

Unterschied zwischen Apache Hive und Apache HBase -
Die Geschichte von Apache Hive beginnt im Jahr 2007, als Nicht-Java-Programmierer Probleme mit der Verwendung von Hadoop MapReduce haben. Forscher und Entwickler sagten voraus, dass morgen eine Ära von Big Data ist. Es häuften sich bereits verschiedene Datenformate wie strukturiert, halbstrukturiert und unstrukturiert an. Sogar Facebook hatte mit der größeren Datenverarbeitung zu kämpfen. Forscher bei Facebook stellten Apache Hive für die Datenverarbeitung auf Hadoop Cluster vor. Facebook war das erste Unternehmen, das Apache Hive entwickelte.
Die Geschichte von Apache HBase beginnt im Jahr 2006, als das in San Francisco ansässige Startup Powerset versuchte, eine Suchmaschine in natürlicher Sprache für das Web zu entwickeln. HBase ist eine Implementierung von Googles Bigtable. Haben wir jemals realisiert, warum es notwendig war, eine weitere Speicherarchitektur zu entwickeln? Relational Database Management System gibt es seit Anfang der 1970er Jahre. Es gibt viele Anwendungsfälle, für die relationale Datenbanken durchaus sinnvoll sind, für einige spezifische Probleme passt das relationale Modell jedoch nicht sehr gut.
Lassen Sie mich Apache Hive und Apache HBase genauer erläutern.
Unterschiede zwischen Apache Hive und Apache HBase
Apache Hive ist ein Apache-Open-Source-Projekt, das auf Hadoop aufbaut, um große Datenmengen über eine SQL-ähnliche Oberfläche abzufragen, zusammenzufassen und zu analysieren. Apache Hive bietet eine SQL-ähnliche Sprache namens HiveQL, mit der Abfragen transparent in MapReduce konvertiert werden, um sie für große Datasets auszuführen, die im Hadoop Distributed File System (HDFS) gespeichert sind. Apache Hive ist eine Hadoop-Clusterkomponente, die normalerweise von Datenanalysten bereitgestellt wird. Apache Hive wird für die Stapelverarbeitung großer ETL-Jobs verwendet. Apache Hive unterstützt auch Batch-SQL-Abfragen für sehr große Datasets. Apache Hive erhöht die Flexibilität des Schemadesigns sowie die Serialisierung und Deserialisierung von Daten. Apache Hive unterstützt Online Transaction Processing (OLTP) nicht, da Hive keine Abfragen in Echtzeit und Aktualisierungen auf Zeilenebene unterstützt.
Apache HBase ist eine Open-Source-NoSQL-Datenbank, die Lese- und Schreibzugriff auf große Datenmengen in Echtzeit bietet. NoSQL ist eine nicht relationale Datenbank. Apache HBase ist eine verteilte spaltenorientierte Datenbank, die auf dem Hadoop Distributed File System (HDFS) ausgeführt wird. HBase bietet Hadoop die Vorteile von NoSQL. Apache HBase bietet Direktzugriffsfunktionen für in HDFS vorhandene Daten. Es nutzt die vom HDFS bereitgestellte Fehlertoleranz. Der Benutzer kann die Daten entweder direkt oder über HBase in HDFS speichern.
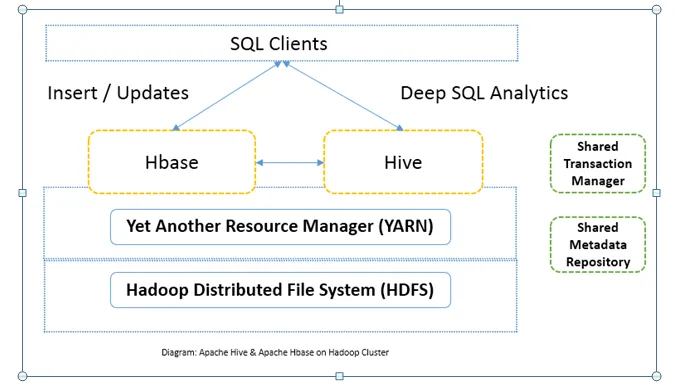
Head to Head Vergleich zwischen Apache HBase und Apache Hive (Infografik)
Nachfolgend finden Sie die 12 wichtigsten Unterschiede zwischen Apache Hive und Apache HBase

Hauptunterschiede - Apache Hive gegen Apache HBase
Nachfolgend finden Sie eine Liste der Punkte, in denen die wichtigsten Unterschiede zwischen Apache Hive und Apache HBase beschrieben sind:
- Apache HBase ist eine Datenbank, während Apache Hive eine Datenbank-Engine ist.
- Apache Hive wird hauptsächlich für die Stapelverarbeitung (OLAP) verwendet, während Apache HBase hauptsächlich für die Transaktionsverarbeitung (OLTP) verwendet wird.
- Apache Hive führt die meisten SQL-Abfragen aus, während Apache HBase SQL-Abfragen nicht direkt zulässt.
- Apache Hive unterstützt keine Operationen auf Aufzeichnungsebene wie Aktualisieren, Einfügen und Löschen, während Apache HBase Operationen auf Aufzeichnungsebene wie Aktualisieren, Einfügen und Löschen unterstützt.
- Apache Hive wird auf MapReduce ausgeführt, während Apache HBase auf Hadoop Distributed File System (HDFS) ausgeführt wird.
Apache Hive fragt die Dateien ab, indem eine virtuelle Tabelle definiert und darauf HQL-Abfragen ausgeführt werden. Hierbei handelt es sich um einen Prozess, bei dem Dateien virtuell mit einer tabellenartigen Struktur verbunden werden und der Benutzer Hive Query Language (HQL) ausführen kann. Diese Abfragen werden von Hive in MapReduce Job konvertiert. Der Benutzer muss keinen MapReduce-Job schreiben, HQL-Abfragen werden intern in JAR-Dateien konvertiert und diese JAR-Dateien werden in Datasets implementiert.
In Apache HBase werden Tabellen in Regionen aufgeteilt und von den Regionsservern bereitgestellt. Weitere Regionen werden vertikal durch Spaltenfamilien in Speicher unterteilt, und Speicher werden als Dateien in HDFS gespeichert.
Wann benutzt man Apache Hive:
- Data Warehousing-Anforderungen
- Analytische Abfragen
- Datenanalyse, die mit SQL vertraut sind
Wann benutzt man Apache HBase:
- Schnelle und interaktive Datenverarbeitung
- Echtzeit-Abfragen
- Schnelle Suchvorgänge
- Serverseitige Verarbeitung
- Zufälliger Lese- / Schreibzugriff auf Big Data
- Anwendungsskalierbarkeit
Mit Apache Hive können Trends und Protokolle der E-Commerce-Website für eine bestimmte Dauer, Region oder Zeitzone berechnet werden. Es kann verwendet werden, um Stapelabfragen über historische Daten zu verarbeiten, während Apache HBase von Facebook oder LinkedIn für Messaging und Echtzeitanalysen verwendet werden kann. Es kann auch zum Zählen von Likes verwendet werden.
Apache Hive vs Apache HBase Vergleichstabelle
Ich diskutiere Hauptartefakte und unterscheide zwischen Apache Hive und Apache HBase.
| Apache Hive | Apache HBase | |
| Datenverarbeitung | Apache Hive wird für verwendet
Stapelverarbeitung, dh Online Analytical Processing (OLAP) | Apache HBase wird für die Transaktionsverarbeitung verwendet, dh für die Online-Transaktionsverarbeitung (OLTP). |
| Verarbeitungsgeschwindigkeit | Apache Hive hat eine höhere Latenz, da MapReduce-Jobs im Hintergrund ausgeführt werden | Apache HBase arbeitet in Echtzeit und viel schneller als Apache Hive |
| Kompatibilität mit Hadoop | Apache Hive wird auf MapReduce ausgeführt | Apache HBase läuft auf HDFS |
| Definition | Apache Hive ist Open Source und ähnelt SQL für analytische Abfragen | Apache HBase ist eine Open-Source-NoSQL-Datenbank, die für Echtzeit-Abfragen verwendet wird |
| Freigegebene Metadaten | In Apache Hive erstellte Daten sind für Apache HBase automatisch sichtbar | In Apache HBase erstellte Daten sind für Apache Hive automatisch sichtbar |
| Schema | Apache Hive unterstützt Schema zum Einfügen von Daten in Tabellen | Apache HBase ist eine schemafreie Datenbank. |
| Update-Funktion | Die Update-Funktion ist in Apache Hive kompliziert | Der Benutzer kann die Daten in Apache HBase sehr einfach aktualisieren |
| Operationen | Vorgänge in Apache Hive werden nicht in Echtzeit ausgeführt | Operationen in Apache HBase werden in Echtzeit ausgeführt |
| Datentypen | Apache Hive ist für strukturierte und semi-strukturierte Daten gedacht | Apache HBase ist für unstrukturierte Daten. |
| Konsistenzlevel | Apache Hive unterstützt Eventual Consistency | Apache HBase unterstützt die sofortige Konsistenz |
| Partitionsmethoden | Apache Hive unterstützt Sharding-Funktionen | Apache HBase unterstützt auch Sharding-Funktionen |
| Datenspeicher | Das Datum wird in Hive Metastore, Partitionen und Buckets in Apache Hive gespeichert | Daten werden in Apache HBase spalten- und zeilenweise in Tabellen gespeichert |
Fazit - Apache Hive vs Apache HBase
In der Regel werden Apache Hive und Apache HBase gemeinsam im selben Cluster verwendet. Beide können zusammen verwendet werden, um die Verarbeitungsleistung zu verbessern. Da Hive die analytischen Seiten von HDFS verbessert, verbessert HBase die Transaktionen in Echtzeit. Der Benutzer kann Hive als ETL-Tool für Batch-Einfügungen mit den Daten in HBase verwenden und dann Abfragen ausführen, mit denen in HBase-Tabellen vorhandene Daten mit den bereits in HDFS vorhandenen Daten verknüpft werden können. Daten können von Apache Hive zu HBase und wieder zurück gelesen und geschrieben werden. Die Schnittstelle zwischen Apache Hive und Apache HBase ist noch in der Reifephase. Es kommt noch viel mehr. Dennoch kann ich sagen, dass sowohl Apache Hive als auch Apache HBase den Hadoop-Cluster robuster und leistungsfähiger machen.
In Verbindung stehende Artikel:
Dies war eine Anleitung zu Apache Hive und Apache HBase, deren Bedeutung, Kopf-an-Kopf-Vergleich, Hauptunterschiede, Vergleichstabelle und Schlussfolgerung. Sie können sich auch die folgenden Artikel ansehen, um mehr zu erfahren -
- Top 5 Big Data-Trends
- 5 Herausforderungen von Big Data Analytics
- Wie knackt man das Hadoop-Entwicklerinterview?
- 5 Herausforderungen von Big Data Analytics