

Was ist der MapReduce-Algorithmus?
Der MapReduce-Algorithmus ist hauptsächlich vom funktionalen Programmiermodell inspiriert. Es wird zur Verarbeitung und Generierung von Big Data verwendet. Diese Datensätze können gleichzeitig ausgeführt und in einem Cluster verteilt werden. Ein MapReduce-Programm besteht hauptsächlich aus einer Kartenprozedur und einer Reduktionsmethode, um die Zusammenfassungsoperation wie das Zählen oder das Erzielen einiger Ergebnisse durchzuführen. Das MapReduce-System funktioniert auf verteilten Servern, die parallel ausgeführt werden und die gesamte Kommunikation zwischen verschiedenen Systemen verwalten. Das Modell ist eine spezielle Strategie der Split-Apply-Combine-Strategie, die bei der Datenanalyse hilft. Das Mapping wird von der Mapper-Klasse durchgeführt und die Aufgabe wird von der Reducer-Klasse reduziert.
Grundlegendes zum MapReduce-Algorithmus
Der MapReduce-Algorithmus arbeitet hauptsächlich in drei Schritten:
- Kartenfunktion
- Shuffle-Funktion
- Funktion reduzieren
Besprechen wir jede Funktion und ihre Verantwortlichkeiten.
1. Kartenfunktion
Dies ist der erste Schritt des MapReduce-Algorithmus. Es nimmt die Datensätze und verteilt sie auf kleinere Unteraufgaben. Dies erfolgt in zwei Schritten, Aufteilen und Zuordnen. Bei der Aufteilung wird der Eingabedatensatz und der Datensatz geteilt, während bei der Zuordnung diese Untergruppen von Daten erfasst und die erforderliche Aktion ausgeführt werden. Die Ausgabe dieser Funktion ist ein Schlüssel-Wert-Paar.
2. Shuffle-Funktion
Dies wird auch als Kombinationsfunktion bezeichnet und umfasst das Zusammenführen und Sortieren. Beim Zusammenführen werden alle Schlüssel-Wert-Paare kombiniert. Alle diese haben die gleichen Schlüssel. Beim Sortieren werden die Eingaben aus dem Zusammenführungsschritt übernommen und alle Schlüssel-Wert-Paare mithilfe der Schlüssel sortiert. Dieser Schritt kehrt auch zu den Schlüssel-Wert-Paaren zurück. Die Ausgabe wird sortiert.
3. Funktion reduzieren
Dies ist der letzte Schritt dieses Algorithmus. Es nimmt die Schlüssel-Wert-Paare aus der Zufallswiedergabe und reduziert die Operation.
Wie erleichtert MapReduce-Algorithmen die Arbeit?
Die relationalen Datenbanksysteme verfügen über einen zentralen Server, der beim Speichern und Verarbeiten der Daten hilft. Dies waren in der Regel zentralisierte Systeme. Wenn mehrere Dateien in das Bild aufgenommen werden, ist die Verarbeitung mühsam und führt bei der Verarbeitung mehrerer Dateien zu einem Engpass. MapReduce ordnet die Datenmenge zu und konvertiert die Datenmenge, in der alle Daten in Tupel unterteilt sind, und die Reduktionsaufgabe übernimmt die Ausgabe dieses Schritts und kombiniert diese Datentupel zu den kleineren Mengen. Es arbeitet in verschiedenen Phasen und erzeugt Schlüssel-Wert-Paare, die auf verschiedene Systeme verteilt werden können.
Was können Sie mit MapReduce-Algorithmen tun?
MapReduce kann mit einer Vielzahl von Anwendungen verwendet werden. Es kann für verteilte musterbasierte Suche, verteilte Sortierung, Umkehrung von Weblink-Diagrammen und Webzugriffsprotokollstatistiken verwendet werden. Es kann auch beim Erstellen und Bearbeiten mehrerer Cluster, Desktop-Grids und ehrenamtlicher Computerumgebungen hilfreich sein. Man kann auch dynamische Cloud-Umgebungen, mobile Umgebungen und auch Hochleistungs-Computing-Umgebungen erstellen. Google nutzte MapReduce, um den Google-Index des World Wide Web neu zu generieren. Durch die Verwendung werden die alten Ad-hoc-Programme aktualisiert und sie haben verschiedene Arten von Analysen ausgeführt. Außerdem wurden die Live-Suchergebnisse integriert, ohne dass der gesamte Index neu erstellt werden musste. Alle Ein- und Ausgaben werden im verteilten Dateisystem gespeichert. Die vorübergehenden Daten werden auf einer lokalen Festplatte gespeichert.
Arbeiten mit dem MapReduce-Algorithmus
Um mit MapReduce-Algorithmus arbeiten zu können, müssen Sie den vollständigen Prozess kennen. Die aufgenommenen Daten durchlaufen folgende Schritte:
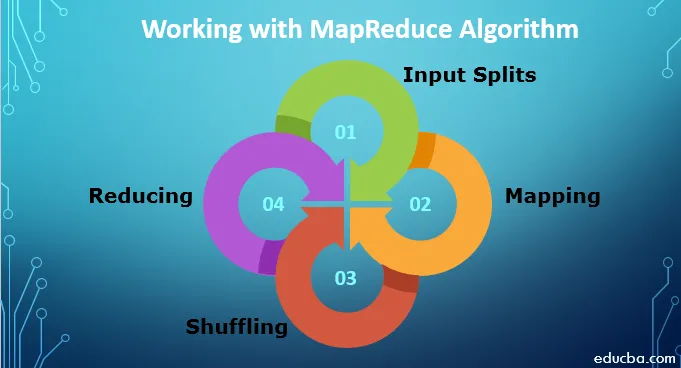
1. Eingabesplits: Alle Eingabedaten, die zum MapReduce-Job kommen, werden in gleiche Teile aufgeteilt, die als Eingabesplits bezeichnet werden. Es ist ein Teil der Eingabe, der von jedem der Mapper verarbeitet werden kann.
2. Mapping: Sobald die Daten in Chunks aufgeteilt sind, durchlaufen sie die Mapping-Phase im Map-Reduction-Programm. Diese aufgeteilten Daten werden an die Zuordnungsfunktion übergeben, die unterschiedliche Ausgabewerte erzeugt.
3. Mischen: Sobald die Zuordnung abgeschlossen ist, werden die Daten an diese Phase gesendet. Seine Aufgabe ist es, die erforderlichen Datensätze aus der vorherigen Phase zusammenzuführen.
4. Reduzieren: In dieser Phase wird die Ausgabe der Mischphase aggregiert. In dieser Phase werden alle Werte gemischt und durch Aggregation zusammengeführt, sodass ein einzelner Ausgabewert zurückgegeben wird. Es wird eine Zusammenfassung des gesamten Datensatzes erstellt.
Vorteile des MapReduce-Algorithmus
Die Anwendungen, die MapReduce verwenden, bieten die folgenden Vorteile:
- Sie wurden mit Konvergenz und einer guten Verallgemeinerungsleistung ausgestattet.
- Daten können mithilfe datenintensiver Anwendungen verarbeitet werden.
- Es bietet eine hohe Skalierbarkeit.
- Das Zählen jedes Vorkommens jedes Wortes ist einfach und verfügt über eine umfangreiche Dokumentensammlung.
- Ein generisches Tool kann verwendet werden, um in vielen Datenanalysen nach Werkzeugen zu suchen.
- Es bietet Lastausgleichszeit in großen Clustern.
- Es hilft auch beim Extrahieren von Kontexten von Benutzerstandorten, Situationen usw.
- Es kann schnell auf große Stichproben von Befragten zugreifen.
Warum sollten wir den MapReduce-Algorithmus verwenden?
MapReduce ist eine Anwendung, die zur Verarbeitung großer Datenmengen verwendet wird. Diese Datensätze können parallel verarbeitet werden. MapReduce kann möglicherweise große Datenmengen und eine große Anzahl von Knoten erstellen. Diese großen Datenmengen werden in HDFS gespeichert, was die Analyse von Daten erleichtert. Es kann jede Art von Daten wie strukturierte, unstrukturierte oder halbstrukturierte verarbeiten.
Warum brauchen wir den MapReduce-Algorithmus?
MapReduce wächst rasant und hilft beim parallelen Rechnen. Es hilft bei der Bestimmung des Preises für Produkte und hilft bei der Erzielung der höchsten Gewinne. Es hilft auch bei der Vorhersage und Empfehlung von Analysen. Es ermöglicht Programmierern, Modelle über verschiedene Datensätze auszuführen, und verwendet fortgeschrittene statistische Techniken und Techniken des maschinellen Lernens, die bei der Vorhersage von Daten helfen. Es filtert und sendet die Daten an verschiedene Knoten innerhalb des Clusters und funktioniert wie die Mapper- und Reducer-Funktion.
Wie hilft Ihnen diese Technologie beim Karrierewachstum?
Hadoop gehört heutzutage zu den meistgesuchten Jobs. Es beschleunigt die Geschwindigkeit und die Chance, die in diesem Bereich sehr schnell wachsen. In diesem Bereich wird es noch mehr Booms geben. Die IT-Experten, die in Java arbeiten, haben ein Plus, da sie die gefragtesten Personen sind. Entwickler, Datenarchitekten, Data Warehouse- und BI-Experten können durch das Erlernen dieser Technologie enorme Gehaltsmengen einsparen.
Fazit
MapReduce ist die Basis des Hadoop-Frameworks. Wenn Sie dies lernen, werden Sie mit Sicherheit in den Markt für Datenanalysen einsteigen. Sie können es gründlich lernen und erfahren, wie große Datenmengen verarbeitet werden und wie diese Technologie die Verarbeitung und Speicherung von Daten verändert.
Empfohlene Artikel
Dies ist eine Anleitung zu MapReduce-Algorithmen. Hier diskutieren wir das Konzept, das Verständnis, das Arbeiten, die Bedürfnisse, die Vorteile und das Karrierewachstum. Sie können auch unsere anderen Artikelvorschläge durchgehen, um mehr zu erfahren -
- Fragen in Vorstellungsgesprächen bei MapReduce
- Was ist MapReduce in Hadoop?
- Wie funktioniert MapReduce?
- Was ist MapReduce?
- Unterschiede zwischen Hadoop und MapReduce
- Verschiedene Operationen in Bezug auf Tupel