

Was ist der Naive Bayes-Algorithmus?
Der Naive Bayes-Algorithmus ist eine Technik, mit der sich Klassifikatoren konstruieren lassen. Klassifizierer sind die Modelle, die die Probleminstanzen klassifizieren und ihnen Klassenbezeichnungen geben, die als Vektoren von Prädiktoren oder Merkmalswerten dargestellt werden. Es basiert auf dem Bayes-Theorem. Es wird als naives Bayes bezeichnet, da davon ausgegangen wird, dass der Wert eines Features unabhängig vom anderen Feature ist. Das Ändern des Werts eines Features würde sich nicht auf den Wert des anderen Features auswirken. Aus dem gleichen Grund wird es auch als Idiot Bayes bezeichnet. Dieser Algorithmus arbeitet effizient für große Datenmengen und ist daher am besten für Echtzeitvorhersagen geeignet.
Es ist hilfreich, die hintere Wahrscheinlichkeit P (c | x) unter Verwendung der vorherigen Wahrscheinlichkeit der Klasse P (c), der vorherigen Wahrscheinlichkeit des Prädiktors P (x) und der Wahrscheinlichkeit des Prädiktors einer gegebenen Klasse zu berechnen, die auch als Wahrscheinlichkeit P (x | c bezeichnet wird ).
Die Formel oder Gleichung zur Berechnung der hinteren Wahrscheinlichkeit lautet:
- P (c | x) = (P (x | c) · P (c)) / P (x)
Wie funktioniert der Naive Bayes Algorithmus?
Lassen Sie uns die Arbeitsweise des Naive-Bayes-Algorithmus anhand eines Beispiels verstehen. Wir setzen einen Trainingsdatensatz von Wetter und die Zielvariable 'Going shopping' voraus. Nun werden wir anhand der Wetterbedingungen klassifizieren, ob ein Mädchen einkaufen gehen wird.
Der angegebene Datensatz ist:
| Wetter | Einkaufen gehen |
| Sonnig | Nein |
| Regnerisch | Ja |
| Bedeckt | Ja |
| Sonnig | Ja |
| Bedeckt | Ja |
| Regnerisch | Nein |
| Sonnig | Ja |
| Sonnig | Ja |
| Regnerisch | Nein |
| Regnerisch | Ja |
| Bedeckt | Ja |
| Regnerisch | Nein |
| Bedeckt | Ja |
| Sonnig | Nein |
Die folgenden Schritte würden ausgeführt:
Schritt 1: Erstellen Sie Häufigkeitstabellen mit Datensätzen.
| Wetter | Ja | Nein |
| Sonnig | 3 | 2 |
| Bedeckt | 4 | 0 |
| Regnerisch | 2 | 3 |
| Gesamt | 9 | 5 |
Schritt 2: Erstellen Sie eine Wahrscheinlichkeitstabelle, indem Sie die Wahrscheinlichkeiten für jede Wetterbedingung berechnen und einkaufen gehen.
| Wetter | Ja | Nein | Wahrscheinlichkeit |
| Sonnig | 3 | 2 | 5/14 = 0, 36 |
| Bedeckt | 4 | 0 | 4/14 = 0, 29 |
| Regnerisch | 2 | 3 | 5/14 = 0, 36 |
| Gesamt | 9 | 5 | |
| Wahrscheinlichkeit | 9/14 = 0, 64 | 5/14 = 0, 36 |
Schritt 3: Nun müssen wir die posteriore Wahrscheinlichkeit unter Verwendung der Naive-Bayes-Gleichung für jede Klasse berechnen.
Problembeispiel: Ein Mädchen geht einkaufen, wenn das Wetter bewölkt ist. Ist diese Aussage richtig?
Lösung:
- P (Ja | Bedeckt) = (P (Bedeckt | Ja) * P (Ja)) / P (Bedeckt)
- P (Bedeckt | Ja) = 4/9 = 0, 44
- P (Ja) = 9/14 = 0, 64
- P (bewölkt) = 4/14 = 0, 39
Tragen Sie nun alle berechneten Werte in die obige Formel ein
- P (Ja | Bedeckt) = (0, 44 × 0, 64) / 0, 39
- P (Ja | Bedeckt) = 0, 722
Die Klasse mit der höchsten Wahrscheinlichkeit wäre das Ergebnis der Vorhersage. Mit demselben Ansatz können Wahrscheinlichkeiten verschiedener Klassen vorhergesagt werden.
Wofür wird der Naive Bayes-Algorithmus verwendet?
1. Echtzeitvorhersage: Der Naive Bayes-Algorithmus ist schnell und immer lernbereit. Daher eignet er sich am besten für Echtzeitvorhersagen.
2. Mehrklassenvorhersage : Die Wahrscheinlichkeit von Mehrklassen für eine Zielvariable kann unter Verwendung eines Naive-Bayes-Algorithmus vorhergesagt werden.
3. Empfehlungssystem: Der Naive Bayes-Klassifikator erstellt mit Hilfe von Collaborative Filtering ein Empfehlungssystem. Dieses System verwendet Data Mining- und Maschinelles Lernen-Techniken, um die Informationen zu filtern, die vorher nicht gesehen wurden, und dann vorherzusagen, ob ein Benutzer eine bestimmte Ressource schätzen würde oder nicht.
4. Textklassifizierung / Stimmungsanalyse / Spamfilterung: Aufgrund seiner besseren Leistung bei Problemen mit mehreren Klassen und seiner Unabhängigkeitsregel erzielt der Naive Bayes-Algorithmus eine bessere Leistung oder eine höhere Erfolgsquote bei der Textklassifizierung. Daher wird er in der Stimmungsanalyse und verwendet Spam-Filterung.
Vorteile des Naive-Bayes-Algorithmus
- Einfach zu implementieren
- Schnell
- Wenn die Unabhängigkeitsannahme gilt, arbeitet sie effizienter als andere Algorithmen.
- Es werden weniger Trainingsdaten benötigt.
- Es ist hoch skalierbar.
- Es kann probabilistische Vorhersagen treffen.
- Kann sowohl kontinuierliche als auch diskrete Daten verarbeiten.
- Unempfindlich gegenüber irrelevanten Merkmalen.
- Es kann leicht mit fehlenden Werten arbeiten.
- Einfach zu aktualisieren, wenn neue Daten eingehen.
- Am besten für Textklassifizierungsprobleme geeignet.
Nachteile des Naive Bayes-Algorithmus
- Die starke Annahme, dass die Merkmale unabhängig sein sollen, trifft in realen Anwendungen kaum zu.
- Datenknappheit.
- Wahrscheinlichkeit eines Genauigkeitsverlustes.
- Nullhäufigkeit, dh wenn die Kategorie einer kategorialen Variablen nicht im Trainingsdatensatz enthalten ist, weist das Modell dieser Kategorie eine Nullwahrscheinlichkeit zu, und es kann keine Vorhersage getroffen werden.
Wie man ein Grundmodell mit dem Naive Bayes Algorithmus erstellt
Es gibt drei Arten von Naive-Bayes-Modellen: Gauß-Modell, Multinomial-Modell und Bernoulli-Modell. Lassen Sie uns jeden von ihnen kurz besprechen.
1. Gaußsch: Der Gaußsche Naive-Bayes-Algorithmus geht davon aus, dass die stetigen Werte, die den einzelnen Merkmalen entsprechen, gemäß der Gaußschen Verteilung verteilt sind, die auch als Normalverteilung bezeichnet wird.
Die Wahrscheinlichkeit oder vorherige Wahrscheinlichkeit des Prädiktors der gegebenen Klasse wird als Gauß'sch angenommen, daher kann die bedingte Wahrscheinlichkeit wie folgt berechnet werden:
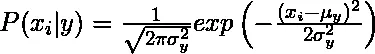
2. Multinomial: Die Häufigkeit des Auftretens bestimmter Ereignisse, die durch Merkmalsvektoren dargestellt werden, wird unter Verwendung einer Multinomialverteilung erzeugt. Dieses Modell wird häufig für die Klassifizierung von Dokumenten verwendet.
3. Bernoulli: In diesem Modell werden die Eingaben durch die Merkmale beschrieben, die unabhängige binäre Variablen oder Boolesche Werte sind. Dies wird auch häufig bei der Klassifizierung von Dokumenten wie Multinomial Naive Bayes verwendet.
Sie können jedes der oben genannten Modelle nach Bedarf verwenden, um den Datensatz zu verarbeiten und zu klassifizieren.
Sie können ein Gauß-Modell mit Python erstellen, indem Sie das folgende Beispiel verstehen:
Code:
from sklearn.naive_bayes import GaussianNB
import numpy as np
a = np.array((-2, 7), (1, 2), (1, 5), (2, 3), (1, -1), (-2, 0), (-4, 0), (-2, 2), (3, 7), (1, 1), (-4, 1), (-3, 7)))
b = np.array((3, 3, 3, 3, 4, 3, 4, 3, 3, 3, 4, 4, 4))
md = GaussianNB()
md.fit (a, b)
pd = md.predict (((1, 2), (3, 4)))
print (pd)
Ausgabe:
((3, 4))
Fazit
In diesem Artikel haben wir die Konzepte des Naive-Bayes-Algorithmus im Detail kennengelernt. Es wird hauptsächlich in der Textklassifikation verwendet. Es ist einfach zu implementieren und schnell auszuführen. Der Hauptnachteil besteht darin, dass die Funktionen unabhängig voneinander sein müssen, was in realen Anwendungen nicht der Fall ist.
Empfohlene Artikel
Dies war ein Leitfaden für den Naive Bayes-Algorithmus. Hier haben wir das Grundkonzept, die Funktionsweise, die Vor- und Nachteile des Naive-Bayes-Algorithmus besprochen. Sie können auch unsere anderen Artikelvorschläge durchgehen, um mehr zu erfahren -
- Boosting-Algorithmus
- Algorithmus in der Programmierung
- Einführung in den Algorithmus