

Einführung in Hive-Befehle
Hive Command ist ein Tool für die Data Warehouse-Infrastruktur, mit dem Big Data in Hadoop zusammengefasst werden kann. Es verarbeitet strukturierte Daten. Dies erleichtert das Abfragen und Analysieren von Daten. Der Befehl Hive wird auch als "Schema beim Lesen" bezeichnet. Hive überprüft Daten beim Laden nicht. Die Überprüfung erfolgt nur, wenn eine Abfrage ausgegeben wird. Diese Eigenschaft von Hive macht es schnell für das anfängliche Laden. Es ist so, als würde man eine Datei kopieren oder einfach verschieben, ohne Einschränkungen oder Überprüfungen vorzunehmen. Der Bienenstock wurde zuerst von Facebook entwickelt. Apache Software Foundation hat es später aufgegriffen und weiterentwickelt.
Hier sind die Komponenten des Hive-Befehls:
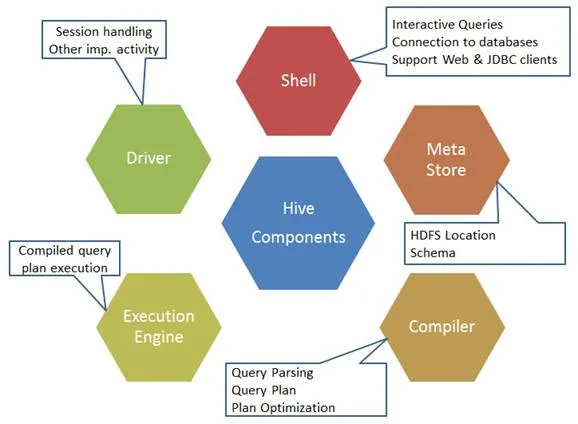
Abb. 1. Komponenten von Hive
https://www.developer.com/
Im Folgenden sind die Funktionen des Befehls Hive aufgeführt:
- Hive Stores sind rohe und verarbeitete Datensätze in Hadoop.
- Es ist für die Online-Transaktionsverarbeitung (OLTP) konzipiert. OLTP ist das System, das Daten mit hohem Datenvolumen in kürzester Zeit und ohne Abhängigkeit von einem einzelnen Server ermöglicht.
- Es ist schnell, skalierbar und zuverlässig.
- Die hier bereitgestellte Abfragesprache für den SQL-Typ heißt HiveQL oder HQL. Dies erleichtert ETL-Aufgaben und andere Analysen.
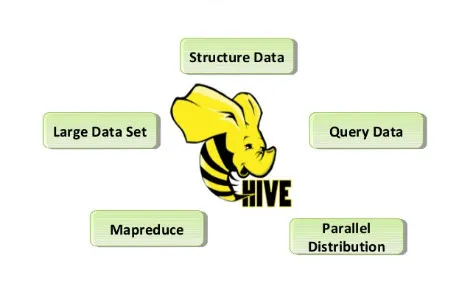
Abb. 2. Eigenschaften des Bienenstocks
Quellen Bilder: - Google
Es gibt auch einige Einschränkungen des Hive-Befehls, die nachfolgend aufgeführt sind:
- Hive unterstützt keine Unterabfragen.
- Hive unterstützt zwar das Überschreiben, aber leider nicht das Löschen und Aktualisieren.
- Hive ist nicht für OLTP konzipiert, wird jedoch dafür verwendet.
So rufen Sie die interaktive Shell des Hives auf:
$ HIVE_HOME / bin / hive
Grundlegende Hive-Befehle
-
Erstellen
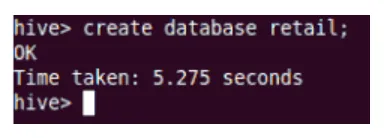
Dadurch wird die neue Datenbank in Hive erstellt.
-
Fallen
Der Abwurf entfernt einen Tisch aus Hive
-
Ändern
Mit dem Befehl Ändern können Sie die Tabelle oder die Tabellenspalten umbenennen.
Beispielsweise:
hive> ALTER TABLE employee RENAME TO employee1;
-
Show
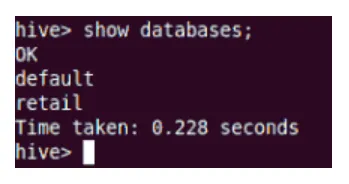
Mit dem Befehl Show werden alle Datenbanken in Hive angezeigt.
-
Beschreiben
Mit dem Befehl "Beschreiben" erhalten Sie Informationen zum Schema der Tabelle.
Intermediate Hive-Befehle
Hive unterteilt eine Tabelle basierend auf Spalten in unterschiedlich verwandte Partitionen. Mit diesen Partitionen wird es einfacher, Daten abzufragen. Diese Partitionen werden weiter in Buckets unterteilt, um Daten effizient abzufragen.
Mit anderen Worten, Buckets verteilen Daten in die Gruppe von Clustern, indem sie den in der Abfrage erwähnten Hashcode des Schlüssels berechnen.
-
Partition hinzufügen
Das Hinzufügen einer Partition kann durch Ändern der Tabelle erfolgen. Angenommen, Sie haben die Tabelle "EMP" mit Feldern wie ID, Name, Gehalt, Abteilung, Bezeichnung und Jahr.
Mitarbeiter von ALTER TABLE
> PARTITION HINZUFÜGEN (Jahr = '2012')
location '/ 2012 / part2012';
-
Partition umbenennen
Bienenstock> ALTER TABLE Mitarbeiter PARTITION (Jahr = '1203')
RENAME TO PARTITION (Yoj = '1203');
-
Partition löschen
hive> ALTER TABLE Mitarbeiter DROP (WENN EXISTIERT)
> PARTITION (Jahr = '1203');
-
Vergleichsoperatoren
Relationale Operatoren bestehen aus einer Reihe von Operatoren, mit deren Hilfe relevante Informationen abgerufen werden können.
Zum Beispiel: Sagen Sie, Ihre "EMP" -Tabelle sieht folgendermaßen aus:
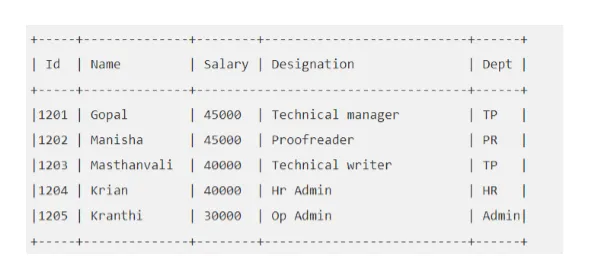
Lassen Sie uns eine Hive-Abfrage ausführen, die uns den Mitarbeiter abruft, dessen Gehalt über 30000 liegt.
hive> SELECT * FROM EMP WHERE Gehalt> = 40000;
-
Rechenzeichen
Hierbei handelt es sich um Operatoren, die bei der Ausführung von Rechenoperationen für die Operanden hilfreich sind und wiederum immer Zahlentypen zurückgeben.
Zum Beispiel: Hinzufügen von zwei Nummern wie 22 und 33
hive> SELECT 22 + 33 ADD FROM temp;
-
Logischer Operator
Diese Operatoren sollen logische Operationen ausführen, die im Gegenzug immer True / False zurückliefern.
hive> SELECT * FROM EMP WHERE Gehalt> 40000 && Dept = TP;
Erweiterte Hive-Befehle
-
Aussicht
Das Ansichtskonzept in Hive ist ähnlich wie in SQL. Die Ansicht kann zum Zeitpunkt der Ausführung einer SELECT-Anweisung erstellt werden.
Beispiel:
Bienenstock> CREATE VIEW EMP_30000 AS
SELECT * FROM EMP
WO Gehalt> 30000;
-
Daten in Tabelle laden
Struktur> Laden Sie den lokalen Datenpfad '/home/hduser/Desktop/AllStates.csv' in die Tabellenzustände.
Hier ist "States" die bereits erstellte Tabelle in Hive.
https://www.tutorialspoint.com/hive/
Hive verfügt über einige integrierte Funktionen, mit denen Sie Ihr Ergebnis besser abrufen können.
Wie rund, Boden, BIGINT usw.
-
Beitreten
Join-Klausel kann beim Verknüpfen von zwei Tabellen mit demselben Spaltennamen hilfreich sein.
Beispiel:
Bienenstock> Wählen Sie c.ID, c.NAME, c.AGE, o.AMOUNT
VON KUNDEN c BESTELLUNGEN BEITRETEN o
ON (c.ID = o.CUSTOMER_ID);
Alle Arten von Joins werden von Hive unterstützt: Left Outer Join, Right Outer Join, Full Outer Join.
Tipps und Tricks zum Verwenden von Hive-Befehlen
Hive macht die Datenverarbeitung so einfach, unkompliziert und erweiterbar, dass der Benutzer weniger auf die Optimierung der Hive-Abfragen achtet. Wenn Sie beim Schreiben von Hive-Abfragen jedoch auf wenige Dinge achten, können Sie mit Sicherheit die Arbeitslast sehr gut verwalten und Geld sparen. Nachfolgend einige Tipps dazu:
- Partitionen und Buckets: Hive ist ein Big-Data-Tool, mit dem große Datasets abgefragt werden können. Das Schreiben der Abfrage, ohne die Domäne zu verstehen, kann jedoch zu großen Partitionen in Hive führen.
Wenn dem Benutzer das Dataset bekannt ist, können relevante und häufig verwendete Spalten in derselben Partition gruppiert werden. Auf diese Weise können Sie die Abfrage schneller und ineffizienter ausführen.
Letztendlich die Nr. der Mapper- und I / O-Operationen werden ebenfalls reduziert.
Abb. 3. Partitionierung
Quellbilder: Google-Bild
Abb. 4 Schaufeln
Quellen Bilder: - Google-Bild
- Parallele Ausführung: Hive führt die Abfrage in mehreren Schritten aus. In einigen Fällen hängen diese Phasen von anderen Phasen ab und können daher nicht gestartet werden, sobald die vorherige Phase abgeschlossen ist. Unabhängige Tasks können jedoch parallel ausgeführt werden, um Gesamtlaufzeit zu sparen. So aktivieren Sie die parallele Ausführung in Hive:
setze hive.exec.parallel = true;
Dies verbessert daher die Clusterauslastung.
- Block Sampling: Durch das Abtasten von Daten aus einer Tabelle können Abfragen zu Daten untersucht werden.
Trotz des Ruckelns möchten wir den Datensatz eher zufällig auswählen. Die Blockabtastung verfügt über verschiedene leistungsstarke Syntaxfunktionen, mit denen die Daten auf verschiedene Weise abgetastet werden können.
Die Probenahme kann zum Auffinden von ca. Informationen aus dem Datensatz wie die durchschnittliche Entfernung zwischen Ursprung und Ziel.
Das Abfragen von 1% der Big Data ergibt nahezu die perfekte Antwort. Exploration wird viel einfacher und effektiver.
Fazit - Hive-Befehle
Hive ist eine übergeordnete Abstraktion über HDFS, die eine flexible Abfragesprache bietet. Es hilft bei der Abfrage und Verarbeitung von Daten auf einfachere Weise.
Hive kann mit anderen Big-Data-Elementen kombiniert werden, um seine Funktionalität voll auszuschöpfen.
Empfohlene Artikel
Dies war ein Leitfaden für Hive-Befehle. Hier haben wir grundlegende sowie erweiterte Hive-Befehle und einige unmittelbare Hive-Befehle besprochen. Sie können auch den folgenden Artikel lesen, um mehr zu erfahren -
- Fragen im Vorstellungsgespräch bei Hive
- Hive VS Hue - Top 6 nützliche Vergleiche
- Tableau-Befehle
- Adobe Photoshop-Befehle
- Verwenden der ORDER BY-Funktion in Hive
- Laden Sie Hive herunter und installieren Sie es Schritt für Schritt