
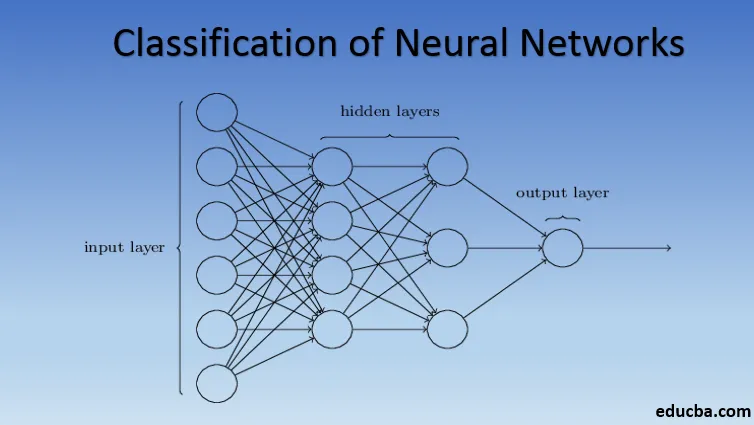
Einführung in die Klassifikation des neuronalen Netzes
Neuronale Netze sind der effizienteste Weg (ja, Sie lesen es richtig), um reale Probleme in der künstlichen Intelligenz zu lösen. Derzeit ist es auch eines der am intensivsten untersuchten Gebiete in der Informatik, dass eine neue Form des Neuronalen Netzes entwickelt worden wäre, während Sie diesen Artikel lesen. Es gibt Hunderte von neuronalen Netzen, um Probleme zu lösen, die für verschiedene Domänen spezifisch sind. Hier werden wir Sie durch verschiedene Arten grundlegender neuronaler Netze in der Reihenfolge zunehmender Komplexität führen.
Verschiedene Arten von Grundlagen zur Klassifikation neuronaler Netze
1. Flache neuronale Netze (Kollaboratives Filtern)
Neuronale Netze bestehen aus Gruppen von Perceptron, um die neuronale Struktur des menschlichen Gehirns zu simulieren. Flache neuronale Netze haben eine einzige verborgene Schicht des Perzeptrons. Eines der häufigsten Beispiele für flache neuronale Netze ist Collaborative Filtering. Die verborgene Schicht des Perzeptrons würde trainiert, um die Ähnlichkeiten zwischen Entitäten darzustellen, um Empfehlungen zu generieren. Das Empfehlungssystem in Netflix, Amazon, YouTube usw. verwendet eine Version der kollaborativen Filterung, um ihre Produkte entsprechend dem Benutzerinteresse zu empfehlen.
2. Multilayer Perceptron (Deep Neural Networks)
Neuronale Netze mit mehr als einer verborgenen Schicht werden als tiefe neuronale Netze bezeichnet. Spoiler Alarm! Alle folgenden neuronalen Netze sind eine Form von tiefen neuronalen Netzen, die optimiert / verbessert wurden, um domänenspezifische Probleme zu lösen. Im Allgemeinen helfen sie uns, Universalität zu erreichen. Bei einer ausreichenden Anzahl von verborgenen Schichten des Neurons kann ein tiefes neuronales Netzwerk jedes komplexe Problem der realen Welt approximieren, dh lösen.
Der universelle Approximationssatz ist der Kern von tiefen neuronalen Netzen, um jedes Modell zu trainieren und anzupassen. Jede Version des tiefen neuronalen Netzwerks wird durch eine vollständig verbundene Schicht aus maximal gepooltem Produkt der Matrixmultiplikation entwickelt, die durch Backpropagation-Algorithmen optimiert wird. Wir werden weiterhin die Verbesserungen lernen, die zu verschiedenen Formen tiefer neuronaler Netze führen.
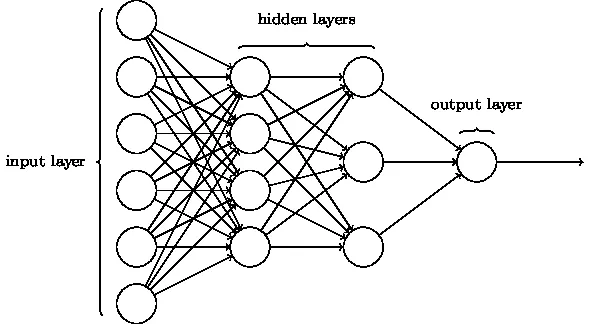
3. Faltungsneurales Netzwerk (CNN)
CNNs sind die ausgereifteste Form von tiefen neuronalen Netzen, um die genauesten, dh besser als menschliche Ergebnisse in der Computersicht zu erzielen. CNNs bestehen aus Schichten von Faltungen, die durch Scannen jedes einzelnen Bildpixels in einem Datensatz erstellt werden. Wenn die Daten Schicht für Schicht angenähert werden, erkennen CNNs die Muster und dadurch die Objekte in den Bildern. Diese Objekte werden häufig in verschiedenen Anwendungen zur Identifizierung, Klassifizierung usw. verwendet. Jüngste Praktiken wie das Transferlernen in CNNs haben zu erheblichen Verbesserungen der Ungenauigkeit der Modelle geführt. Google Translator und Google Lens sind die bekanntesten Beispiele für CNNs.
Die Anwendung von CNNs ist exponentiell, da sie sogar zur Lösung von Problemen eingesetzt werden, die in erster Linie nicht mit der Bildverarbeitung zusammenhängen. Eine sehr einfache, aber intuitive Erklärung der CNNs finden Sie hier.
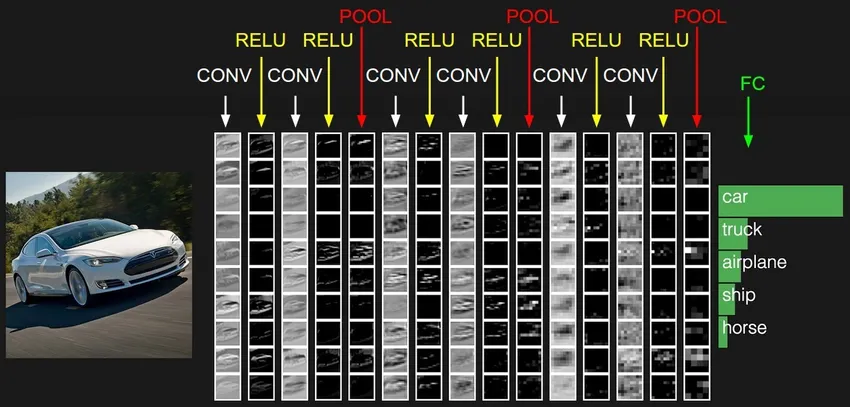
4. Recurrent Neural Network (RNN)
RNNs sind die neueste Form von tiefen neuronalen Netzen zur Lösung von Problemen in NLP. Einfach ausgedrückt, geben RNNs die Ausgabe einiger ausgeblendeter Ebenen an die Eingabeebene zurück, um die Annäherung an die nächste Iteration (Epoche) des Eingabedatensatzes zu aggregieren und fortzusetzen. Es hilft dem Modell auch, sich selbst zu erlernen, und korrigiert die Vorhersagen in gewissem Maße schneller. Solche Modelle sind sehr hilfreich, um die Semantik des Texts in NLP-Operationen zu verstehen. Es gibt verschiedene Varianten von RNNs wie Langzeitspeicher (LSTM), Gated Recurrent Unit (GRU) usw. In der folgenden Abbildung wird die Aktivierung von h1 und h2 mit dem Eingang x2 bzw. x3 gespeist.
5. Langzeit-Kurzzeitgedächtnis (LSTM)
LSTMs wurden speziell entwickelt, um das Problem des Verschwindens von Gradienten mit dem RNN anzugehen. Verschwindende Gradienten treten bei großen neuronalen Netzen auf, bei denen die Gradienten der Verlustfunktionen dazu neigen, sich Null anzunähern, wodurch pausierende neuronale Netze zum Lernen veranlasst werden. LSTM löst dieses Problem, indem Aktivierungsfunktionen in seinen wiederkehrenden Komponenten verhindert werden und die gespeicherten Werte nicht geändert werden. Diese kleine Änderung führte zu großen Verbesserungen im endgültigen Modell, was dazu führte, dass die Technologiegiganten LSTM in ihren Lösungen adaptierten. Über die "einfachste selbsterklärende" Darstellung von LSTM,
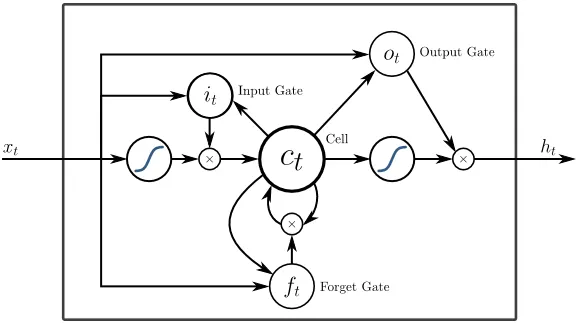
6. Aufmerksamkeitsbasierte Netzwerke
Aufmerksamkeitsmodelle übernehmen langsam auch die neuen RNNs in der Praxis. Die Aufmerksamkeitsmodelle basieren auf der Konzentration auf einen Teil der Informationen, die sie enthalten, und eliminieren so die überwältigende Menge an Hintergrundinformationen, die für die jeweilige Aufgabe nicht benötigt werden. Aufmerksamkeitsmodelle werden mit einer Kombination aus weicher und harter Aufmerksamkeit und Anpassung durch rückwirkende weiche Aufmerksamkeit gebaut. Mehrere Aufmerksamkeitsmodelle, die hierarchisch gestapelt sind, werden als Transformer bezeichnet. Diese Transformatoren sind effizienter, um die Stapel parallel zu betreiben, sodass sie mit vergleichsweise geringeren Daten und weniger Zeit für das Training des Modells Ergebnisse auf dem neuesten Stand der Technik liefern. Eine Aufmerksamkeitsverteilung wird bei Verwendung mit CNN / RNN sehr leistungsfähig und kann wie folgt eine Textbeschreibung für ein Bild erzeugen.

Tech-Giganten wie Google, Facebook usw. passen ihre Aufmerksamkeitsmodelle schnell an, um ihre Lösungen zu entwickeln.
7. Generative Adversarial Network (GAN)
Obwohl Deep-Learning-Modelle hochmoderne Ergebnisse liefern, können sie von weitaus intelligenteren menschlichen Kollegen getäuscht werden, indem den realen Daten Rauschen hinzugefügt wird. GANs sind die neueste Entwicklung im Bereich Deep Learning, um solche Szenarien anzugehen. GANs verwenden unbeaufsichtigtes Lernen, wenn tiefe neuronale Netze mit den von einem AI-Modell generierten Daten zusammen mit dem tatsächlichen Datensatz trainiert werden, um die Genauigkeit und Effizienz des Modells zu verbessern. Diese gegnerischen Daten werden meistens verwendet, um das Unterscheidungsmodell zu täuschen und ein optimales Modell zu erstellen. Das resultierende Modell ist tendenziell eine bessere Annäherung, als ein solches Rauschen überwinden kann. Das Forschungsinteresse an GANs hat zu komplexeren Implementierungen geführt, wie z. B. Conditional GAN (CGAN), Laplace-Pyramide GAN (LAPGAN), Super Resolution GAN (SRGAN) usw.
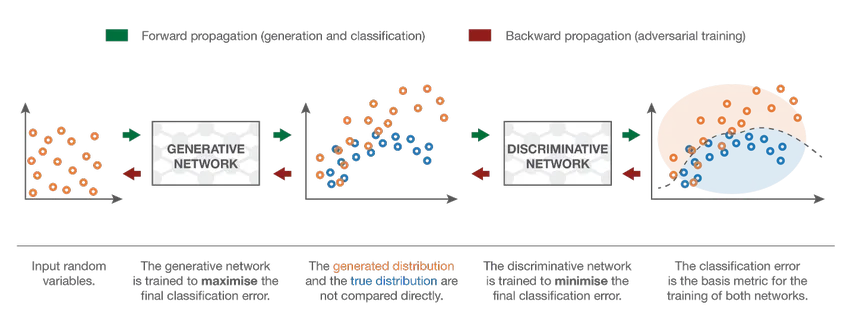
Schlussfolgerung - Klassifikation des neuronalen Netzes
Die tiefen neuronalen Netze haben die Grenzen der Computer überschritten. Sie beschränken sich nicht nur auf Klassifizierung (CNN, RNN) oder Vorhersagen (Collaborative Filtering), sondern auch auf die Generierung von Daten (GAN). Diese Daten können von der schönen Form der Kunst bis zu kontroversen Deep Fakes variieren, aber sie übertreffen die Menschen jeden Tag um eine Aufgabe. Daher sollten wir auch die KI-Ethik und die Auswirkungen berücksichtigen, während wir hart daran arbeiten, ein effizientes neuronales Netzwerkmodell aufzubauen. Zeit für eine übersichtliche Infografik über die neuronalen Netze.
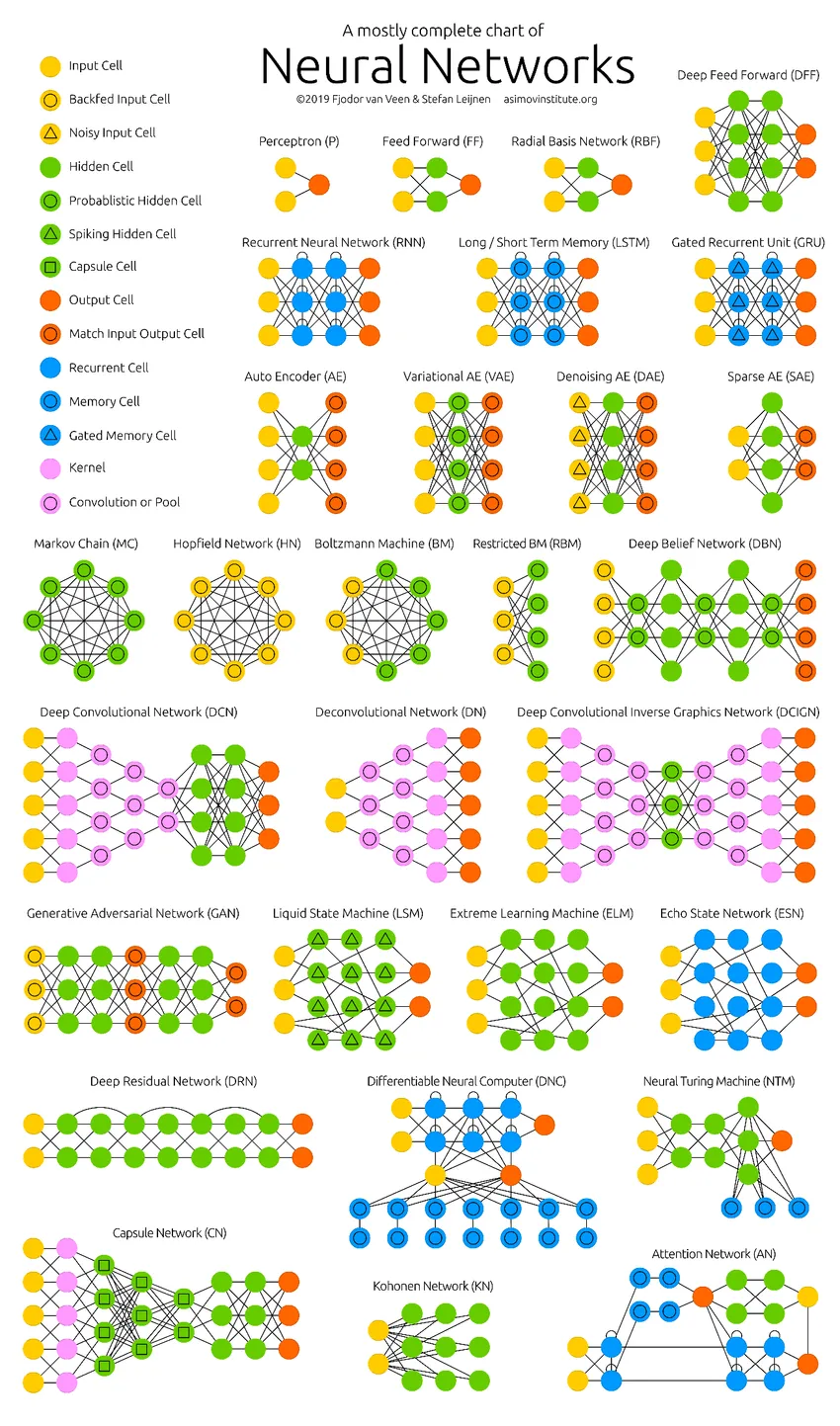
Empfohlene Artikel
Dies ist ein Leitfaden zur Klassifikation des neuronalen Netzes. Hier haben wir die verschiedenen Arten von Neuronalen Grundnetzen besprochen. Sie können auch in unseren Artikeln nachlesen, um mehr zu erfahren.
- Was sind neuronale Netze?
- Neuronale Netzwerkalgorithmen
- Netzwerk-Scan-Tools
- Wiederkehrende Neuronale Netze (RNN)
- Top 6 Vergleiche zwischen CNN und RNN