

Übersicht über Kafka-Anwendungen
Eines der Trendfelder in der IT-Branche ist Big Data, wo das Unternehmen mit einer großen Menge von Kundendaten umgeht und nützliche Erkenntnisse ableitet, die dem Unternehmen helfen und den Kunden einen besseren Service bieten. Eine der Herausforderungen besteht darin, diese großen Datenmengen zu verarbeiten und zur Analyse oder Verarbeitung von einem Ende zum anderen zu übertragen. Hier kommt Kafka (ein zuverlässiges Messaging-System) ins Spiel, das bei der Erfassung und dem Transport großer Datenmengen hilft in Echtzeit. Kafka wurde für verteilte Systeme mit hohem Durchsatz entwickelt und eignet sich gut für umfangreiche Nachrichtenverarbeitungsanwendungen. Kafka unterstützt viele der besten kommerziellen und industriellen Anwendungen von heute. Es besteht ein Bedarf an Kafka-Fachleuten mit starken Fähigkeiten und praktischem Wissen.
In diesem Artikel lernen wir Kafka, seine Funktionen und Anwendungsfälle kennen und lernen einige bemerkenswerte Anwendungen kennen, in denen es verwendet wird.
Was ist Kafka?
Apache Kafka wurde bei LinkedIn entwickelt und später zu einem Open-Source-Apache-Projekt. Apache Kafka ist ein schnelles, fehlertolerantes, skalierbares und verteiltes Messaging-System, das die Kommunikation zwischen zwei Entitäten ermöglicht, dh zwischen Produzenten (Generator der Nachricht) und Verbrauchern (Empfänger der Nachricht) unter Verwendung von nachrichtenbasierten Themen und bietet eine Plattform für die Verwaltung aller die Echtzeit-Daten-Feeds.
Die Merkmale, die Apache Kafka besser als andere Messagingsysteme machen und auf Echtzeitsysteme anwendbar sind, sind seine hohe Verfügbarkeit, die sofortige automatische Wiederherstellung nach Knotenausfällen und die Unterstützung der Nachrichtenübermittlung mit geringer Latenz. Diese Funktionen von Apache Kafka helfen bei der Integration in große Datensysteme und machen es zu einer idealen Komponente für die Kommunikation. 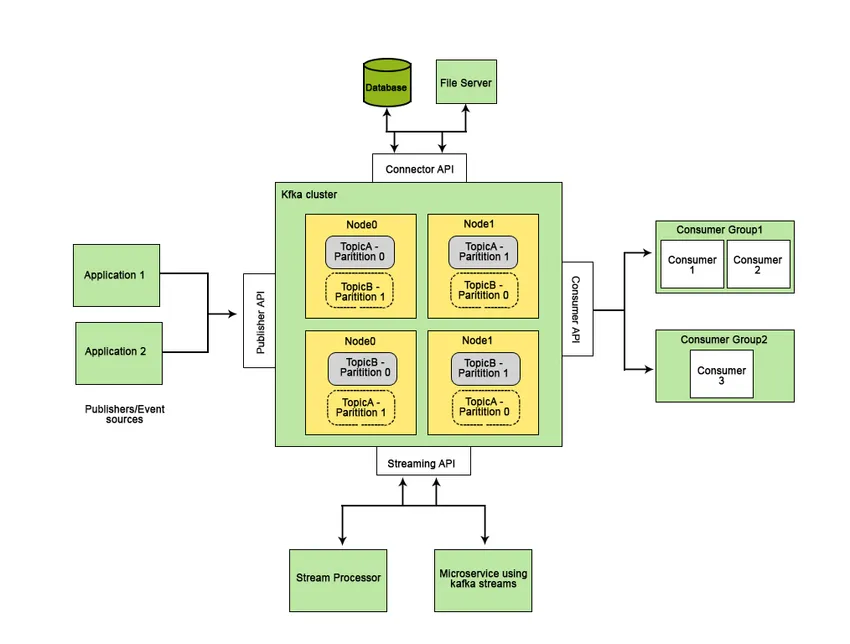
Top Kafka-Anwendungen
In diesem Abschnitt des Artikels werden einige beliebte und weit verbreitete Anwendungsfälle sowie einige reale Implementierungen von Kafka vorgestellt.
Real-Life-Anwendungen
1. Twitter: Stream-Verarbeitungsaktivität
Twitter ist eine Social-Networking-Plattform, die Storm-Kafka (Open-Source-Stream-Processing-Tool) als Teil ihrer Stream-Processing-Infrastruktur verwendet, in der Eingabedaten (Tweets) zur Aggregation, Transformation und Anreicherung für den weiteren Verbrauch oder zur Nachverfolgung verwendet werden Verarbeitungsaktivitäten.
2. LinkedIn: Stream Processing & Metrics
LinkedIn verwendet Kafka für das Streaming von Daten und für die Aktivität von Betriebsmetriken. LinkedIn verwendet Kafka für seine zusätzlichen Funktionen wie Newsfeed, um Nachrichten zu verarbeiten und die empfangenen Daten zu analysieren.
3. Netflix: Echtzeitüberwachung und Stream-Verarbeitung
Netflix verfügt über ein eigenes Ingestion-Framework, das Eingabedaten in AWS S3 speichert und mithilfe von Hadoop die Analyse von Videostreams, Benutzeroberflächenaktivitäten, Ereignissen zur Verbesserung der Benutzererfahrung und Kafka für die Echtzeit-Datenaufnahme über APIs ausführt.
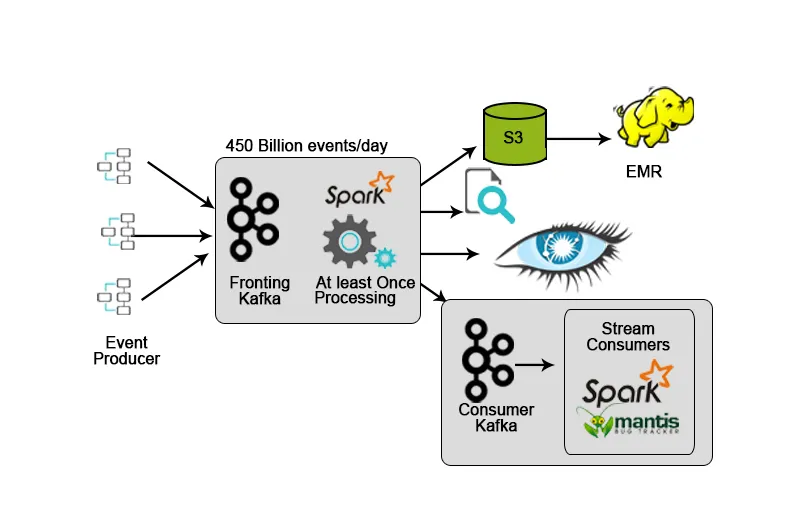
4. Hotstar: Stream-Verarbeitung
Hotstar stellte seine eigene Datenverwaltungsplattform Bifrost vor, auf der Kafka für das Streaming, Überwachen und Verfolgen von Zielen eingesetzt wird. Aufgrund seiner Skalierbarkeit, Verfügbarkeit und geringen Latenz war Kafka die ideale Wahl, um mit den Daten umzugehen, die die Hotstar-Plattform täglich oder zu besonderen Anlässen (Live-Streaming von Konzerten, Live-Sportmatches usw.) generiert das datenvolumen steigt deutlich an.
Apache Kafka wird die meiste Zeit als Baustein für die Entwicklung der Streaming-Datenarchitektur verwendet. Diese Art von Architektur wird in Anwendungen wie der Sammlung von Produkt- / Serverprotokollen, der Analyse von Clickstreams und der Ableitung von Informationen aus maschinengenerierten Daten verwendet.
Zusammen mit Kafka müssen wir jedoch zusätzliche Ressourcen oder Tools verwenden, um den erhaltenen Datenstrom in aussagekräftige Daten umzuwandeln, die dabei helfen, Erkenntnisse zu gewinnen, die für datengesteuerte Entscheidungen verwendet werden können. Beispielsweise müssen wir möglicherweise Erkenntnisse aus den Rohdaten von IoT-Geräten oder aus Daten von Social Media-Plattformen in Echtzeit generieren und einige Analysen oder Verarbeitungen durchführen und diese dem Unternehmen präsentieren, um bessere Entscheidungen zu treffen oder diese zu verbessern die Leistung ihrer Dienste.
Für diese Art von Anwendungsfällen möchten wir unsere Eingabedaten / Rohdaten in einen Datensee streamen, in dem wir unsere Daten speichern und die Datenqualität sicherstellen können, ohne die Leistung zu beeinträchtigen.
Eine andere Situation, in der wir möglicherweise Daten direkt von Kafka lesen, ist, wenn wir eine extrem niedrige End-to-End-Latenz benötigen, z. B. Daten an Echtzeitanwendungen weiterleiten.
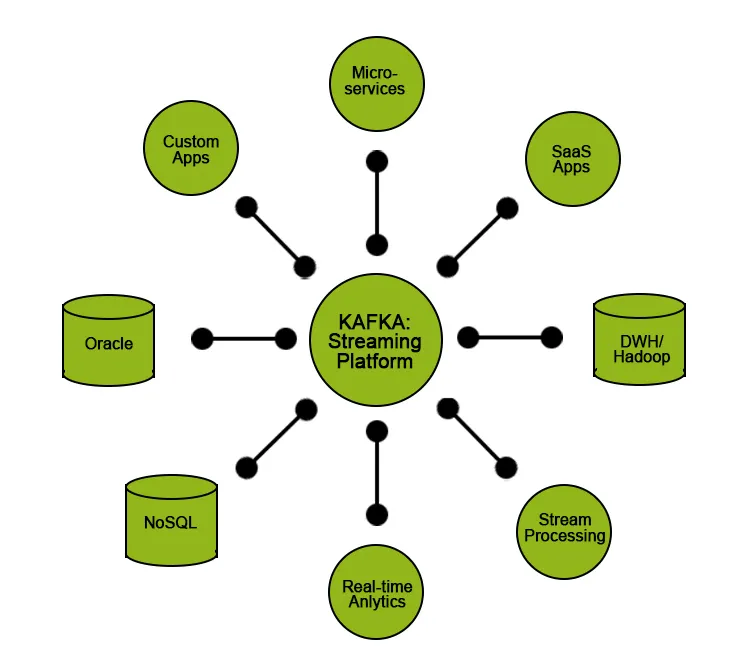
Kafka bietet seinen Benutzern bestimmte Funktionen:
- Daten veröffentlichen und abonnieren.
- Speichern Sie die Daten in der Reihenfolge, in der sie effizient generiert wurden.
- Echtzeit- / On-the-Fly-Verarbeitung von Daten.
Kafka wird meistens verwendet für:
- Implementierung von Streaming-Daten-Pipelines im laufenden Betrieb, die zuverlässig Daten zwischen zwei Entitäten im System abrufen.
- Implementierung von On-the-Fly-Streaming-Anwendungen, die Datenströme transformieren, bearbeiten oder verarbeiten.
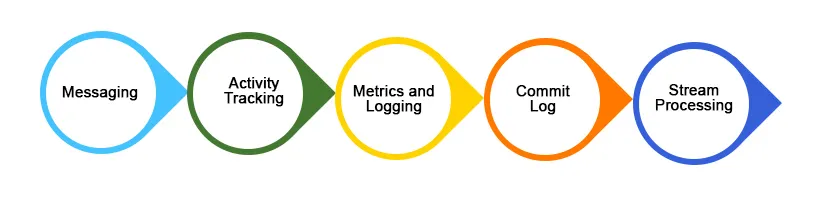
Anwendungsfälle
Im Folgenden sind einige weit verbreitete Anwendungsfälle der Kafka-Anwendung aufgeführt:
1. Messaging
Kafka funktioniert besser als andere herkömmliche Messagingsysteme wie ActiveMQ, RabbitMQ usw. Im Vergleich dazu bietet Kafka einen besseren Durchsatz, integrierte Partitionsfunktionen, Replikations- und Fehlertoleranzfunktionen und ist somit ein besseres Messagingsystem für Verarbeitungsanwendungen im großen Maßstab .
2. Website Activity Tracking
Benutzeraktivitäten (Seitenaufrufe, Suchvorgänge oder ausgeführte Aktionen) können zur Echtzeitüberwachung oder -analyse über Kafka nachverfolgt und eingespeist werden. Mithilfe von Kafka können diese Daten für die spätere Verarbeitung oder Bearbeitung in Hadoop oder Data Warehouse gespeichert werden. Activity Tracking generiert eine große Datenmenge, die ohne Datenverlust an den gewünschten Ort übertragen werden muss.
3. Protokollaggregation
Bei der Protokollaggregation werden physische Protokolldateien von verschiedenen Servern einer Anwendung in einem einzigen Repository (Dateiserver oder HDFS) zur Verarbeitung gesammelt / zusammengeführt. Kafka bietet im Vergleich zu Flume eine gute Leistung und eine geringere End-to-End-Latenz.

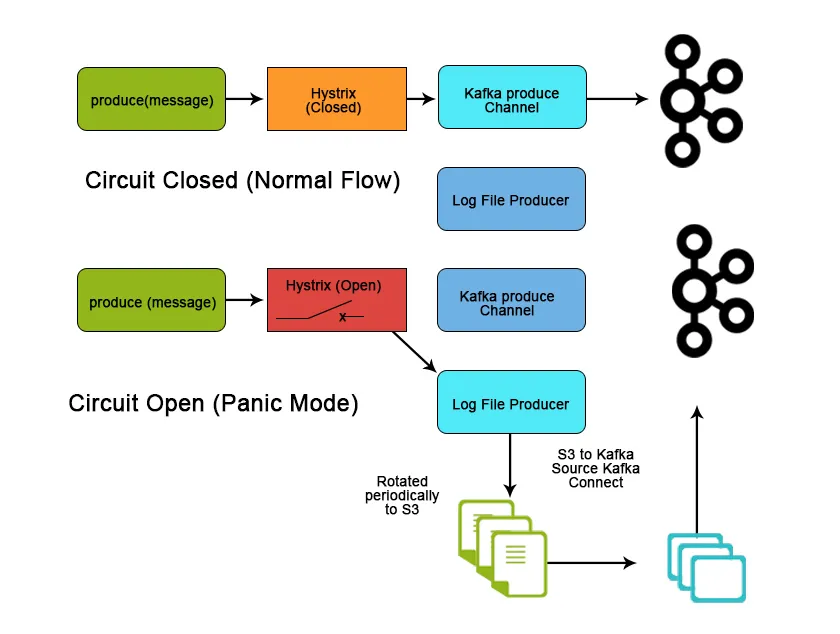
Fazit
Kafka wird häufig im Big-Data-Bereich verwendet, um große Datenmengen sehr schnell zu erfassen und zu übertragen. Dies liegt an den Leistungsmerkmalen und Funktionen, die zur Erzielung von Skalierbarkeit, Zuverlässigkeit und Nachhaltigkeit beitragen. In diesem Artikel haben wir die Funktionen, Anwendungsfälle und Anwendungen von Apache Kafka erläutert und erläutert, warum Apache Kafka ein besseres Tool für das Streaming von Daten ist.
Empfohlene Artikel
Dies ist eine Anleitung zu Kafka Applications. Hier diskutieren wir, was Kafka ist, zusammen mit Top-Anwendungen von Kafka, die weithin implementierte Anwendungsfälle und einige Real-Life-Implementierungen umfassen. Sie können sich auch die folgenden Artikel ansehen, um mehr zu erfahren.
- Was ist Kafka?
- Wie installiere ich Kafka?
- Fragen in Vorstellungsgesprächen bei Kafka
- Apache Kafka gegen Flume
- Top 8 Geräte des IoT, die Sie kennen sollten
- Kafka vs Kinesis | Unterschiede zu Infografiken
- Verschiedene Arten von Kafka-Werkzeugen mit Komponenten
- Lernen Sie die wichtigsten Unterschiede zwischen ActiveMQ und Kafka kennen