
Einführung in Data Lake vs Data Warehouse
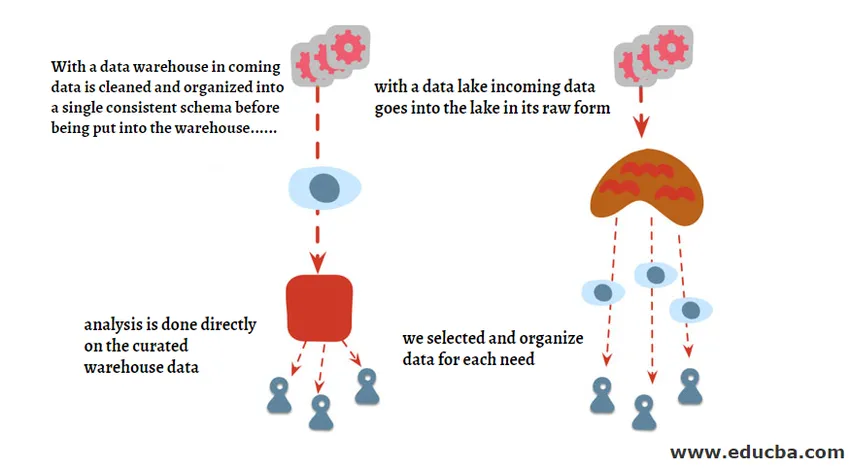
Data Lake vs Data Warehouse sind die Begriffe, die synonym verwendet werden, aber es gibt Unterschiede zwischen diesen beiden Begriffen. Wir haben das folgende Diagramm dargestellt, um den großen Unterschied zwischen diesen beiden zu verstehen. In Kürze werden wir für jedes einzelne Detail näher darauf eingehen.
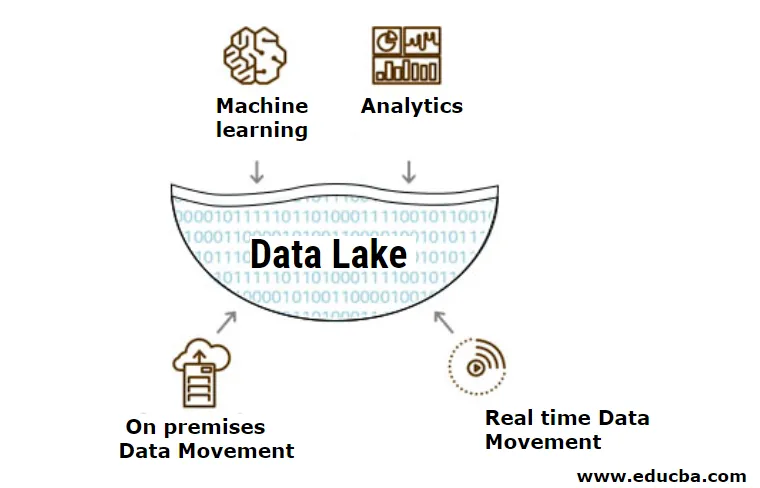
Was ist Data Lake?
Ein Data Lake ist eine Art Speicher-Repository, das nur aus Rohdaten in Form eines strukturierten, halbstrukturierten und unstrukturierten Formats besteht. Der Data Lake wird hauptsächlich von Data Scientists und Machine Learning Engineers verwendet, um Fragen zu beantworten, die noch nicht beantwortet wurden, oder um eine Frage zu erstellen, die noch nicht bekannt ist. Es enthält einen riesigen Datenpool mit unterschiedlichen Typen, und wenn sie integriert werden, erweisen sie sich als sehr nützlich für die prädiktive Modellierung, die hauptsächlich zum Erstellen von Modellen für maschinelles Lernen verwendet wird.
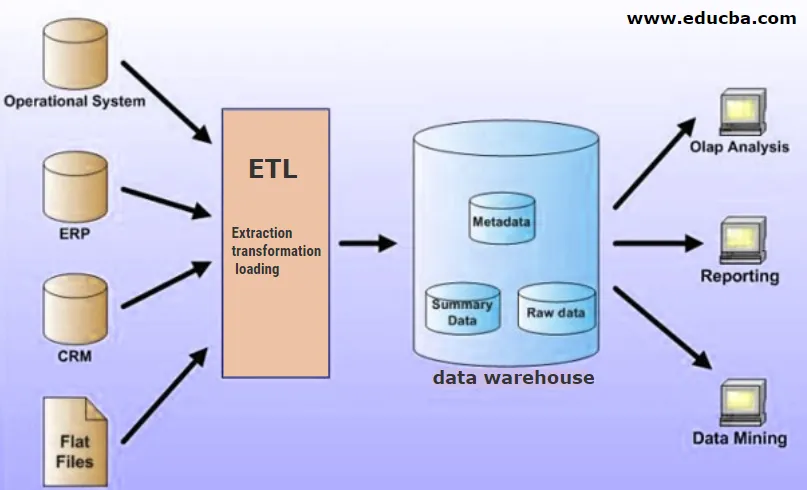
Was ist ein Data Warehouse?
Ein Data Warehouse ist ein zentraler Ort zum Speichern der transformierten Daten, die in ein strukturiertes Format umgewandelt wurden, bevor sie im Data Warehouse gespeichert werden. Ein Data Warehouse kann Daten aus mehreren Datenquellen enthalten, die mithilfe des ETL-Prozesses in das Warehouse geladen und dann für Business Intelligence-Zwecke verwendet werden.
Head to Head Vergleich zwischen Data Lake und Data Warehouse (Infografik)
Nachfolgend finden Sie die 14 wichtigsten Unterschiede zwischen Data Lake und Data Warehouse 
Hauptunterschiede
Im Folgenden sind die wichtigsten Unterschiede zwischen Data Lake und Data Warehouse aufgeführt:
- Es besteht aus unstrukturierten und strukturierten Daten von verschiedenen Plattformen wie Sensoren, Anwendungen und Websites usw. Es besteht hauptsächlich aus relationalen Daten von RDBMS, DBMS-Systemen und anderen operativen Datenbanken und Anwendungen.
- Data Lake ist eine Schema-on-Read-Verarbeitung. Das Data Warehouse ist eine Schema-on-Write-Verarbeitung.
- Es ist sehr wendig. Es ist weniger beweglich.
- Die Konfiguration ist einfach und kann sich an Änderungen anpassen. Es hat eine feste Konfiguration und ist sehr schwer zu ändern.
- Es wird hauptsächlich von KI-Wissenschaftlern und Experten für maschinelles Lernen verwendet. Es wird von Geschäftsleuten verwendet.
Vergleichstabelle zwischen Data Lake und Data Warehouse:
Lassen Sie uns den Hauptunterschied zwischen Data Lake und Data Warehouse diskutieren
| Eigenschaften | Data Lake | Data Warehouse |
| Lager | Die Daten werden in unformatierter Form in Data Lake gespeichert, und hier werden alle Daten unabhängig von der Datenquelle gespeichert. Sie werden nur bei Bedarf in andere Formen umgewandelt. | Data Warehouse besteht aus Daten, die aus Transaktions- und anderen Metriksystemen extrahiert werden. Hier sind die Daten nicht in Rohform und werden immer transformiert und sauber. |
| Verwendung und Zweck | Das Hauptziel von Data Lake sind Data Scientists, Big Data-Entwickler und Ingenieure für maschinelles Lernen, die tiefgreifende Analysen durchführen müssen, um Modelle für das Unternehmen zu erstellen, wie z. B. Vorhersagemodelle. | Das Hauptziel von Data Warehouse sind die operativen Benutzer, da diese Daten in einem strukturierten Format vorliegen und bereit sind, Berichte zu erstellen. Daher werden sie hauptsächlich für Business Intelligence verwendet. |
| Dateneingaben | Die Haupteingaben für data Lake sind alle Arten von Daten, z. B. strukturierte, halbstrukturierte und unstrukturierte Daten. Diese Daten befinden sich in der ursprünglichen Form in data Lake. | Die Haupteingaben für Data Warehouse sind strukturierte Daten, die von Transaktions- und Metriksystemen stammen und anschließend in Form von Schemata organisiert werden. |
| Datenqualität | Enthält Rohdaten, die kuratiert werden können oder nicht. | Es besteht aus kuratierten Daten, die zentralisiert sind und für Business Intelligence- und Analysezwecke verwendet werden können. |
| Normalisierung | Hier sind die Daten nicht normalisiert. | Denormalisierte Schemata |
| Geschichte | Die Technologien, die in Datenseen wie Hadoop und Machine Learning verwendet werden, sind im Vergleich zum Data Warehouse relativ neu. | Hier ist die Technologie, die für ein Data Warehouse verwendet wird, älter. |
| Zeitleiste der Daten | Ein Datensee kann alle Arten von Daten enthalten und unter Berücksichtigung von Vergangenheit, Gegenwart und Perspektiven verwendet werden. | In Bezug auf Data Warehouse wird hier der größte Teil der Zeit für die Analyse verschiedener Datenquellen aufgewendet. |
| Verarbeitungszeit | Hier ist die Verarbeitungszeit beim Analysieren und Abrufen von Ergebnissen aus Data Lake viel kürzer als die von Data Warehouse, da hier die Daten in Form von Rohdaten gespeichert werden und diese nicht im transformierten Format vorliegen und aufgrund dessen wir die Zeit verkürzen das könnte für die Umwandlung der Daten ausgegeben werden. Wir können die Daten einfach so wie sie sind abrufen, eine Grundreinigung durchführen und mit dem Bau unserer Modelle beginnen. | Im Fall von Data Warehouse ist der Zeitaufwand für die Verarbeitung im Vergleich zum Data Lake höher. Der Grund dafür ist, dass die Daten in einem Data Warehouse zuerst transformiert und dann analysiert werden müssen. |
| Lagerkosten | Die Kosten für die Speicherung in Data Lake-Technologien sind hier relativ niedriger als bei Data Warehouse und auch weniger zeitaufwendig. | Die Kosten für die Speicherung in Data Warehouse-Technologien sind im Vergleich zum Data Lake höher. Dies liegt daran, dass mehr Speicherplatz für die transformierten Daten benötigt wird, da zuerst die Rohdaten gespeichert und dann transformiert werden müssen, um verschiedene Felder gemäß der Struktur des Data Warehouse zuzuweisen. |
| Kompatibilität | Hier werden Daten immer in ihrem Rohformat gehalten und nur dann transformiert, wenn sie benötigt werden oder wenn sie zur Verwendung bereit sind. | Hier werden die Daten in einem transformierten Format gespeichert und es kann vorkommen, dass wir Probleme haben, wenn wir versuchen, Änderungen vorzunehmen. |
| Barrierefreiheit | Daten innerhalb des Datensees sind leicht zugänglich und können schnell aktualisiert werden. | Daten im Data Warehouse sind komplizierter und kosten mehr, wenn Änderungen vorgenommen werden sollen. Die Zugänglichkeit ist auch nur für autorisierte Benutzer eingeschränkt. |
| Position des Schemas | Das Schema wird meistens erstellt, nachdem die Daten gespeichert wurden. Das bringt hohe Agilität. | Hier wird das Schema meist vor dem Speichern der Daten erstellt. |
| Prozess der Verarbeitung | Der Data Lake verwendet den ELT-Prozess, dh Extrahieren, Laden und Transformieren. | Das Data Warehouse verwendet den traditionellen Ansatz von ETL, dh Extrahieren, Transformieren und Laden. |
| Leistungen | Data Lake führt zu neuen Erfindungen, da die Integration verschiedene Datentypen zusammenführt und auch Antworten auf viele unbeantwortete Fragen liefert. | Die meisten Benutzer der Organisation sind in operative Aktivitäten involviert, und Data Warehouse bietet eine solche hervorragende Plattform, um Berichte und Metriken auf Basis transformierter Daten zu erstellen. |
Fazit
In diesem Beitrag haben wir etwas über Data Lakes vs Data Warehouse gelernt. Wir gingen ebenfalls vor und verglichen beide anhand verschiedener Parameter. Dies sollte jedem Lernenden helfen, sich einen Überblick über die Technologien zu verschaffen, die Data Lake und Data Warehouse unterstützen.
Empfohlene Artikel
Dies war ein Leitfaden für den Hauptunterschied zwischen Data Lake und Data Warehouse. Hier haben wir die wichtigsten Unterschiede zwischen Data Lake und Data Warehouse mit Infografiken und Vergleichstabelle besprochen. Sie können sich auch die folgenden Artikel ansehen, um mehr zu erfahren -
- Scrum vs Waterfall - Top Unterschiede
- MySQL vs MySQLi - Welches ist besser?
- Mikroprozessor gegen Mikrocontroller
- Fragen im Vorstellungsgespräch zur Datenmodellierung