
Einführung in Python-Sets
In diesem Artikel werden wir Sets in Python behandeln. Python ist eine sehr vielseitige Sprache und wird schnell zu einer der wichtigsten Sprachen im Bereich der Datenwissenschaft, da es leicht zu verstehen ist, zu lesen und zu schreiben und auch auf dem OOPs-Konzept basiert. Set ist eine ungeordnete Sammlung, die in Python durch geschweifte Klammern dargestellt wird. Unbestellt bedeutet hier, dass Sie nicht sicher sind, in welcher Reihenfolge die Artikel erscheinen. Set unterscheidet sich von einer Liste dadurch, dass nur eindeutige Elemente und keine doppelten Elemente gespeichert werden können.
Syntax:
Wie bei Python allgemein ist die Syntax im Allgemeinen einfach. Die Syntax für den Python-Satz lautet wie folgt:
firstset = ("Johnny", "Nilanjan", "Rupa")
print(firstset)
Hier ist der erste Satz der Variablenname, in dem der Satz gespeichert ist. Die geschweiften Klammern () stehen für set und da wir Zeichenfolgenwerte hinzufügen, sind doppelte / einfache Anführungszeichen erforderlich. Die Werte in der Menge werden durch Kommas getrennt. Nun, da wir die Syntax der Menge mit einem Beispiel in Python gesehen haben. Lassen Sie uns nun die verschiedenen Methoden diskutieren, die in Python-Sets verwendet werden.
Verschiedene Methoden in Python-Sets
Lassen Sie uns die verschiedenen Methoden durchgehen, die in Python for Sets integriert sind.
1. add (): Wie der Name vermuten lässt, wurde hiermit ein neues Element in die Menge eingefügt. Dies bedeutet, dass Sie die Anzahl der Elemente in der Menge um eins erhöhen. Ein sehr wichtiges Wissen über Mengen, das beachtet werden muss, ist, dass das Element nur hinzugefügt wird, wenn es nicht bereits in den Mengenassets vorhanden ist. Verwenden Sie keine doppelten Elemente. Die add-Methode gibt auch keinen Wert zurück. Lassen Sie uns ein Beispiel machen.
Code:
firstset = ("Johnny", "Nilanjan", "Rupa")
firstset.add("Sepoy")
print("The new word is", firstset)
#to check duplicate property of Set
firstset.add("Sepoy")
print("The new word is", firstset)
Der folgende Screenshot zeigt die Ausgabe des Codes, wenn er auf Jupyter Notebook ausgeführt wird.
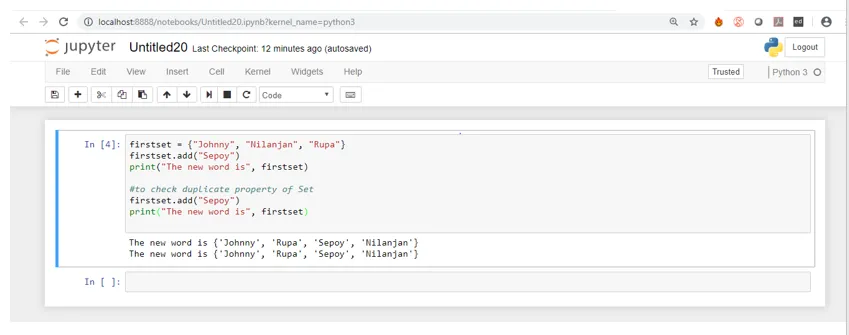
Wenn Sie die Ausgabe zum ersten Mal sehen, fügt sie bei Verwendung der Funktion add () das Element hinzu, und die Größe der Menge wird um eins erhöht, wie gezeigt, wenn wir die erste print-Anweisung ausführen, aber beim zweiten Mal, wenn wir die Methode add () verwenden Um dasselbe Element (Sepoy) wie beim ersten Mal hinzuzufügen, werden beim Ausführen der print-Anweisung dieselben Elemente angezeigt, ohne dass die Größe des Sets erhöht wird. Dies bedeutet, dass das Set keine doppelten Werte annimmt.
2. clear (): Wie der Name schon sagt, werden alle Elemente aus der Menge entfernt. Es akzeptiert weder Parameter noch gibt es einen Wert zurück. Wir müssen nur die clear-Methode aufrufen und ausführen. Schauen wir uns ein Beispiel an:
Code:
firstset = ("Johnny", "Nilanjan", "Rupa")
print("Before clear", firstset)
firstset.clear()
print("After clear", firstset)
Schauen wir uns die Ausgabe an, nachdem wir den gleichen Code im jupyter Notebook ausgeführt haben.
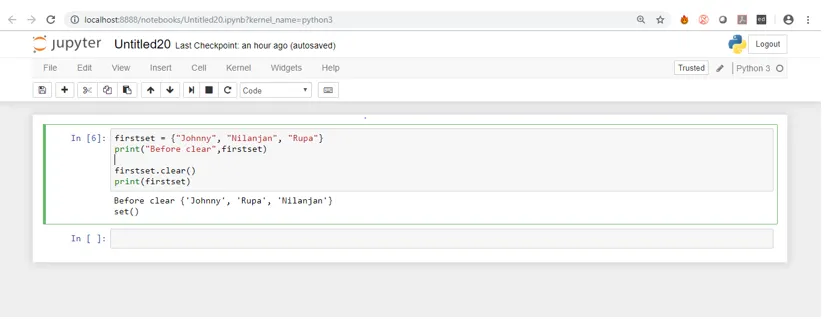
Der obige Screenshot zeigt also, dass die Liste mit Elementen gedruckt wurde, bevor wir die clear-Methode ausgeführt haben. Als wir dann die clear () -Methode ausgeführt haben, wurden alle Elemente entfernt und wir haben einen leeren Satz übrig gelassen.
3. copy (): Mit dieser Methode wird eine flache Kopie eines Sets erstellt. Der Begriff "flache Kopie" bedeutet, dass das ursprüngliche Set nicht geändert wird, wenn Sie dem Set neue Elemente hinzufügen oder Elemente aus dem Set entfernen. Dies ist der grundlegende Vorteil der Verwendung der Kopierfunktion. Wir werden ein Beispiel sehen, um das Konzept der flachen Kopie zu verstehen.
Code:
originalset = ("Johnny", "Nilanjan", "Rupa")
copiedset = originalset.copy()
print("originalset:: ", originalset)
print("copiedset:: ", copiedset)
# modify the copiedset to check shallow copy feature
copiedset.add("Rocky")
print("originalset:: ", originalset)
print("copiedset:: ", copiedset)
Lassen Sie uns nun die Ausgabe in Jupyter Notebook überprüfen.
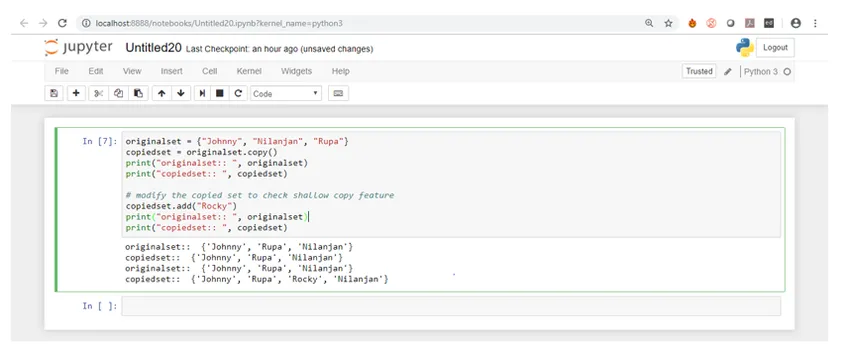
Wie Sie sehen, wurde beim Hinzufügen von Funktionen zum Hinzufügen eines neuen Elements zum kopierten Satz der kopierte Satz geändert, der ursprüngliche Satz blieb jedoch unverändert.
4. difference (): Dies ist eine sehr wichtige Funktion. Diese Funktion gibt einen Satz zurück, der die Differenz zwischen zwei Sätzen darstellt. Beachten Sie, dass Differenz hier nicht Subtraktion bedeutet, da es sich hier um die Differenz zwischen der Anzahl der Elemente in zwei Mengen und nicht um die Werte der Elemente handelt. Hier bedeutet zum Beispiel Set A1 - Set A2, dass es ein Set mit Elementen zurückgibt, die in A1, aber nicht in A2 vorhanden sind, und umgekehrt, wenn Set A2 - Set A1 (in A2 vorhanden, aber nicht in A1). Gleiches wird nachfolgend anhand eines Beispiels erläutert.
Code:
A1= (24, 35, 34, 45)
A2= (24, 56, 35, 46)
print(A1.difference(A2))
print(A2.difference(A1))
Betrachten wir nun die Ausgabe im folgenden Screenshot.
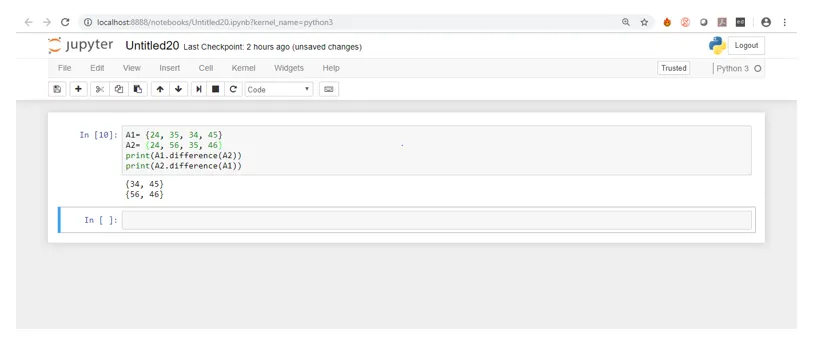
Wenn Sie sich den Screenshot oben genau ansehen, besteht ein Unterschied zwischen dem ersten und dem zweiten Ergebnis. Im ersten Ergebnis werden die Elemente gezeigt, die in A, aber nicht in B sind, während im zweiten Ergebnis Elemente gezeigt werden, die in B, aber nicht in A vorhanden sind.
5. intersection (): Es unterscheidet sich sehr von der vorherigen Methode Built-In-Set. In diesem Fall werden nur die Elemente in Form einer Menge zurückgegeben, die in beiden Mengen oder in mehreren Mengen (bei mehr als zwei Mengen) gemeinsam sind. Lassen Sie uns nun ein Beispiel durchgehen.
Code:
A1= (24, 35, 34, 45)
A2= (24, 56, 35, 46)
A3= (24, 35, 47, 56)
print(A1.intersection(A2, A3))
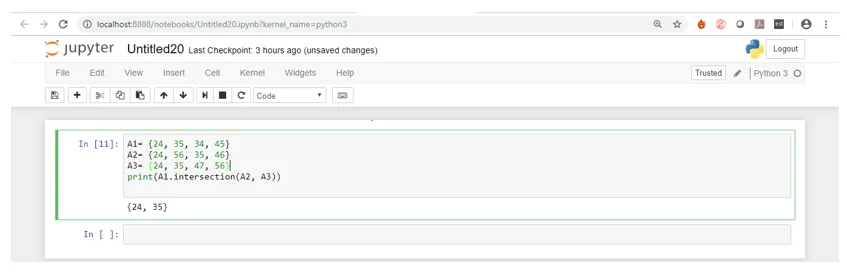
Wie Sie sehen, hatten die drei Mengen nur zwei Elemente gemeinsam, nämlich 24 und 35. Bei der Ausführung des Codes wurde eine Menge zurückgegeben, die nur 24 und 35 enthielt.
6. union (): Dies ist eine Funktion, die eine Menge mit allen Elementen der ursprünglichen Menge und auch den angegebenen Mengen zurückgibt. Da es einen Satz zurückgibt, haben alle Elemente nur ein Erscheinungsbild. Wenn zwei Sätze den gleichen Wert enthalten, wird das Element nur einmal angezeigt.
Code:
A1= (24, 35, 34, 45)
A2= (24, 56, 35, 46)
A3= (24, 35, 47, 56)
print(A1.union(A2, A3))
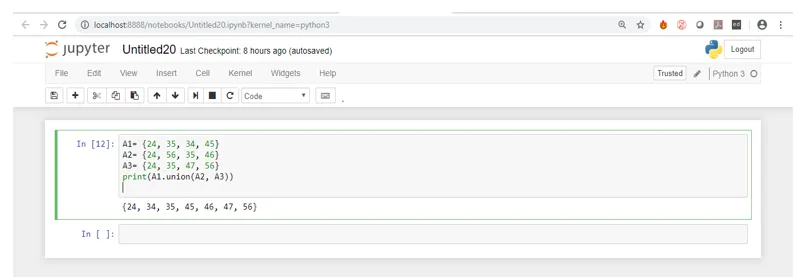
Im obigen Screenshot sehen Sie die Ausgabe des Codes bei der Ausführung. Wenn Sie genau hinsehen, finden Sie alle Werte von A1 und alle eindeutigen Werte aus den beiden anderen Sätzen.
7. issubset (): Diese Funktion gibt boolesche Werte zurück, die wahr oder falsch sind. Wenn alle Elemente einer Menge in einer anderen Menge vorhanden sind, wird true zurückgegeben, andernfalls false. Wir werden ein Beispiel davon sehen, um es besser zu verstehen.
Code:
A1 =(3, 6, 8)
A2 =(45, 87, 3, 67, 6, 8)
print(A1.issubset(A2))
print(A2.issubset(A1))
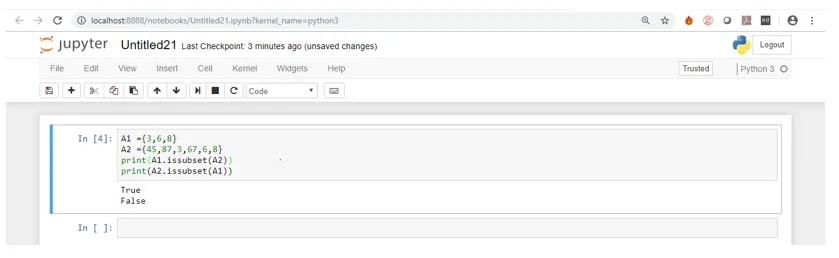
Wenn Sie den obigen Screenshot sehen, können Sie sehen, dass A2 alle Elemente von A1 enthält, A1 jedoch nicht alle Elemente von A2. Daher ist A1 eine Teilmenge von A2.
8. issuperset (): Diese Funktion gibt boolesche Werte zurück, die wahr oder falsch sind. Wenn eine Menge alle Elemente einer anderen Menge enthält, kann diese Menge als Obermenge der anderen Menge bezeichnet werden, und der von der Funktion zurückgegebene Wert ist true, andernfalls false. Wir werden ein Beispiel davon sehen, um es besser zu verstehen.
Code:
A1 = (3, 6, 8)
A2 = (45, 87, 3, 67, 6, 8)
print(A1.issuperset(A2))
print(A2.issuperset(A1))
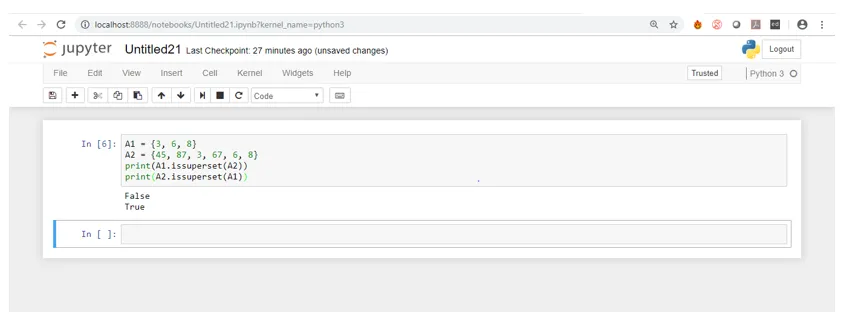
Wie Sie dem Screenshot entnehmen können, enthält die zweite Menge A2 alle Elemente der Menge A1. Daher ist es eine Obermenge von A1. Dasselbe gilt nicht für A1 in Bezug auf A2, daher wird false zurückgegeben.
9. remove (): Mit dieser Funktion werden Elemente aus der Menge entfernt. Die zu entfernenden Elemente werden als Argumente übergeben. Die Funktion entfernt das Element, wenn es in der Menge vorhanden ist, andernfalls wird ein Fehler zurückgegeben. Wir werden ein Beispiel ausführen, um dies zu überprüfen.
Code:
firstset = ("Johnny", "Nilanjan", "Rupa")
firstset.remove("Nilanjan")
print(firstset)
# to check error
firstset.remove("Rocky")
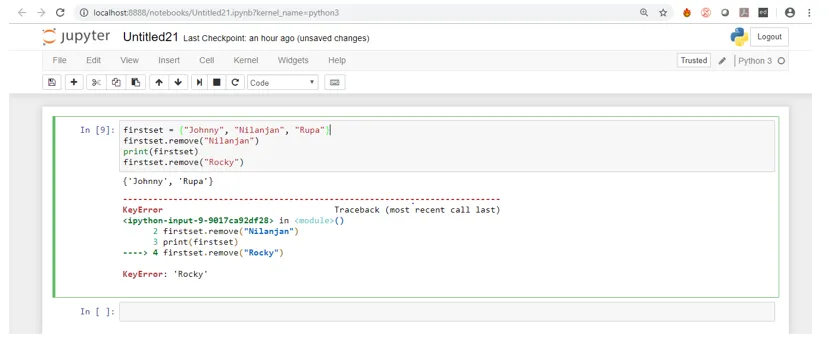
Wenn Sie den Screenshot oben sehen, während der Code ausgeführt wird, wird das Element "Nilanjan" entfernt, wie es im Set vorhanden war, aber wenn wir versuchen, "Rocky" zu entfernen, wird ein Fehler ausgegeben, da "Rocky" im Set nicht vorhanden ist.
10. discard (): Diese eingebaute Methode wird auch zum Entfernen von Elementen aus der Menge verwendet, unterscheidet sich jedoch von der zuvor diskutierten Methode remove. Wenn das Element in der Menge vorhanden ist, wird das Element entfernt, aber wenn es vorhanden ist, wird kein Fehler zurückgegeben und normalerweise nur die Menge gedruckt. Wir werden ein Beispiel dafür sehen
Code:
firstset = ("Johnny", "Nilanjan", "Rupa")
firstset.discard("Nilanjan")
print(firstset)
firstset.discard("Rocky")
print(firstset)
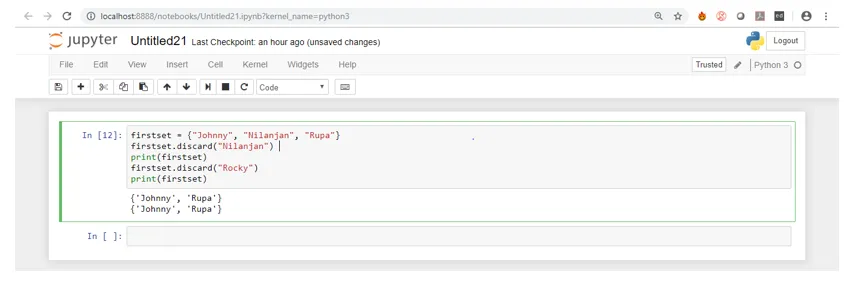
Wenn wir den obigen Screenshot sehen, können wir sehen, dass, obwohl "Rocky" im Set nicht vorhanden ist, kein Fehler angezeigt wird, anders als im Fall der Entfernungsmethode, bei der ein Fehler angezeigt wurde.
Fazit
Wir haben in diesem Artikel das Konzept von Mengen in Python und die verschiedenen Funktionen, die in Mengen verwendet oder angewendet werden können, erörtert. Wie bereits erwähnt, sind Mengen in Python wichtig. Die integrierten Methoden werden verwendet, um die Mengen zu bearbeiten und Operationen mit Mengen auszuführen.
Empfohlene Artikel
Dies ist eine Anleitung zu den Python-Sets. Hier diskutieren wir die Einführung der Python-Sets, verschiedene Methoden in Python-Sets sowie die Syntax. Sie können auch unsere anderen Artikelvorschläge durchgehen, um mehr zu erfahren.
- String Array in Python
- Was ist Python?
- NLP in Python
- Ist Python eine Skriptsprache?
- Python-Funktionen
- String Array in JavaScript
- Vollständige Anleitung zum Strings Array in C