
Einführung in die Poisson-Regression in R
Die Poisson-Regression ist eine Art der Regression, die der multiplen linearen Regression ähnelt, mit der Ausnahme, dass die Antwort oder die abhängige Variable (Y) eine Zählvariable ist. Die abhängige Variable folgt der Poisson-Verteilung. Der Prädiktor oder die unabhängigen Variablen können kontinuierlicher oder kategorialer Natur sein. In gewisser Weise ähnelt es der logistischen Regression, die auch eine diskrete Antwortvariable hat. Das vorherige Verständnis der Poisson-Verteilung und ihrer mathematischen Form ist sehr wichtig, um sie für die Vorhersage zu nutzen. In R kann die Poisson-Regression sehr effektiv implementiert werden. R bietet eine umfassende Reihe von Funktionalitäten für seine Implementierung.
Implementierung der Poisson-Regression
Wir werden nun verstehen, wie das Modell angewendet wird. Der folgende Abschnitt enthält eine schrittweise Anleitung dazu. Für diese Demonstration betrachten wir den "Gala" -Datensatz aus dem "Fern" -Paket. Es bezieht sich auf die Artenvielfalt auf den Galapagos-Inseln. Der Datensatz enthält insgesamt 7 Variablen. Wir verwenden die Poisson-Regression, um eine Beziehung zwischen der Anzahl der Pflanzenarten (Species) und anderen Variablen im Datensatz zu definieren.
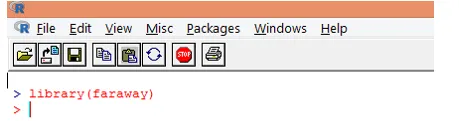
1. Laden Sie zuerst das Paket „faraway“. Falls das Paket nicht vorhanden ist, laden Sie es mit der Funktion install.packages () herunter.
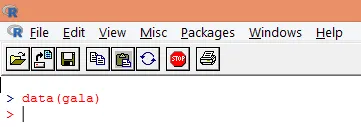
2. Laden Sie nach dem Laden des Pakets den „Gala“ -Datensatz mit der Funktion data () in R (siehe unten).
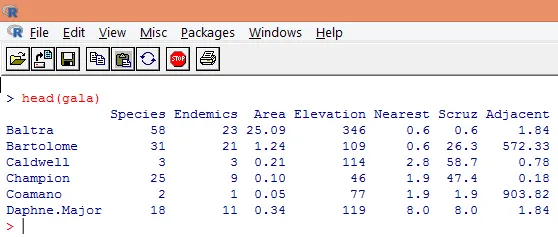
3. Die geladenen Daten sollten visualisiert werden, um die Variable zu untersuchen und festzustellen, ob Unstimmigkeiten vorliegen. Mit der Funktion head () können wir entweder die gesamten Daten oder nur die ersten Zeilen visualisieren, wie im folgenden Screenshot gezeigt.
4. Um einen besseren Einblick in das Dataset zu erhalten, können wir die Hilfefunktionen in R wie folgt verwenden. Es generiert die R-Dokumentation, wie im folgenden Screenshot gezeigt.


5. Wenn wir den Datensatz wie in den vorhergehenden Schritten beschrieben untersuchen, können wir feststellen, dass Species eine Antwortvariable ist. Wir werden nun eine grundlegende Zusammenfassung der Prädiktorvariablen untersuchen.
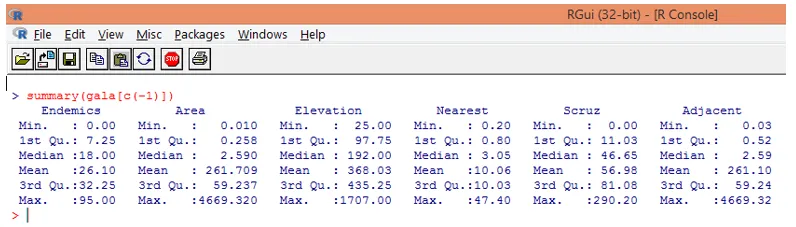
Beachten Sie, wie oben zu sehen ist, dass wir die Variable Species ausgeschlossen haben. Die Zusammenfassungsfunktion gibt uns grundlegende Einblicke. Betrachten Sie einfach die Medianwerte für jede dieser Variablen, und wir können feststellen, dass zwischen der ersten Hälfte und der zweiten Hälfte ein großer Unterschied in Bezug auf den Wertebereich besteht, z. B. für die Bereichsvariable beträgt der Medianwert 2, 59, aber das Maximum Wert ist 4669.320.
6. Nachdem wir mit der grundlegenden Analyse fertig sind, erstellen wir ein Histogramm für Species, um zu überprüfen, ob die Variable der Poisson-Verteilung folgt. Dies ist unten dargestellt.

Mit dem obigen Code wird ein Histogramm für die Variable Species zusammen mit einer überlagerten Dichtekurve erstellt.
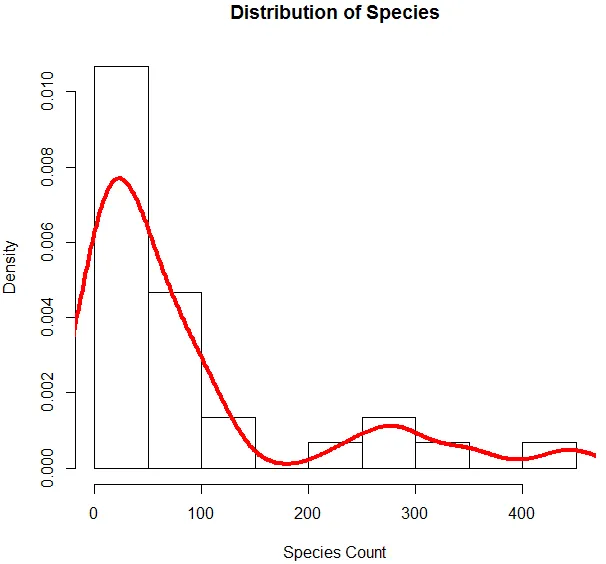
Die obige Visualisierung zeigt, dass Species einer Poisson-Verteilung folgt, da die Daten rechtwinklig sind. Wir können auch einen Boxplot generieren, um einen besseren Einblick in das Verteilungsmuster zu erhalten, wie unten gezeigt.
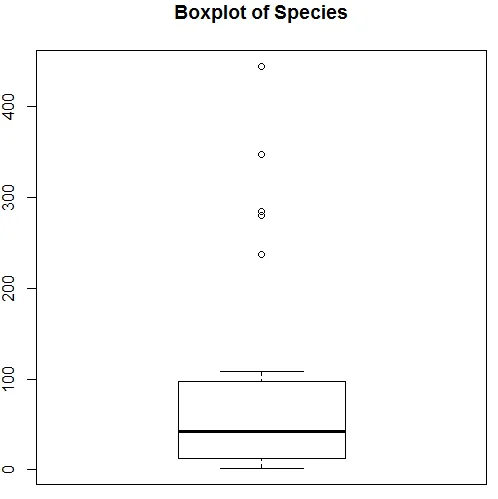
7. Nachdem Sie die vorläufige Analyse durchgeführt haben, wenden Sie die unten gezeigte Poisson-Regression an
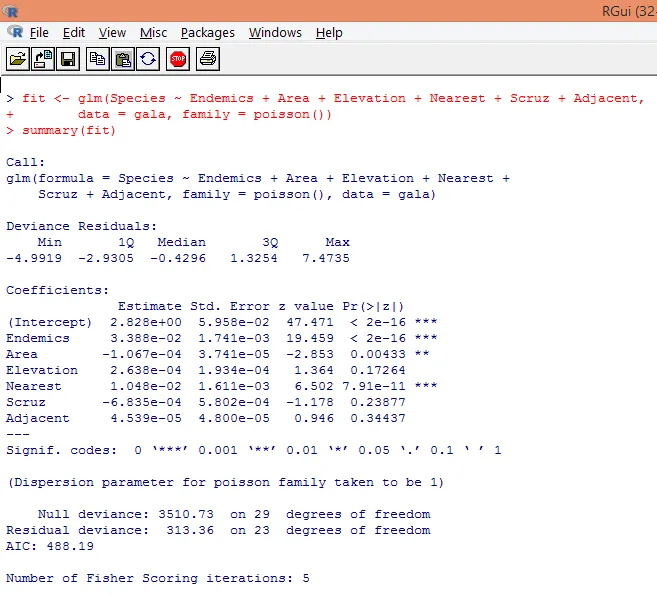
Basierend auf der obigen Analyse stellen wir fest, dass die Variablen Endemics, Area und Nearest signifikant sind und nur ihre Einbeziehung ausreicht, um das richtige Poisson-Regressionsmodell zu erstellen.
8. Wir erstellen ein modifiziertes Poisson-Regressionsmodell, das nur drei Variablen berücksichtigt. Endemics, Area und Nearest. Mal sehen, welche Ergebnisse wir bekommen.
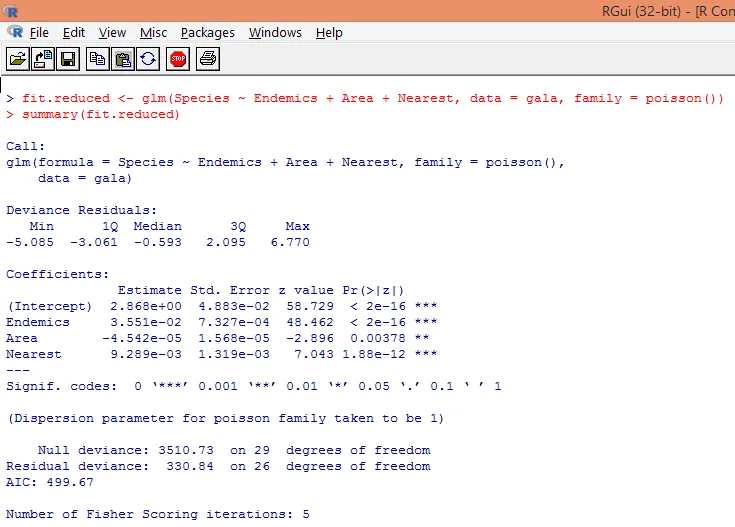
Die Ausgabe erzeugt Abweichungen, Regressionsparameter und Standardfehler. Wir können sehen, dass jeder der Parameter bei p <0, 05 signifikant ist.
9. Der nächste Schritt ist die Interpretation der Modellparameter. Die Modellkoeffizienten können entweder durch Untersuchen der Koeffizienten in der obigen Ausgabe oder durch Verwenden der Funktion coef () erhalten werden.
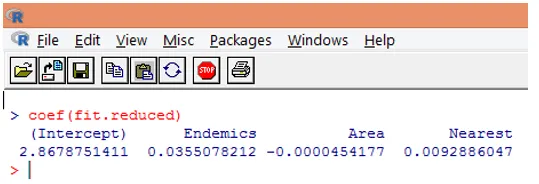
Bei der Poisson-Regression wird die abhängige Variable als das Protokoll des bedingten Mittelwerts (l) modelliert. Der Regressionsparameter von 0, 0355 für Endemiten zeigt an, dass ein Anstieg der Variablen um eine Einheit mit einem Anstieg der logarithmischen mittleren Anzahl von Arten um 0, 04 verbunden ist, wobei andere Variablen konstant bleiben. Der Achsenabschnitt ist eine logarithmische mittlere Anzahl von Arten, wenn jeder der Prädiktoren gleich Null ist.
10. Es ist jedoch viel einfacher, die Regressionskoeffizienten in der ursprünglichen Skala der abhängigen Variablen zu interpretieren (Anzahl der Arten, anstatt Anzahl der Arten zu protokollieren). Die Potenzierung der Koeffizienten ermöglicht eine einfache Interpretation. Dies geschieht wie folgt.
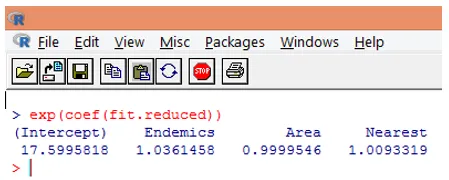
Aus den obigen Erkenntnissen kann man schließen, dass eine Flächenvergrößerung die erwartete Artenzahl um 0, 9999 multipliziert und eine Einheitsvergrößerung der endemischen Arten, die durch Endemics repräsentiert werden, die Artenzahl um 1, 0361 multipliziert. Der wichtigste Aspekt der Poisson-Regression ist, dass potenzierte Parameter einen multiplikativen und keinen additiven Effekt auf die Antwortvariable haben.
11. Mit den obigen Schritten erhielten wir ein Poisson-Regressionsmodell zur Vorhersage der Anzahl der Pflanzenarten auf den Galapagos-Inseln. Es ist jedoch sehr wichtig, auf Überdispersion zu prüfen. Bei der Poisson-Regression sind Varianz und Mittel gleich.
Überdispersion tritt auf, wenn die beobachtete Varianz der Antwortvariablen größer ist als durch die Poisson-Verteilung vorhergesagt. Die Analyse der Überdispersion wird wichtig, da dies bei Zähldaten häufig vorkommt und sich negativ auf die Endergebnisse auswirken kann. In R kann die Überdispersion mit dem Paket "qcc" analysiert werden. Die Analyse ist unten dargestellt.
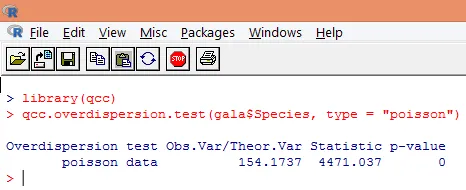
Der obige signifikante Test zeigt, dass der p-Wert kleiner als 0, 05 ist, was stark auf das Vorhandensein einer Überdispersion hindeutet. Wir werden versuchen, ein Modell mit der Funktion glm () anzupassen, indem wir family = "Poisson" durch family = "quasipoisson" ersetzen. Dies ist unten dargestellt.
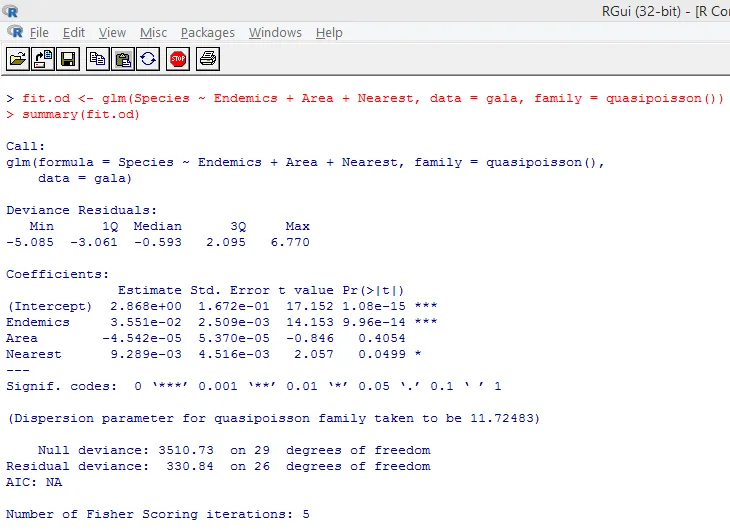
Wenn wir die obigen Ergebnisse genau untersuchen, können wir feststellen, dass die Parameterschätzungen im Quasi-Poisson-Ansatz mit denen des Poisson-Ansatzes identisch sind, obwohl die Standardfehler für beide Ansätze unterschiedlich sind. Darüber hinaus ist in diesem Fall für Fläche der p-Wert größer als 0, 05, was auf einen größeren Standardfehler zurückzuführen ist.
Bedeutung der Poisson-Regression
- Die Poisson-Regression in R ist nützlich für die korrekte Vorhersage der diskreten / Zählvariablen.
- Es hilft uns, jene erklärenden Variablen zu identifizieren, die einen statistisch signifikanten Effekt auf die Antwortvariable haben.
- Die Poisson-Regression in R eignet sich am besten für Ereignisse „seltener“ Natur, da sie im Gegensatz zu häufigen Ereignissen, die normalerweise einer Normalverteilung folgen, einer Poisson-Verteilung folgen.
- Es eignet sich für Anwendungen in Fällen, in denen die Antwortvariable eine kleine Ganzzahl ist.
- Es hat breite Anwendungen, da die Vorhersage diskreter Variablen in vielen Situationen entscheidend ist. In der Medizin kann es verwendet werden, um die Auswirkungen des Arzneimittels auf die Gesundheit vorherzusagen. Es wird häufig für Überlebensanalysen wie den Tod biologischer Organismen, das Versagen mechanischer Systeme usw. verwendet.
Fazit
Die Poisson-Regression basiert auf dem Konzept der Poisson-Verteilung. Es ist eine weitere Kategorie der Regressionstechniken, die die Eigenschaften sowohl linearer als auch logistischer Regressionen kombiniert. Im Gegensatz zur logistischen Regression, die nur eine binäre Ausgabe generiert, wird sie jedoch zur Vorhersage einer diskreten Variablen verwendet.
Empfohlene Artikel
Dies ist eine Anleitung zur Poisson-Regression in R. Hier diskutieren wir die Einführung zur Implementierung der Poisson-Regression und die Bedeutung der Poisson-Regression. Sie können auch unsere anderen Artikelvorschläge durchgehen, um mehr zu erfahren.
- GLM in R
- Zufallszahlengenerator in R
- Regressionsformel
- Logistische Regression in R
- Lineare Regression vs Logistische Regression | Top Unterschiede