

Einführung in die ANOVA in R
Der folgende Artikel ANOVA in R bietet eine Übersicht zum Vergleichen des Mittelwerts verschiedener Gruppen. Eine Varianzanalyse (ANOVA) ist eine sehr verbreitete Technik, um den Mittelwert verschiedener Gruppen zu vergleichen. Das ANOVA-Modell wird zum Testen von Hypothesen verwendet, wobei bestimmte Annahmen oder Parameter für eine Population generiert werden und die statistische Methode verwendet wird, um zu bestimmen, ob die Hypothese wahr oder falsch ist.
Die Hypothese leitet sich aus der Annahme des Prüfers und den verfügbaren Informationen über die Population ab. ANOVA heißt Varianzanalyse und wird für Hypothesentests verwendet, bei denen Mittelwerte einer Variablen in mehreren unabhängigen Gruppen gemessen werden müssen.
Zum Beispiel vergleichen Forscher in einem Labor, in dem sie ein neues Medikament gegen Fettleibigkeit untersuchen oder erfinden, die Ergebnisse einer experimentellen und einer Standardbehandlung. In einer Adipositas-Studie können wertvolle Ergebnisse abgeleitet werden, wenn die mittlere Adipositas-Rate der Bevölkerung in verschiedenen Altersgruppen verglichen werden kann. In diesem Fall möchte man die mittlere Adipositasrate zwischen verschiedenen Altersgruppen wie Alter (5 bis 18), (19, 35) und (36 bis 50) beobachten. Die ANOVA-Methode wird angewendet, da mehr als zwei Gruppen unabhängig sind. Die ANOVA-Methode wird verwendet, um die mittlere Fettleibigkeit der unabhängigen Gruppen zu vergleichen. Die Funktion aov () wird verwendet, und die Syntax lautet aov (Formel, data = dataframe). In diesem Artikel lernen wir das ANOVA-Modell kennen und erläutern anhand von Beispielen das Einweg- und das Zweiweg-ANOVA-Modell.
Warum ANOVA?
- Diese Technik wird verwendet, um die Hypothese zu beantworten, während mehrere Datengruppen analysiert werden. Es gibt mehrere statistische Ansätze. Die ANOVA in R wird jedoch angewendet, wenn mehr als zwei unabhängige Gruppen verglichen werden müssen, wie in unserem vorherigen Beispiel drei verschiedene Altersgruppen.
- Die ANOVA-Technik misst den Mittelwert der unabhängigen Gruppen, um den Forschern das Ergebnis der Hypothese zu liefern. Um genaue Ergebnisse zu erhalten, müssen Stichprobenmittel, Stichprobengröße und Standardabweichung von jeder einzelnen Gruppe berücksichtigt werden.
- Es ist möglich, den Mittelwert für jede der drei Gruppen einzeln zum Vergleich zu betrachten. Dieser Ansatz weist jedoch Einschränkungen auf und kann sich als falsch erweisen, da diese drei Vergleiche keine Gesamtdaten berücksichtigen und daher zu einem Fehler vom Typ 1 führen können. R bietet uns die Funktion, die ANOVA-Analyse durchzuführen, um die Variabilität zwischen den unabhängigen Datengruppen zu untersuchen. Die ANOVA-Analyse besteht aus fünf Phasen. In der ersten Phase werden die Daten im CSV-Format angeordnet und die Spalte für jede Variable generiert. Eine der Spalten wäre eine abhängige Variable und die verbleibende ist die unabhängige Variable. In der zweiten Stufe werden die Daten in R Studio gelesen und entsprechend benannt. In der dritten Stufe wird ein Datensatz an einzelne Variablen angehängt und vom Speicher gelesen. Schließlich wird die ANOVA in R definiert und analysiert. In den folgenden Abschnitten habe ich einige Beispiele für Fallstudien aufgeführt, in denen ANOVA-Techniken verwendet werden sollten.
- Sechs Insektizide wurden auf jeweils 12 Feldern getestet, und die Forscher zählten die Anzahl der in jedem Feld verbliebenen Insekten. Jetzt müssen die Landwirte wissen, ob die Insektizide einen Unterschied machen und wenn ja, welches sie am besten verwenden. Sie beantworten diese Frage mit der Funktion aov (), um eine ANOVA durchzuführen.
- 50 Patienten erhielten eine von fünf cholesterinsenkenden Medikamentenbehandlungen (trt). Drei der Behandlungsbedingungen betrafen dasselbe Arzneimittel, das einmal täglich 20 mg (1 Mal) und zweimal täglich 10 mg (2 Mal) und viermal täglich 5 mg (4 Mal) verabreicht wurde. Die beiden verbleibenden Zustände (drugD und drugE) stellten konkurrierende Medikamente dar. Welche medikamentöse Behandlung führte zu der größten Cholesterinsenkung (Response)?
ANOVA Einweg
- Die Einwegmethode ist eine der ANOVA-Basistechniken, bei der die Varianzanalyse angewendet und der Mittelwert mehrerer Bevölkerungsgruppen verglichen wird.
- Einweg-ANOVA erhielt seinen Namen aufgrund der Verfügbarkeit von Einweg-Verschlusssachen. In einer Einweg-ANOVA können eine einzige abhängige Variable und eine oder mehrere unabhängige Variablen verfügbar sein.
- Zum Beispiel werden wir die ANOVA-Technik an einem Cholesterin-Datensatz durchführen. Der Datensatz besteht aus zwei Variablen trt (Behandlungen auf 5 verschiedenen Ebenen) und Antwortvariablen. Unabhängige Variable - Gruppen der medikamentösen Behandlung, abhängige Variable - Mittelwert von 2 oder mehr Gruppen ANOVA. Anhand dieser Ergebnisse können Sie bestätigen, dass die Einnahme von 5 mg 4-mal täglich besser war als die Einnahme von 20 mg einmal täglich. Medikament D hat im Vergleich zu Medikament E bessere Wirkungen
Medikament D liefert bessere Ergebnisse, wenn es in Dosen von 20 mg im Vergleich zu Medikament E eingenommen wird
Verwendet den Cholesterin-Datensatz im Multicomp-Paketinstall.packages('multcomp')
library(multcomp)
str(cholesterol)
attach(cholesterol)
aov_model <- aov(response ~ trt)
Der ANOVA F-Test für die Behandlung (trt) ist signifikant (p <0, 0001), was den Nachweis erbringt, dass die fünf Behandlungen durchgeführt wurden
# sind nicht alle gleich effektiv.
Zusammenfassung (aov_model)
sich ablösen (Cholesterin)

Die Funktion plotmeans () im Paket gplots kann verwendet werden, um ein Diagramm der Gruppenmittelwerte und ihrer Konfidenzintervalle zu erstellen. Dies zeigt deutlich die Behandlungsunterschiedeinstall.packages('gplots')
library(gplots)
plotmeans(response ~ trt, xlab="Treatment", ylab="Response",
main="Mean Plot\nwith 95% CI")
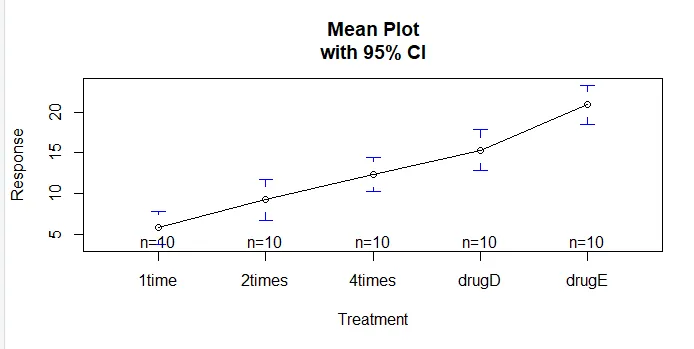
Untersuchen wir die Ausgabe von TukeyHSD () auf paarweise Unterschiede zwischen Gruppenmitteln
TukeyHSD (aov_model)
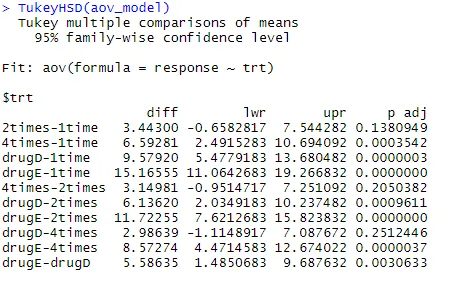
Die mittleren Cholesterinsenkungen für 1-fach und 2-fach unterscheiden sich nicht signifikant voneinander (p = 0, 138), wohingegen der Unterschied zwischen 1-fach und 4-fach signifikant unterschiedlich ist (p <0, 001).
par (mar = c (5, 8, 4, 2)) # Linken Rand vergrößern (TukeyHSD (aov_model), las = 2)
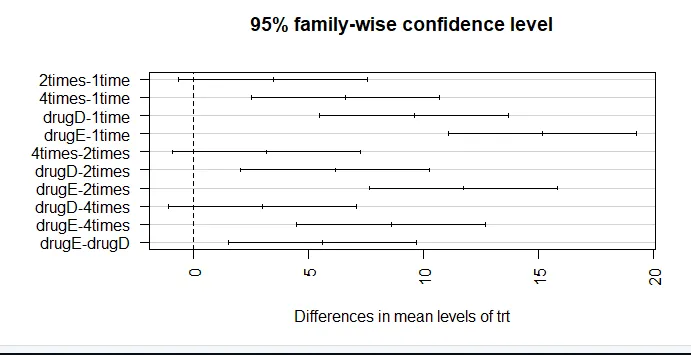
Das Vertrauen in die Ergebnisse hängt davon ab, inwieweit Ihre Daten die den statistischen Tests zugrunde liegenden Annahmen erfüllen. In einer Einweg-ANOVA wird angenommen, dass die abhängige Variable normal verteilt ist und in jeder Gruppe die gleiche Varianz aufweist. Sie können ein QQ-Diagramm verwenden, um die Bibliothek der Normalitätsannahmen (Auto) zu bewerten.
QQ-Plot (lm (Antwort ~ trt, Daten = Cholesterin), simulieren = TRUE, main = "QQ-Plot", Labels = FALSE)
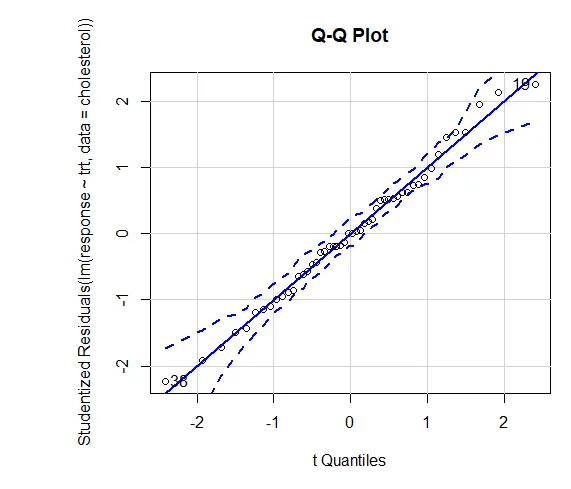
Gepunktete Linie = 95% Vertrauensbereich, was darauf hindeutet, dass die Normalitätsannahme ziemlich gut erfüllt wurde. ANOVA geht davon aus, dass die Varianzen zwischen Gruppen oder Stichproben gleich sind. Mit dem Bartlett-Test kann diese Annahme überprüft werden
bartlett.test (Antwort ~ trt, Daten = Cholesterin). Der Bartlett-Test zeigt, dass sich die Varianzen in den fünf Gruppen nicht signifikant unterscheiden (p = 0, 97).
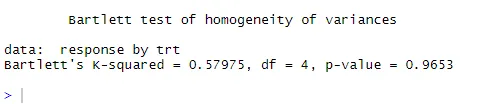
ANOVA reagiert auch empfindlich auf Ausreißertests auf Ausreißer, indem die Funktion outlierTest () im Fahrzeugpaket verwendet wird. Möglicherweise müssen Sie dieses Paket nicht ausführen, um Ihre Fahrzeugbibliothek zu aktualisieren.update.packages(checkBuilt = TRUE)
install.packages("car", dependencies = TRUE)
library(car)
outlierTest(aov_model)
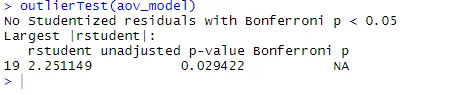
An der Ausgabe können Sie erkennen, dass die Cholesterinwerte keine Hinweise auf Ausreißer enthalten (NA tritt auf, wenn p> 1 ist). Wenn man das QQ-Diagramm, den Bartlett-Test und den Ausreißertest zusammen betrachtet, scheinen die Daten recht gut zum ANOVA-Modell zu passen.
Zweiwege-Anova
Eine weitere Variable wird im Zweiwege-ANOVA-Test hinzugefügt. Wenn es zwei unabhängige Variablen gibt, müssen wir eine Zwei-Wege-ANOVA anstelle einer Ein-Wege-ANOVA-Technik verwenden, die im vorherigen Fall verwendet wurde, in dem wir eine kontinuierliche abhängige Variable und mehr als eine unabhängige Variable hatten. Um die bidirektionale ANOVA zu verifizieren, müssen mehrere Annahmen erfüllt sein.
- Verfügbarkeit unabhängiger Beobachtungen
- Die Beobachtungen sollten normal verteilt sein
- Die Varianz sollte bei den Beobachtungen gleich sein
- Ausreißer sollten nicht vorhanden sein
- Unabhängige Fehler
Um die bidirektionale ANOVA zu überprüfen, wird dem Datensatz eine weitere Variable mit dem Namen BP hinzugefügt. Die Variable gibt die Blutdruckrate bei Patienten an. Wir möchten überprüfen, ob zwischen dem Blutdruck und der den Patienten verabreichten Dosis ein statistischer Unterschied besteht.
df <- read.csv ("file.csv")
df
anova_two_way <- aov (Antwort ~ trt + BP, Daten = df)
Zusammenfassung (anova_two_way)
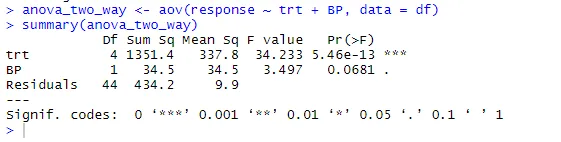
Aus der Ausgabe kann geschlossen werden, dass sowohl trt als auch BP statistisch von 0 verschieden sind. Daher kann die Nullhypothese verworfen werden.
Vorteile von ANOVA in R
Der ANOVA-Test bestimmt den Mittelwertunterschied zwischen zwei oder mehr unabhängigen Gruppen. Diese Technik ist sehr nützlich für die Analyse mehrerer Artikel, die für die Marktanalyse unerlässlich ist. Mit dem ANOVA-Test kann man notwendige Erkenntnisse aus den Daten gewinnen. Beispielsweise während einer Produktumfrage, bei der mehrere Informationen wie Einkaufslisten, Kundenwünsche und Abneigungen von den Benutzern erfasst werden. Der ANOVA-Test hilft uns, Bevölkerungsgruppen zu vergleichen. Die Gruppe könnte entweder männlich gegen weiblich oder verschiedene Altersgruppen sein. Die ANOVA-Technik hilft bei der Unterscheidung der Mittelwerte verschiedener Bevölkerungsgruppen, die tatsächlich unterschiedlich sind.
Fazit - ANOVA in R
ANOVA ist eine der am häufigsten verwendeten Methoden zum Testen von Hypothesen. In diesem Artikel haben wir einen ANOVA-Test für den Datensatz durchgeführt, der aus fünfzig Patienten besteht, die eine cholesterinsenkende medikamentöse Behandlung erhalten haben, und wir haben weiter untersucht, wie eine Zwei-Wege-ANOVA durchgeführt werden kann, wenn eine zusätzliche unabhängige Variable verfügbar ist.
Empfohlene Artikel
Dies ist eine Anleitung zu ANOVA in R. Hier werden das Einweg- und das Zweiweg-Anova-Modell sowie Beispiele und Vorteile von ANOVA erläutert. Sie können auch unsere anderen Artikelvorschläge durchgehen -
- Regression gegen ANOVA
- Was ist SPSS?
- Interpretation der Ergebnisse mit dem ANOVA-Test
- Funktionen in R