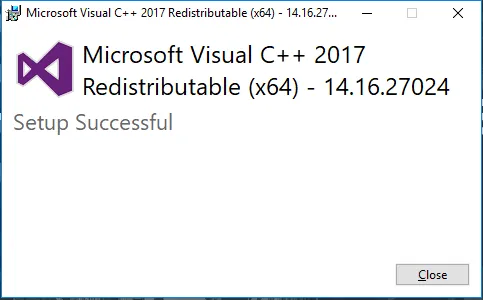
- Sobald es abgeschlossen ist, erhalten Sie eine Nachricht wie diese. Klicken Sie auf Schließen, um die Installation abzuschließen.
- Wechseln Sie nun zu dem Ordner, in den Sie die Apache-Zip-Datei heruntergeladen haben. Klicken Sie mit der rechten Maustaste darauf und wählen Sie hier extrahieren.
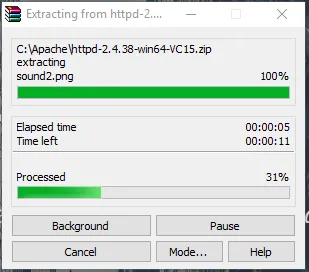
- Nun wird ein Apache24-Ordner erstellt. Kopieren Sie diesen Ordner auf Laufwerk C, und fügen Sie dann einen Pfad zu den Systemumgebungsvariablen hinzu.
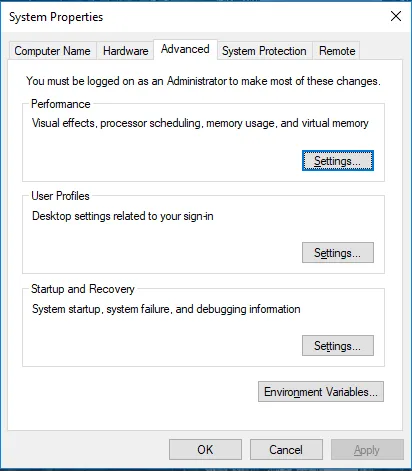
Gehen Sie zu Systemeigenschaften -> Registerkarte Erweitert -> Klicken Sie unten auf die Schaltfläche Umgebungsvariablen.
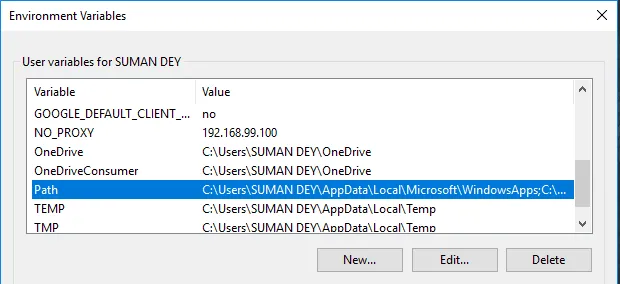
- Suchen Sie unter Variablen den Pfad und klicken Sie auf Bearbeiten.
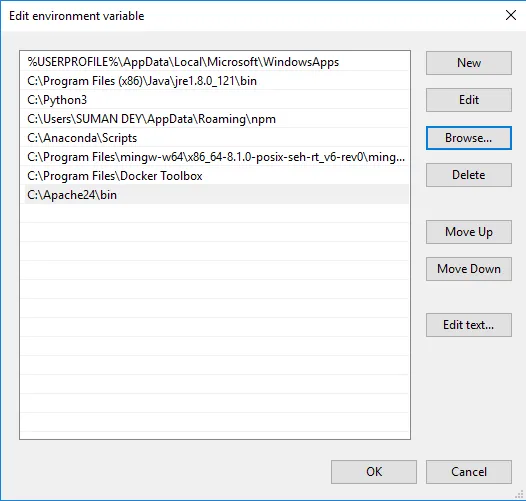
- Klicken Sie auf Durchsuchen -> Wechseln Sie zum Apache24-Ordner auf Laufwerk C -> Wählen Sie den Bin-Ordner aus -> Klicken Sie auf OK.
- Wir werden Apache als Windows-Dienst installieren. Führen Sie die Eingabeaufforderung als Administrator aus. Geben Sie httpd –k install ein und drücken Sie die Eingabetaste.
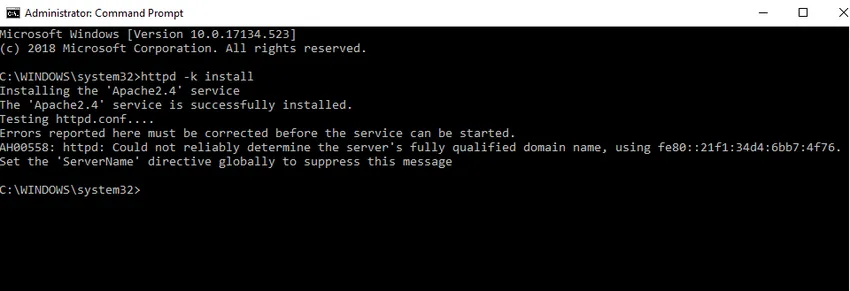
- Wir werden den Apache-Installationsdienst überprüfen. Klicken Sie auf das Windows-Symbol und geben Sie services ein. Klicken Sie auf die App Dienste und suchen Sie den Dienst mit dem Namen Apache24.

- Um den Apache-Server zu starten, klicken Sie mit der rechten Maustaste darauf und klicken Sie auf Start. Der Status ändert sich in "Laufen".
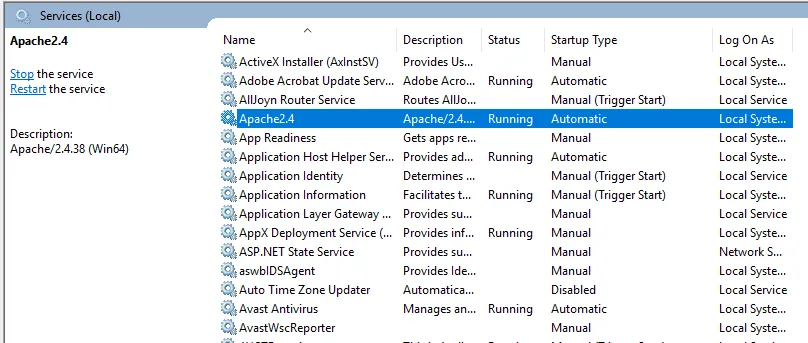
- Wir können mit einem Browser testen. Öffnen Sie einen Browser, navigieren Sie zu http: // localhost und drücken Sie die Eingabetaste. Eine Nachricht mit der Aufschrift "It works!" wird angezeigt, um die erfolgreiche Installation von Apache zu bestätigen.
Empfohlene Artikel
Dies war eine Anleitung zur Installation von Apache. Hier haben wir die Anweisungen und die verschiedenen Schritte zur Installation von Apache besprochen. Sie können auch den folgenden Artikel lesen, um mehr zu erfahren -
- Fragen in Vorstellungsgesprächen bei Apache
- Apache Spark gegen Apache Flink
- Apache Hadoop gegen Apache Spark
- Apache Kafka gegen Flume
- Kafka vs Kinesis | Top Unterschiede