

Überblick über die Data Mining-Architektur
Das Data Mining ist die Methode zum Auffinden und Erforschen der grundlegenden oder fortgeschrittenen Muster in einem komplizierten Satz großer Datensätze, wobei die Methoden an der Schnittstelle von Statistik, maschinellem Lernen und auch Datenbanksystemen angewendet werden. Man kann von einem interdisziplinären Bereich der Statistik und der Informatik sprechen, in dem das Ziel darin besteht, die Informationen mit intelligenten Methoden und Techniken aus einem bestimmten Datensatz durch Extraktion und damit Umwandlung der Daten zu extrahieren. Die Datenverwaltungsaktivitäten und Datenvorverarbeitungsaktivitäten sowie Schlussfolgerungsüberlegungen werden ebenfalls berücksichtigt. In diesem Artikel werden wir uns eingehend mit der Architektur des Data Mining befassen.
Data Mining-Architektur
Beim Data Mining wird aus einer Menge großer Datenmengen interessantes Wissen extrahiert, das dann in vielen Datenquellen wie Dateisystemen, Data Warehouses und Datenbanken gespeichert wird. Die Hauptkomponenten der Data Mining-Architektur umfassen:
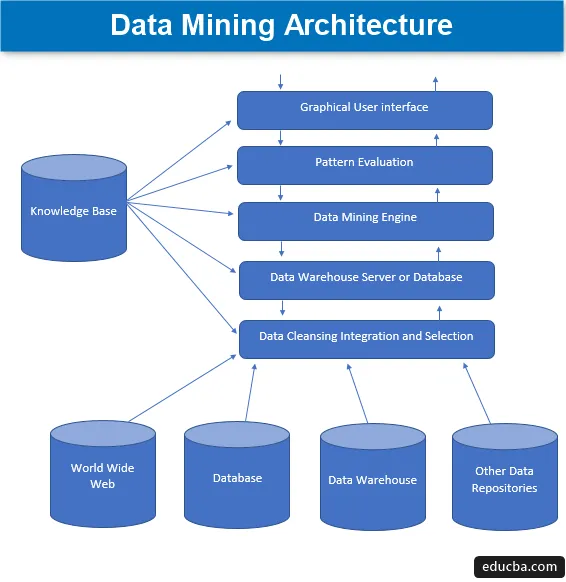
1. Datenquellen
Eine Vielzahl vorhandener Dokumente wie Data Warehouse, Datenbank, WWW oder im Volksmund World Wide Web, die zu den eigentlichen Datenquellen werden. In den meisten Fällen ist es auch so, dass die Daten in keiner dieser goldenen Quellen vorhanden sind, sondern nur in Form von Textdateien, einfachen Dateien oder Sequenzdateien oder Tabellenkalkulationen, und dann müssen die Daten in sehr kurzer Zeit verarbeitet werden Ähnlich wie bei der Verarbeitung von Daten, die aus goldenen Quellen stammen. Der größte Teil der Daten wird heute aus dem Internet oder dem World Wide Web empfangen, da alles, was heute im Internet vorhanden ist, Daten in irgendeiner Form sind, die irgendeine Form von Informationsspeichereinheiten bilden.
Bevor die Daten verarbeitet werden, müssen die verschiedenen Prozesse bereinigt, integriert und ausgewählt werden, bevor die Daten schließlich an die Datenbank oder einen der EDW-Server (Enterprise Data Warehouse) übergeben werden. Die größte Herausforderung, die mit diesem Datensatz zuweilen verbunden ist, sind unterschiedliche Quellenebenen und eine Vielzahl von Datenformaten, die die Datenkomponenten bilden. Daher können die Daten nicht direkt in ihrem naiven Zustand für die Verarbeitung verwendet, sondern in einer viel benutzerfreundlicheren Weise verarbeitet, transformiert und bearbeitet werden. Auf diese Weise wird auch die Zuverlässigkeit und Vollständigkeit der Daten sichergestellt. Der primäre Schritt besteht also darin, Daten zu sammeln, zu bereinigen und zu integrieren und zu veröffentlichen, dass nur die relevanten Daten weitergeleitet werden. All diese Aktivitäten sind Teil eines separaten Satzes von Werkzeugen und Techniken.
2. Data Warehouse Server oder Datenbank
Der Datenbankserver ist der tatsächliche Bereich, in dem die Daten enthalten sind, sobald sie aus einer unterschiedlichen Anzahl von Datenquellen empfangen wurden. Der Server enthält den tatsächlichen Datensatz, der zur Verarbeitung bereit ist, und daher verwaltet der Server den Datenabruf. All diese Aktivitäten basieren auf der Anfrage nach Data Mining der Person.
3. Data Mining Engine
Im Falle von Data Mining bildet die Engine die Kernkomponente und ist der wichtigste Teil oder die treibende Kraft, die alle Anforderungen verarbeitet und verwaltet und zur Aufnahme einer Reihe von Modulen verwendet wird. Die Anzahl der vorhandenen Module umfasst Bergbauaufgaben wie Klassifikationstechnik, Assoziationstechnik, Regressionstechnik, Charakterisierung, Vorhersage und Clustering, Zeitreihenanalyse, naive Bayes, Support-Vektor-Maschinen, Ensemble-Methoden, Boosting- und Bagging-Techniken, Zufallswälder, Entscheidungsbäume. etc.
4. Musterbewertungsmodule
Diese Bewertungstechnik der Module ist hauptsächlich für die Messung der Interessiertheit all jener Muster verantwortlich, die zur Berechnung des Grundpegels des Schwellenwerts verwendet werden, und wird auch zur Interaktion mit der Data Mining-Engine verwendet, um die Bewertung anderer Module zu koordinieren. Alles in allem besteht der Hauptzweck dieser Komponente darin, nach allen interessanten und verwendbaren Mustern Ausschau zu halten und diese zu suchen, um die Daten von vergleichsweise besserer Qualität zu erhalten.
5. Grafische Benutzeroberfläche
Wenn die Daten mit den Motoren und unter verschiedenen Musterauswertungen von Modulen kommuniziert werden, wird es eine Notwendigkeit, mit den verschiedenen vorhandenen Komponenten zu interagieren und sie benutzerfreundlicher zu gestalten, so dass die effiziente und effektive Verwendung aller vorhandenen Komponenten erfolgen kann und daher Es wird eine grafische Benutzeroberfläche benötigt, die im Volksmund als GUI bezeichnet wird.
Auf diese Weise wird ein Kontaktgefühl zwischen dem Benutzer und dem Data Mining-System hergestellt, wodurch Benutzer effizient und einfach auf das System zugreifen und es verwenden können, ohne dass dabei Komplexität entsteht. Dies ist eine Form der Abstraktion, bei der dem Benutzer nur die relevanten Komponenten angezeigt werden und alle Komplexitäten und Funktionen, die für den Aufbau des Systems verantwortlich sind, der Einfachheit halber ausgeblendet sind. Immer wenn der Benutzer eine Abfrage sendet, interagiert das Modul mit der Gesamtmenge eines Data-Mining-Systems, um eine relevante Ausgabe zu erstellen, die dem Benutzer auf eine viel verständlichere Weise leicht angezeigt werden kann.
6. Wissensdatenbank
Dies ist die Komponente, die die Grundlage des gesamten Data Mining-Prozesses bildet, da sie bei der Steuerung der Suche oder bei der Bewertung der Interessantheit der gebildeten Muster hilfreich ist. Diese Wissensdatenbank besteht aus Benutzerüberzeugungen und den Daten, die aus Benutzererfahrungen stammen und die wiederum für den Data Mining-Prozess hilfreich sind. Die Engine bezieht ihre Eingaben möglicherweise aus der erstellten Wissensdatenbank und liefert dadurch effizientere, genauere und zuverlässigere Ergebnisse.
Data Mining ist heute eine der wichtigsten Techniken, die sich mit Datenmanagement und Datenverarbeitung befassen und das Rückgrat jeder Organisation bilden. Die Analyse von Daten in jeder Organisation wird zu fruchtbaren Ergebnissen führen. Jede Komponente der Data Mining-Technik und -Architektur hat ihre eigene Art, Verantwortlichkeiten zu erfüllen und das Data Mining effizient abzuschließen. Die verschiedenen Module sind für eine korrekte Interaktion erforderlich, um ein wertvolles Ergebnis zu erzielen und den komplexen Vorgang des Data Mining erfolgreich abzuschließen, indem dem Unternehmen die richtigen Informationen zur Verfügung gestellt werden.
Empfohlene Artikel
Dies war ein Leitfaden für die Data Mining-Architektur. Hier diskutieren wir die Hauptkomponenten der Data Mining-Architektur. Sie können auch unsere anderen Artikelvorschläge durchgehen, um mehr zu erfahren -
- Data Mining-Tool
- Vorteile von Data Mining
- Was ist Clustering in Data Mining?
- HTML5 Interview Fragen und Antworten
- Meist verwendete Techniken des Ensemble-Lernens
- Algorithmen von Modellen im Data Mining