
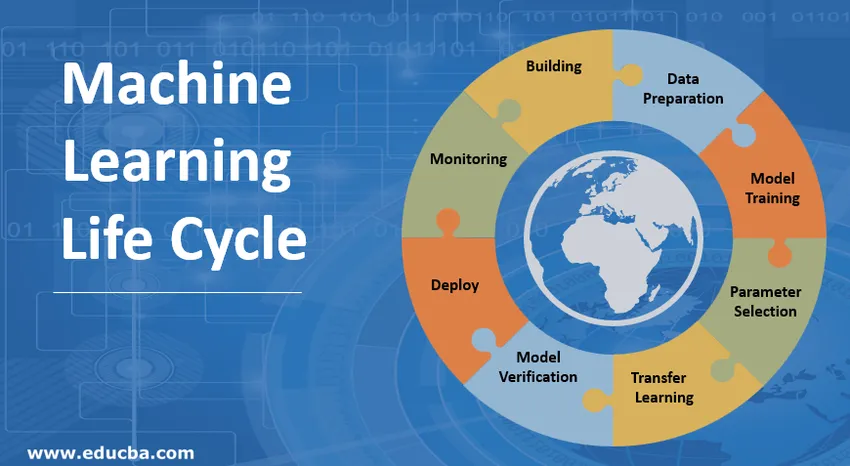
Einführung in den Lebenszyklus des maschinellen Lernens (ML)
Im Lebenszyklus des maschinellen Lernens geht es darum, Wissen durch Daten zu erwerben. Der Lebenszyklus des maschinellen Lernens beschreibt einen dreiphasigen Prozess, mit dem Datenwissenschaftler und Dateningenieure Modelle entwickeln, trainieren und bereitstellen. Die Entwicklung, Schulung und Wartung von Modellen für maschinelles Lernen ist das Ergebnis eines Prozesses, der als Lebenszyklus des maschinellen Lernens bezeichnet wird. Es ist ein System, das Daten als Eingabe verwendet und die Fähigkeit besitzt, mithilfe von Algorithmen zu lernen und zu verbessern, ohne dafür programmiert zu sein. Der Lebenszyklus des maschinellen Lernens besteht aus drei Phasen, wie in der folgenden Abbildung dargestellt: Pipeline-Entwicklung, Training und Inferenz.
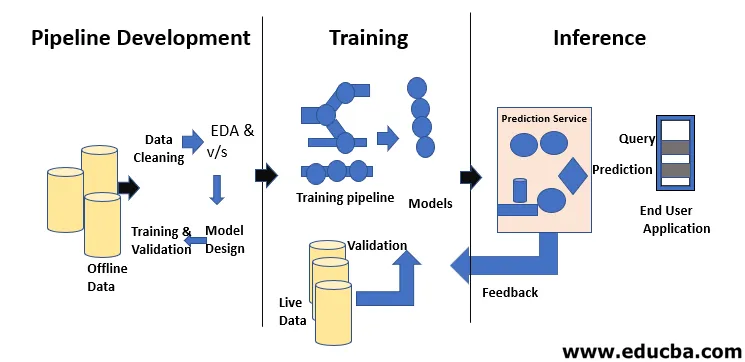
Der erste Schritt im Lebenszyklus des maschinellen Lernens besteht darin, Rohdaten in ein bereinigtes Dataset umzuwandeln, das häufig gemeinsam genutzt und wiederverwendet wird. Wenn ein Analyst oder ein Datenwissenschaftler auf Probleme mit den empfangenen Daten stößt, muss er auf die Originaldaten und Transformationsskripte zugreifen. Es gibt eine Reihe von Gründen, aus denen wir möglicherweise auf frühere Versionen unserer Modelle und Daten zurückgreifen möchten. Um beispielsweise die frühere beste Version zu finden, müssen möglicherweise viele alternative Versionen durchsucht werden, da sich die Vorhersagekraft von Modellen unvermeidlich verschlechtert. Es gibt viele Gründe für diese Verschlechterung, z. B. eine Verschiebung der Datenverteilung, die zu einem raschen Rückgang der Vorhersagekraft führen kann, um Fehler zu kompensieren. Die Diagnose dieses Rückgangs erfordert möglicherweise den Vergleich von Trainingsdaten mit Live-Daten, die Umschulung des Modells, die Überprüfung früherer Entwurfsentscheidungen oder sogar die Neugestaltung des Modells.
Aus Fehlern lernen
Die Entwicklung von Modellen erfordert separate Trainings- und Testdatensätze. Eine übermäßige Verwendung von Testdaten während des Trainings kann zu einer schlechten Verallgemeinerung und Leistung führen, da dies zu einer Überanpassung führen kann. Der Kontext spielt hier eine entscheidende Rolle, daher ist zu verstehen, welche Daten zum Trainieren der beabsichtigten Modelle und mit welchen Konfigurationen verwendet wurden. Der Lebenszyklus des maschinellen Lernens ist datengesteuert, da das Modell und die Ausgabe des Trainings mit den Daten verknüpft sind, auf denen es trainiert wurde. Eine Übersicht über eine End-to-End-Pipeline für maschinelles Lernen mit einer Datenansicht ist in der folgenden Abbildung dargestellt:
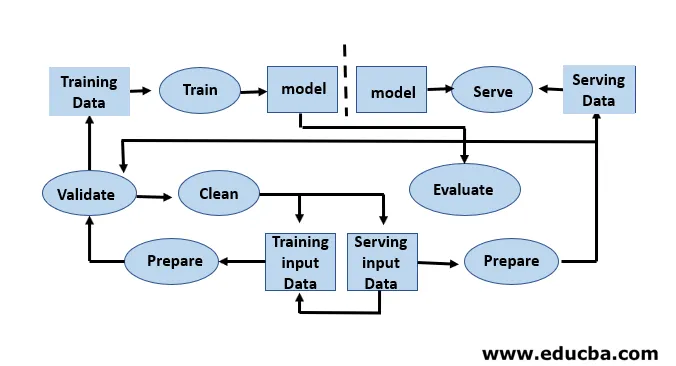
Schritte im Lebenszyklus des maschinellen Lernens
Der Entwickler für maschinelles Lernen experimentiert ständig mit neuen Datensätzen, Modellen, Softwarebibliotheken und Optimierungsparametern, um die Modellgenauigkeit zu optimieren und zu verbessern. Da die Modellleistung vollständig von den Eingabedaten und dem Trainingsprozess abhängt.
1. Das maschinelle Lernmodell erstellen
In diesem Schritt wird der Typ des Modells basierend auf der Anwendung festgelegt. Es wird auch festgestellt, dass die Anwendung des Modells in der Modelllernphase, so dass sie entsprechend dem Bedarf einer beabsichtigten Anwendung richtig ausgelegt werden kann. Es stehen verschiedene Modelle für maschinelles Lernen zur Verfügung, z. B. das überwachte Modell, das nicht überwachte Modell, die Klassifizierungsmodelle, die Regressionsmodelle, die Clustering-Modelle und die Modelle für das verstärkte Lernen. Ein genauer Einblick ist in der folgenden Abbildung dargestellt:
2. Datenaufbereitung
Eine Vielzahl von Daten kann als Eingabe für maschinelles Lernen verwendet werden. Diese Daten können aus einer Reihe von Quellen stammen, z. B. aus Unternehmen, Pharmaunternehmen, IoT-Geräten, Unternehmen, Banken, Krankenhäusern usw. In der Lernphase der Maschine werden große Datenmengen bereitgestellt, da sie sich mit zunehmender Datenanzahl aneinander ausrichten gewünschte Ergebnisse zu erzielen. Diese Ausgangsdaten können zur Analyse verwendet oder als Eingabe in andere maschinelle Lernanwendungen oder -systeme eingespeist werden, für die sie als Ausgangsdaten fungieren.
3. Model Training
Diese Phase befasst sich mit der Erstellung eines Modells aus den ihm gegebenen Daten. In diesem Stadium wird ein Teil der Trainingsdaten verwendet, um Modellparameter wie die Koeffizienten eines Polynoms oder die Gewichte beim maschinellen Lernen zu finden, was hilft, den Fehler für den gegebenen Datensatz zu minimieren. Die verbleibenden Daten werden dann zum Testen des Modells verwendet. Diese beiden Schritte werden im Allgemeinen mehrmals wiederholt, um die Leistung des Modells zu verbessern.
4. Parameterauswahl
Dabei werden die mit dem Training verbundenen Parameter ausgewählt, die auch als Hyperparameter bezeichnet werden. Diese Parameter steuern die Effektivität des Trainingsprozesses und somit hängt letztendlich die Leistung des Modells davon ab. Sie sind sehr wichtig für die erfolgreiche Erstellung des maschinellen Lernmodells.
5. Übertragen Sie das Lernen
Da die Wiederverwendung von Modellen für maschinelles Lernen in verschiedenen Bereichen viele Vorteile mit sich bringt. Trotz der Tatsache, dass ein Modell nicht direkt zwischen verschiedenen Domänen übertragen werden kann, wird es daher verwendet, um ein Ausgangsmaterial für den Beginn des Trainings eines Next-Stage-Modells bereitzustellen. Dadurch verkürzt sich die Einarbeitungszeit erheblich.
6. Modellüberprüfung
Die Eingabe dieser Stufe ist das trainierte Modell, das durch die Modelllernstufe erzeugt wird, und die Ausgabe ist ein verifiziertes Modell, das ausreichende Informationen liefert, damit Benutzer bestimmen können, ob das Modell für die beabsichtigte Anwendung geeignet ist. Diese Phase des Lebenszyklus des maschinellen Lernens befasst sich daher mit der Tatsache, dass ein Modell ordnungsgemäß funktioniert, wenn es mit nicht sichtbaren Eingaben behandelt wird.
7. Stellen Sie das maschinelle Lernmodell bereit
In dieser Phase des Lebenszyklus des maschinellen Lernens wenden wir uns an, um maschinelle Lernmodelle in Prozesse und Anwendungen zu integrieren. Das endgültige Ziel dieser Phase ist die ordnungsgemäße Funktionalität des Modells nach der Bereitstellung. Die Modelle sollten so bereitgestellt werden, dass sie für Rückschlüsse verwendet werden können, und sie sollten regelmäßig aktualisiert werden.
8. Überwachung
Es beinhaltet die Aufnahme von Sicherheitsmaßnahmen zur Gewährleistung des ordnungsgemäßen Betriebs des Modells während seiner Lebensdauer. Dazu ist eine ordnungsgemäße Verwaltung und Aktualisierung erforderlich.
Vorteil des Lebenszyklus des maschinellen Lernens
Maschinelles Lernen bietet die Vorteile von Leistung, Geschwindigkeit, Effizienz und Intelligenz durch Lernen, ohne diese explizit in eine Anwendung zu programmieren. Es bietet Möglichkeiten für eine verbesserte Leistung, Produktivität und Robustheit.
Fazit - Lebenszyklus des maschinellen Lernens
Maschinelles Lernen wird von Tag zu Tag wichtiger, da die Datenmenge in verschiedenen Anwendungen rapide zunimmt. Die Technologie des maschinellen Lernens ist das Herzstück von intelligenten Geräten, Haushaltsgeräten und Onlinediensten. Der Erfolg des maschinellen Lernens kann auf sicherheitskritische Systeme, Datenmanagement und Hochleistungsrechnen ausgedehnt werden, die ein großes Potenzial für Anwendungsbereiche bieten.
Empfohlene Artikel
Dies ist eine Anleitung zum Lebenszyklus des maschinellen Lernens. Hier diskutieren wir die Einführung, Lernen aus Fehlern, Schritte im maschinellen Lernzyklus und Vorteile. Sie können auch unsere anderen Artikelvorschläge durchgehen, um mehr zu erfahren.
- Künstliche Intelligenz Unternehmen
- QlikView-Set-Analyse
- IoT-Ökosystem
- Cassandra Datenmodellierung